aiwhispr
version 0.941
AIWhispr es una herramienta sin código o con poco código para automatizar canalizaciones de incrustación de vectores para búsqueda semántica. Una configuración simple impulsa el proceso para leer archivos, extraer texto, crear incrustaciones de vectores y almacenarlos en una base de datos de vectores.
AIWhispr

AIWhispr tiene conectores para las siguientes bases de datos vectoriales
1 Qdrante
2 Milvus
3 Weaviate
4 Sentido tipográfico
5MongoDB
6 Postgres-PGVector
Asegúrese de haber instalado e iniciado su base de datos vectorial.
La variable de entorno AIWHISPR_HOME_DIR debe ser la ruta completa al directorio aiwhispr.
La variable de entorno AIWHISPR_LOG_LEVEL se puede configurar en DEBUG/INFO/WARNING/ERROR
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
Recuerde agregar las variables de entorno en su script de inicio de sesión de Shell
Ejecute el siguiente comando
$AIWHISPR_HOME/shell/install_python_packages.sh
Si la instalación de uwsgi falla, asegúrese de tener instalado gcc, python-dev, python3-dev.
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr viene con una aplicación optimizada para ayudarle a comenzar.
Ejecute la aplicación Streamlit
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
Esto debería iniciar una aplicación optimizada en el puerto predeterminado 8501 e iniciar una sesión en su navegador web.
Hay 3 pasos para configurar el canal para indexar su contenido para la búsqueda semántica.
1. Configurar para leer archivos desde una ubicación de almacenamiento
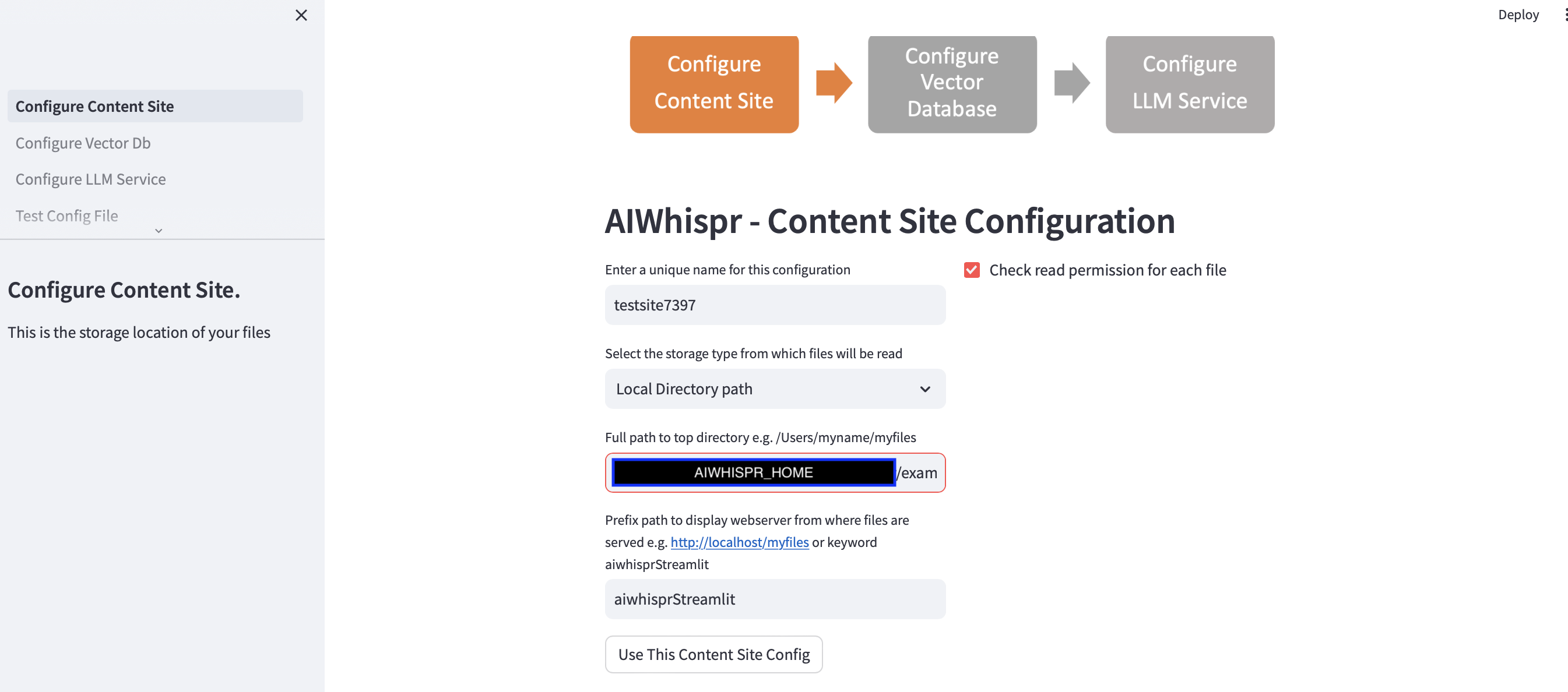
Puede continuar con la configuración predeterminada haciendo clic en el botón "Usar esta configuración del sitio de contenido"
y pase al siguiente paso para configurar la conexión de la base de datos vectorial.
El ejemplo predeterminado indexará noticias de la BBC para búsqueda semántica.
La aplicación Streamlit asume que está iniciando una nueva configuración y asignará un nombre de configuración aleatorio. Puede sobrescribirlo para darle un nombre más significativo. El nombre de la configuración debe ser único; no puede contener espacios en blanco ni caracteres especiales.
La configuración predeterminada leerá el contenido de la ruta del directorio local $AIWHISPR_HOME/examples/http/bbc
Contiene más de 2000 noticias de la BBC que están indexadas para búsqueda semántica.
Puede optar por leer el contenido almacenado en AWS S3, Azure Blob, Google Cloud Storage.
La configuración de la ruta del prefijo se utiliza para crear los enlaces web href para los resultados de la búsqueda. Puede continuar con la palabra clave predeterminada "aiwhisprStreamlit"
Haga clic en el botón "Usar esta configuración del sitio de contenido" y continúe con el siguiente paso para configurar la conexión de la base de datos vectorial haciendo clic en "Configurar Vector Db" en la barra lateral izquierda.
2. Configurar la base de datos vectorial
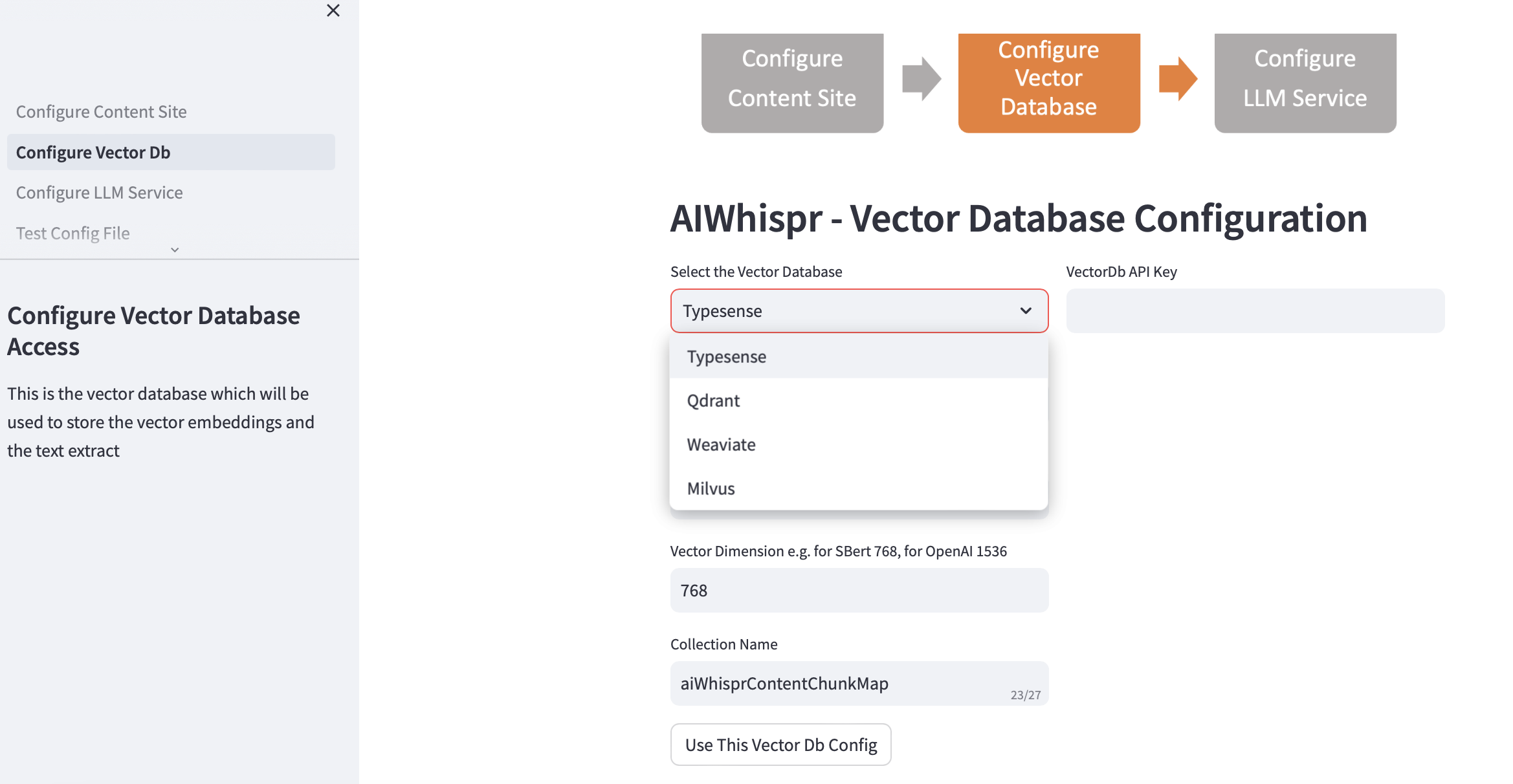
Elija su vectordb y proporcione los detalles de la conexión.
Cuando elige la base de datos vectorial, la dirección IP y los números de puerto de Vector Db se completan según las instalaciones predeterminadas. Puede cambiar esto según su configuración.
Su base de datos de vectores debe estar configurada para autenticación. En el caso de Qdrant, Weaviate, Typesense se requiere una clave API. Para Milvus se debe configurar una combinación de identificación de usuario y contraseña.
El tamaño de la dimensión del vector debe especificarse según el LLM que planea utilizar para codificar texto como incrustaciones de vectores. Ejemplo: para Open AI "text-embedding-ada-002", esto debe configurarse como 1536, que es el tamaño del vector devuelto por el servicio de incrustación de OpenAI.
El nombre de colección predeterminado creado en la base de datos vectorial es aiwhisprContentChunkMap. Puede especificar su propio nombre de colección.
Haga clic en el botón "Usar esta configuración de Vector Db" y luego pase al siguiente paso haciendo clic en "Configurar servicio LLM" en la barra lateral izquierda.
3. Configurar el servicio LLM
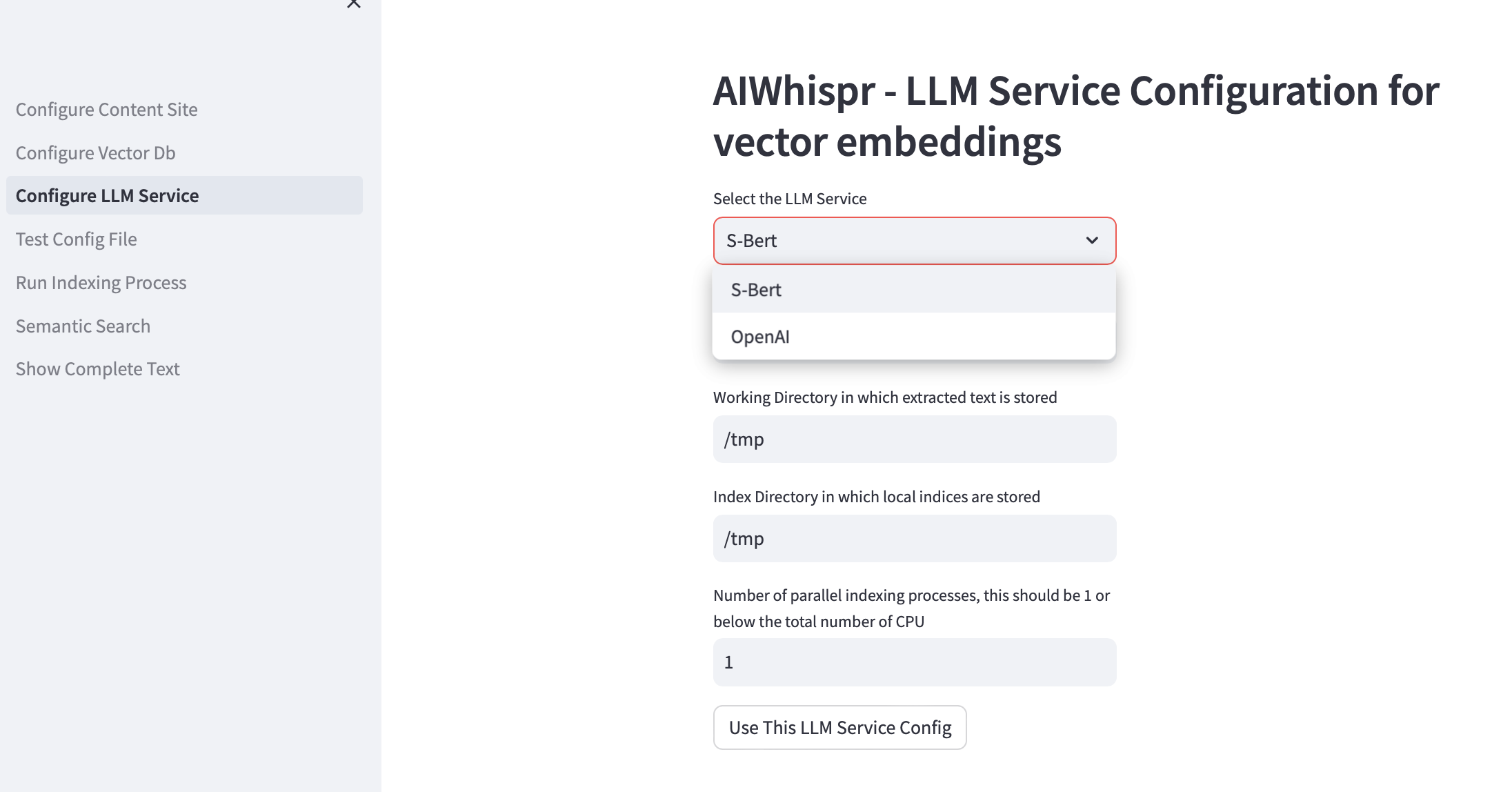
Puede optar por crear incrustaciones de vectores utilizando modelos previamente entrenados de Sbert que se ejecutan localmente o utilizar la API OpenAI.
Para la familia de modelos SBert, el modelo predeterminado utilizado es all-mpnet-base-v2. Puede especificar otro modelo de SBert.
Para OpenAI, el modelo de incrustación predeterminado es text-embedding-ada-002
El directorio de trabajo predeterminado es /tmp
El directorio de trabajo es la ubicación en la máquina local que se utilizará como directorio de trabajo para procesar los archivos que se leen/descargan desde su ubicación de almacenamiento. El texto extraído de sus documentos luego se fragmenta en un tamaño más pequeño, generalmente de 700 palabras, que luego se codifica como incrustaciones vectoriales. El directorio de trabajo se utiliza para almacenar los fragmentos de texto.
El directorio de indexación local predeterminado es /tmp
Puede especificar una ruta de directorio local persistente para el directorio de trabajo y de índice.
El index-dir se utiliza para almacenar la lista de indexación de archivos de contenido que deben leerse. AIWhispr admite múltiples procesos de indexación, cada proceso utilizará su propia lista de indexación, lo que le permitirá aprovechar múltiples CPU en su máquina.
Si desea aprovechar varias CPU para la indexación (leer contenido, crear incrustaciones de vectores, almacenar en una base de datos de vectores), especifique esto en el cuadro de prueba para ver la cantidad de procesos paralelos. Nuestra recomendación es que esto debería ser 1 o máximo (Número de CPU/2). Por ejemplo, en una máquina con 8 CPU, esto debe configurarse en 4. AIWhispr usa multiprocesamiento para evitar las limitaciones de Python GIL.
Haga clic en "Usar esta configuración de servicio LLM" para crear la versión final de su archivo de configuración de canalización de incrustación de vectores.
Se mostrará el contenido del archivo de configuración y su ubicación en su máquina.
Puede probar esta configuración haciendo clic en "Probar archivo de configuración" en la barra lateral izquierda.
4. Configuración de prueba
Ahora debería ver un mensaje que muestra la ubicación de su archivo de configuración de canalización de incrustación de vectores y un botón "Probar archivo de configuración".
Al hacer clic en el botón se iniciará el proceso que probará la configuración de la tubería para
Debería ver el mensaje "SIN ERRORES" al final de los registros que le informa que se puede utilizar esta configuración de canalización.
Haga clic en "Ejecutar proceso de indexación" en la barra lateral izquierda para iniciar el proceso.
5. Ejecutar el proceso de indexación
Debería ver el botón "Iniciar indexación".
Haga clic en este botón para iniciar el proceso. Los registros se actualizan cada 15 segundos.
El ejemplo predeterminado indexa más de 2000 noticias de la BBC, lo que lleva aproximadamente 20 minutos.
No salga de esta página mientras el proceso de indexación se esté ejecutando, es decir, mientras el estado "En ejecución" de Streamlit se muestra en la parte superior derecha.
También puede verificar si el proceso de indexación se está ejecutando usando grep en su máquina.
ps -ef | grep python3 | grep index_content_site.py
6. Búsqueda Semántica
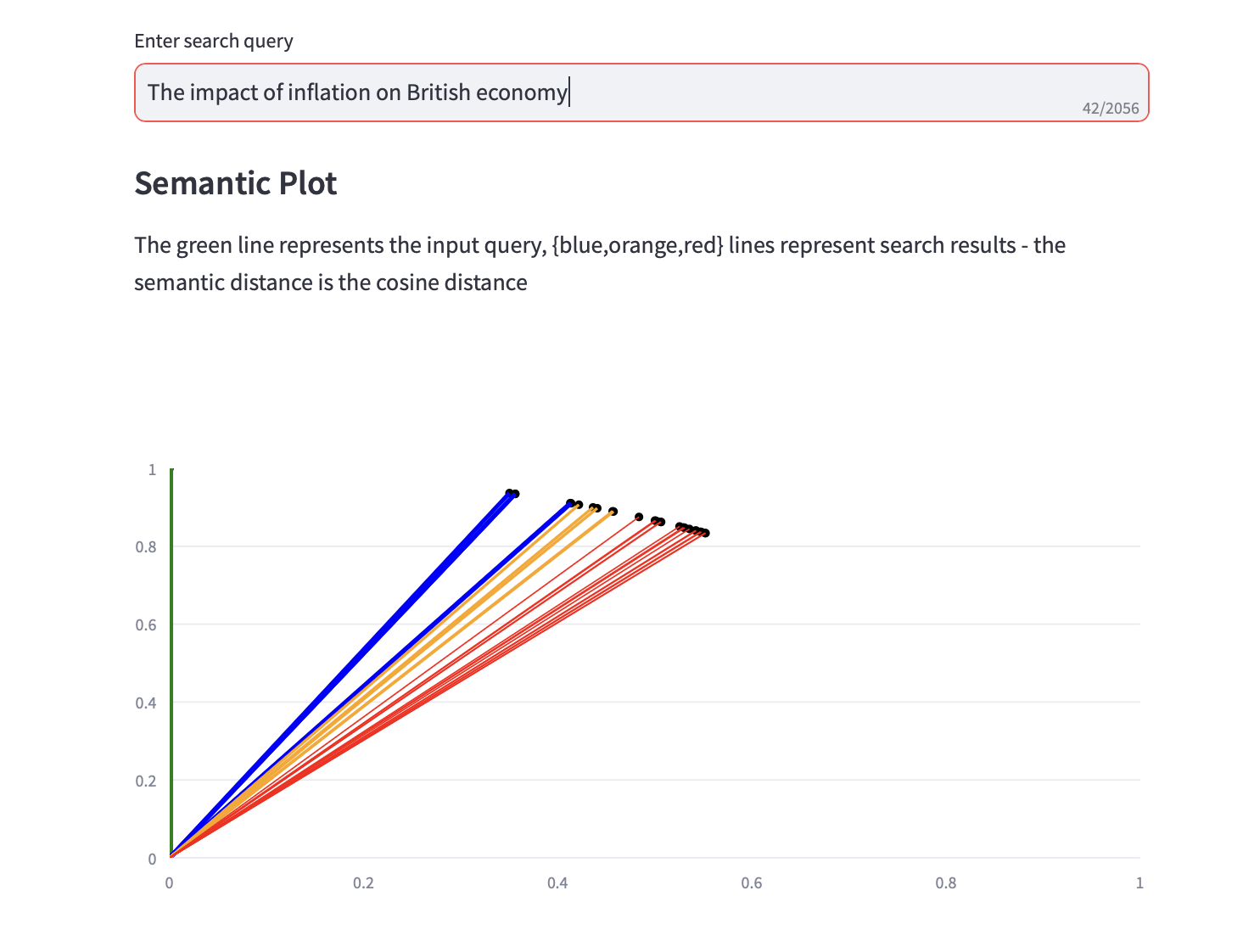
Ahora puede ejecutar consultas de búsqueda semántica.
También se muestra un gráfico semántico que muestra la distancia del coseno y un análisis de los 3 PCA principales para los resultados de la búsqueda junto con los resultados de la búsqueda de texto.