ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
Introducción a Youtube • Chat de Discord • Documentación completa
Instalar UStore es muy sencillo y su uso es tan simple como un dict de Python.
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi' Acabamos de crear una base de datos transaccional integrada en memoria y agregamos una entrada en su colección main . ¿Preferirías esos datos en el disco? Cambia una línea.
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )¿Preferiría conectarse a un servidor USore remoto? ¡UStore viene con una interfaz Apache Arrow Flight RPC!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' ) ¿Está almacenando MultiDiGraph similar a NetworkX? ¿O DataFrame tipo Pandas?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1Las llamadas a funciones pueden parecer idénticas, pero la implementación subyacente puede abordar cientos de terabytes de datos ubicados en algún lugar de la memoria persistente de una máquina remota.
¿Alguien más está actualizando esas colecciones simultáneamente? ¡Agrupe sus operaciones para garantizar la coherencia!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )Hasta ahora sólo hemos cubierto la punta de la UStore. Puedes usarlo para...
Pero UStore puede más. Aquí está el mapa:
## Uso básico
UStore está pensado no solo como una base de datos, sino como un conjunto de herramientas para "construir su base de datos" y un estándar abierto para bases de datos NoSQL potencialmente transaccionales, que define interfaces binarias de copia cero para operaciones de "Crear, Leer, Actualizar, Eliminar", o CRUD para abreviar.
Unos pocos encabezados C99 simples pueden vincular casi cualquier motor de almacenamiento subyacente a numerosos controladores de lenguaje de alto nivel, extendiendo su soporte para valores de cadenas binarias a gráficos, documentos de esquema flexible y otras modalidades, con el objetivo de reemplazar MongoDB, Neo4J, Pinecone y ElasticSearch. con un único sistema ACID-transaccional.
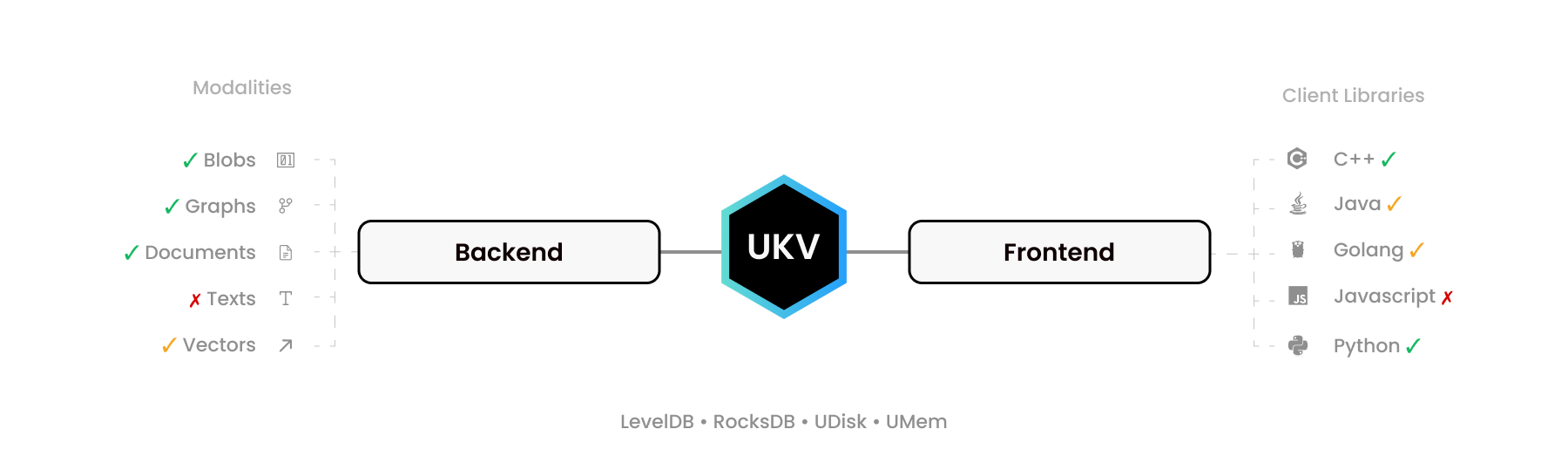
Redis, por ejemplo, proporciona a RediSearch, RedisJSON y RedisGraph objetivos similares. UStore lo hace mejor, permitiéndole agregar sus almacenes de valores clave (KVS) favoritos, integrados, independientes o fragmentados, como FoundationDB, multiplicando su funcionalidad.
Los objetos binarios grandes se pueden colocar dentro de UStore. El rendimiento variará enormemente según la tecnología subyacente utilizada. El UCSet en memoria será el más rápido, pero el menos adecuado para objetos más grandes. El UDisk persistente, cuando se configura correctamente, puede omitir por completo el kernel de Linux, incluida la capa del sistema de archivos, dirigiéndose directamente a los dispositivos de bloque.
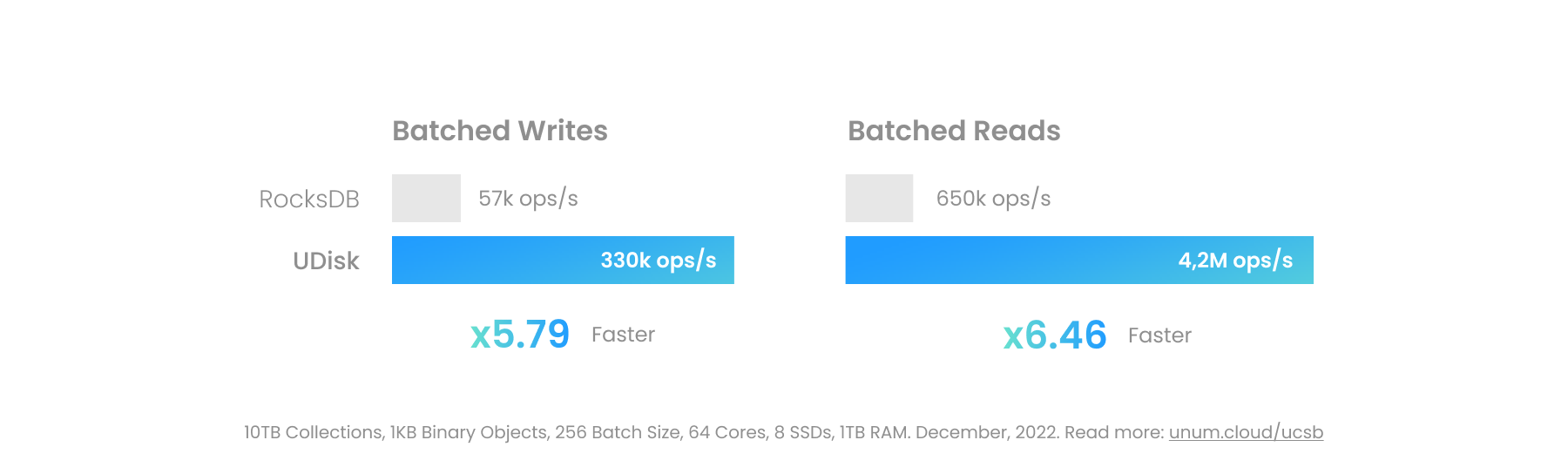
Las E/S persistentes modernas en servidores de alta gama pueden superar los 100 GB/s por socket cuando se basan en controladores de espacio de usuario como SPDK. Esto se acerca al rendimiento real de la RAM de alta gama y desbloquea casos de uso nuevos y poco comunes para las bases de datos. Ahora se puede colocar un archivo de vídeo de tamaño Gigabyte en una base de datos transaccional ACID, justo al lado de sus metadatos, en lugar de utilizar un almacén de objetos separado, como MinIO.
JSON es el formato de documento más utilizado en la actualidad. Las colecciones de documentos de USore admiten JSON, así como MessagePack y BSON, utilizados por MongoDB.

UStore aún no escala horizontalmente, pero proporciona un rendimiento de un solo nodo mucho mayor y tiene una escalabilidad vertical casi lineal en sistemas de muchos núcleos gracias a las bibliotecas de código abierto simdjson y yyjson . Además, para interactuar con los datos, no necesita un lenguaje de consulta personalizado como MQL. En lugar de eso, damos prioridad a los estándares RFC abiertos para evitar realmente los bloqueos de proveedores:
Las bases de datos de Graph modernas, como Neo4J, luchan con grandes cargas de trabajo. Requieren demasiada RAM y sus algoritmos observan los datos una entrada a la vez. Optimizamos en ambos frentes:
Los almacenes de características y bases de datos de vectores, como Pinecone, Milvus y USearch, proporcionan índices independientes para la búsqueda de vectores. UStore lo implementa como una modalidad separada, a la par de Documentos y Gráficos. Características:
UStore para Python y C++ se ven muy diferentes. Nuestro SDK de Python imita otras bibliotecas de Python: Pandas y NetworkX. De manera similar, la biblioteca C++ proporciona la interfaz que esperan los desarrolladores de C++.
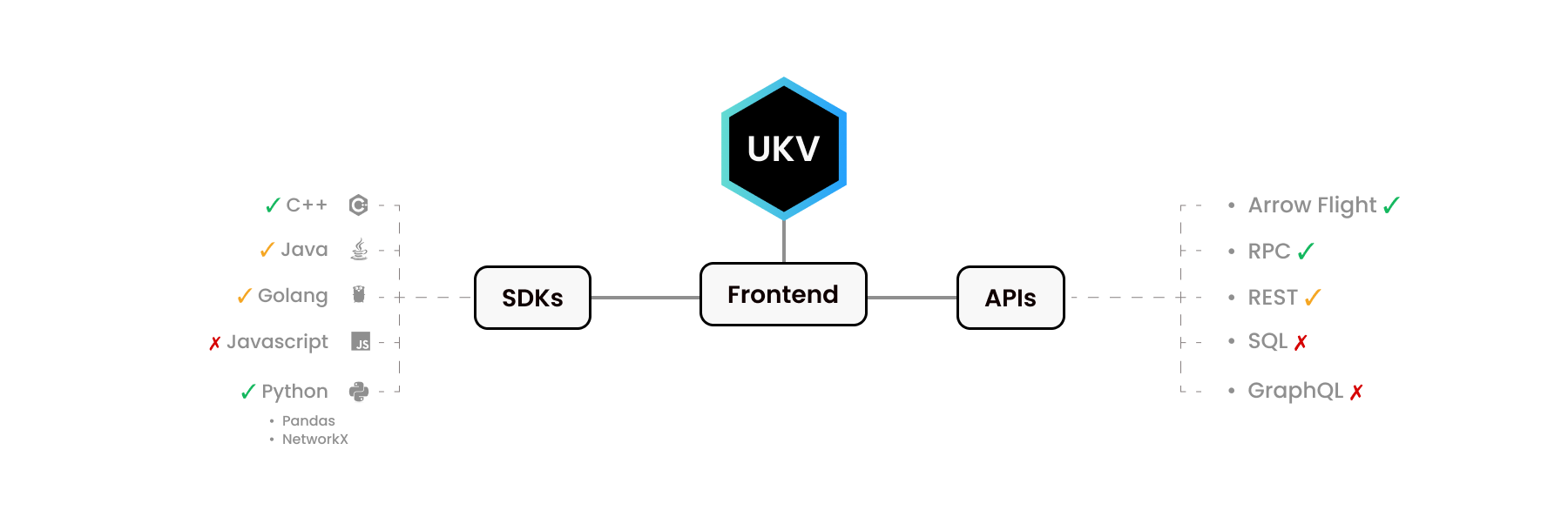
Como sabemos, las personas utilizan diferentes idiomas para diferentes propósitos. Algunas funciones de nivel C no están implementadas en algunos idiomas. Ya sea porque no había demanda o porque aún no hemos llegado a ello.
| Nombre | Tramitar | Colecciones | Lotes | Documentos | Graficos | Copias |
|---|---|---|---|---|---|---|
| Estándar C99 | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| SDK de C++ | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| SDK de Python | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| SDK de GoLang | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| SDK de Java | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| API de vuelo de flecha | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
¡Algunas interfaces aquí tienen ecosistemas completos a su alrededor! Apache Arrow Flight API, por ejemplo, tiene sus propios controladores para C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby y Rust.
Los siguientes motores se pueden utilizar casi indistintamente. Históricamente, LevelDB fue el primero. Luego, RocksDB mejoró la funcionalidad y el rendimiento. Ahora sirve como base para la mitad de las nuevas empresas de DBMS.
| NivelDB | RocasDB | disco U | UCSet | |
|---|---|---|---|---|
| Velocidad | 1x | 2x | 10x | 30x |
| Persistente | ✓ | ✓ | ✓ | ✗ |
| Transaccional | ✗ | ✓ | ✓ | ✓ |
| Soporte de dispositivo de bloque | ✗ | ✗ | ✓ | ✗ |
| Cifrado | ✗ | ✗ | ✓ | ✗ |
| Relojes | ✗ | ✓ | ✓ | ✓ |
| Instantáneas | ✓ | ✓ | ✓ | ✗ |
| Muestreo aleatorio | ✗ | ✗ | ✓ | ✓ |
| Enumeración masiva | ✗ | ✗ | ✓ | ✓ |
| Colecciones nombradas | ✗ | ✓ | ✓ | ✓ |
| Código abierto | ✓ | ✓ | ✗ | ✓ |
| Compatibilidad | Cualquier | Cualquier | linux | Cualquier |
| mantenedor | Unum | Unum |
UCSet y UDisk están diseñados y mantenidos por Unum. Ambos tienen funciones completas, pero la característica más importante que ofrecen nuestras alternativas es el rendimiento. Ser rápido en la memoria es fácil. La lógica central de UCSet se puede encontrar en la biblioteca ucset de solo encabezado con plantilla.
Diseñar UDisk fue un esfuerzo mucho más desafiante que duró siete años. Incluyó inventar nuevas estructuras en forma de árbol, implementar una derivación parcial del kernel con io_uring , una derivación completa con SPDK , aceleración CUDA GPU e incluso un sistema de archivos interno personalizado. UDisk es el primer motor diseñado desde cero teniendo en cuenta arquitecturas paralelas y omisión del kernel .
La atomicidad siempre está garantizada. Incluso en escrituras no transaccionales: todas las actualizaciones pasan o todas fallan.
La coherencia se implementa de la forma más estricta posible: "Serialización estricta", lo que significa que:
Sin embargo, el comportamiento predeterminado se puede modificar a nivel de operaciones específicas. Para eso, ::ustore_option_transaction_dont_watch_k se puede pasar a ustore_transaction_init() o cualquier operación transaccional de lectura/escritura, para controlar las comprobaciones de coherencia durante la preparación.
| Lee | escribe | |
|---|---|---|
| Cabeza | Serie estricta | Serie estricta |
| Transacciones sobre instantáneas | De serie | Serie estricta |
| Transacciones sin instantáneas | Serie estricta | Serie estricta |
| Transacciones sin relojes | Serie estricta | Secuencial |
Si este tema es nuevo para usted, consulte el blog de Jepsen.io sobre coherencia.
| Lee | escribe | |
|---|---|---|
| Transacciones sobre instantáneas | ✓ | ✓ |
| Transacciones sin instantáneas | ✗ | ✓ |
La durabilidad no se aplica a los sistemas en memoria por definición. En sistemas híbridos o persistentes preferimos desactivarlo por defecto. Casi todos los DBMS que se basan en KVS prefieren implementar su propio mecanismo de durabilidad. Más aún en bases de datos distribuidas, donde pueden existir tres registros de escritura anticipada separados:
Si aún necesita durabilidad, escriba en las confirmaciones con un indicador opcional. En el controlador C, llamaría ustore_transaction_commit() con el indicador ::ustore_option_write_flush_k .
Todo el DBMS cabe en una imagen Docker de menos de 100 MB. Ejecute el siguiente script para extraer y ejecutar el contenedor, exponiendo el servidor Apache Arrow Flight en el puerto 38709 . Los SDK del cliente también se comunicarán a través de ese mismo puerto, de forma predeterminada.
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustoreEl archivo de configuración predeterminado se puede recuperar con:
cat /var/lib/ustore/config.jsonLa forma más sencilla de conectarse y probar sería el siguiente comando:
python ...Las imágenes de USore empaquetadas están disponibles en múltiples plataformas:
No dudes en comercializar y redistribuir UStore.
Ajustar bases de datos es tanto un arte como una ciencia. Proyectos como RocksDB proporcionan docenas de controles para optimizar el comportamiento. Permitimos reenviar archivos de configuración especializados al motor subyacente.
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}También disponemos de un procedimiento más sencillo, que sería suficiente para el 80% de los usuarios. Esto se puede ampliar para utilizar múltiples dispositivos o directorios, o para reenviar una configuración de motor especializada.
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}Las colecciones de bases de datos también se pueden configurar con archivos JSON.
A partir de la versión actual, se utilizan enteros con signo de 64 bits. Permite claves únicas en el rango de [0, 2^63) . Están llegando compilaciones de 128 bits con UUID, pero se desaconsejan las claves de longitud variable. ¿Por qué es así?
El uso de claves de longitud variable impone numerosas limitaciones en el diseño de una tienda de valores clave. En primer lugar, implica comparaciones lentas en cuanto a caracteres, lo que perjudica el rendimiento en las CPU hiperescalares modernas. En segundo lugar, obliga a que las claves y los valores se unan en un disco para minimizar los metadatos necesarios para la navegación. Por último, viola nuestra visión lógica simple de KVS como un "asignador de memoria persistente", lo que le otorga mucha más responsabilidad.
El enfoque recomendado para tratar con claves de cadena es:
Esto dará como resultado un único punto de conversión de representaciones de cadenas a enteros y mantendrá la mayor parte del sistema ágil y las interfaces de nivel C más simples de lo que podrían haber sido.
A partir de ahora, solo podemos abordar valores de 4 GB o menos. ¿Por qué? Las tiendas de valor clave generalmente están destinadas a operaciones de alta frecuencia. Con frecuencia (miles de veces por segundo), acceder y modificar archivos de 4 GB o más es imposible en el hardware moderno. Por lo tanto, nos atenemos a tipos de longitud más pequeños, lo que facilita un poco el uso de la representación de Apache Arrow y permite que KVS comprima mejor los índices.
Nuestra hoja de ruta de desarrollo es pública y está alojada en el repositorio de GitHub. Las próximas tareas incluyen:
Lea la hoja de ruta completa en nuestros documentos aquí.


