lnx
v0.9.0 Master

Rico en funciones | ⚡ Increíblemente rápido
Un despliegue ultrarrápido y adaptable del motor de búsqueda tantivy a través de REST.
lnx está diseñado para no reinventar la rueda, se encuentra en la cima del tiempo de ejecución de robo de trabajo de Tokio , el marco hiperweb combinado con la potencia informática bruta del motor de búsqueda tantivy .
En conjunto, esto permite a lnx ofrecer indexación de milisegundos en decenas de miles de inserciones de documentos a la vez (¡no más esperas para que las cosas se indexen!), transacciones por índice y la capacidad de procesar búsquedas como si fuera solo otra búsqueda en la tabla hash.
lnx, aunque es muy nuevo, ofrece una amplia gama de funciones gracias al ecosistema en el que se encuentra.
Aquí puede ver a lnx realizando una búsqueda mientras escribe en un conjunto de datos de 27 millones de documentos con un tamaño razonable de 18 GB una vez indexado, ejecutado en mi i7-8700k usando ~3 GB de RAM con nuestro sistema rápido y difuso . ¿Tiene un conjunto de datos más grande para probar? ¡Abre una edición!
lnx puede brindar la capacidad de ajustar el sistema a su caso de uso particular. Puede personalizar los subprocesos del tiempo de ejecución asíncrono. El grupo de subprocesos concurrentes, subprocesos por lector y subprocesos de escritor, todo por índice.
Esto le brinda la capacidad de controlar en detalle a dónde van sus recursos informáticos. ¿Tiene un conjunto de datos grande pero una cantidad menor de lecturas simultáneas? Aumente los hilos del lector a cambio de una concurrencia máxima más baja.
Las siguientes cifras fueron tomadas por nuestro lnx-cli en el pequeño conjunto de datos movies.json , no intentamos más porque Meilisearch tarda increíblemente mucho tiempo en indexar millones de documentos, aunque el nuevo motor Meilisearch ha mejorado esto un poco.
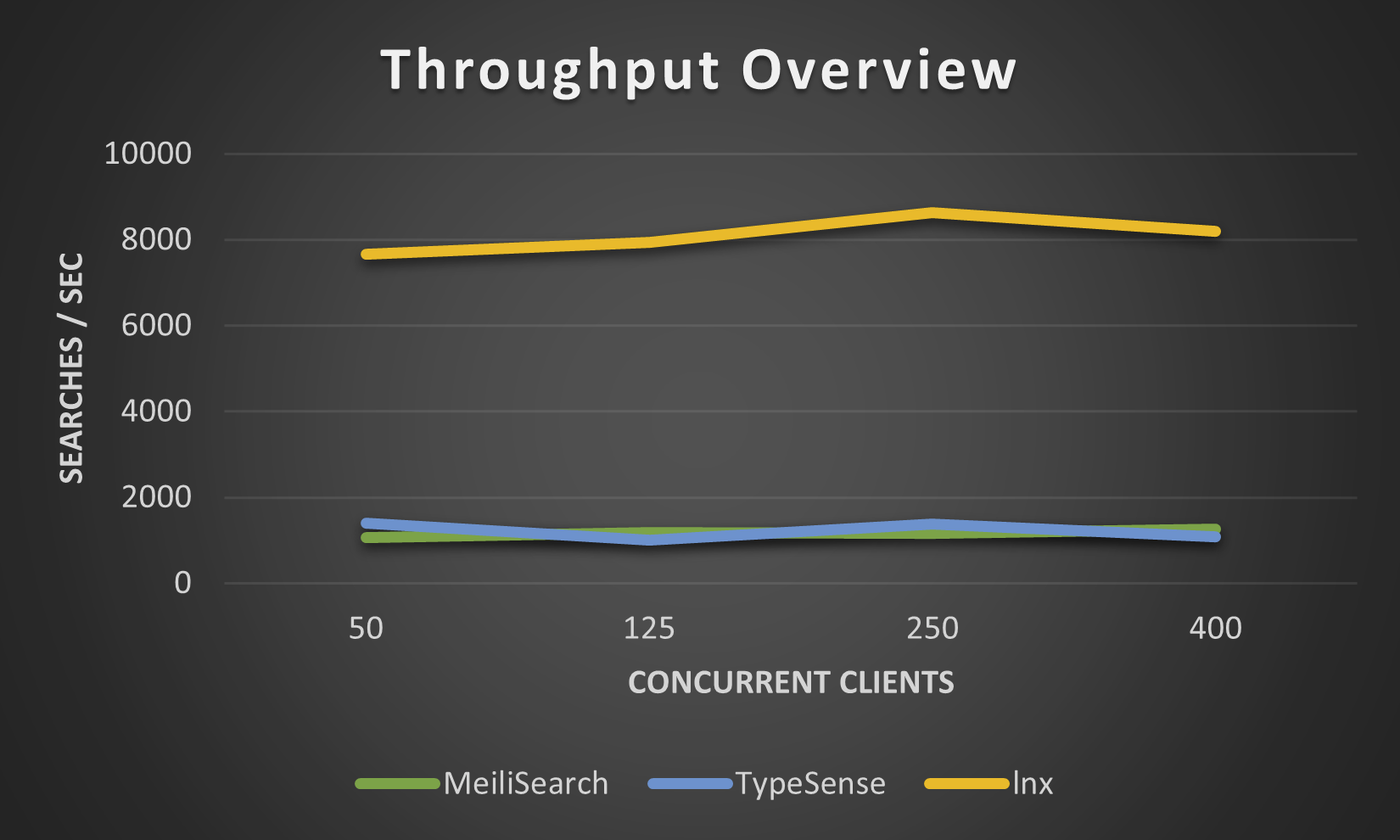
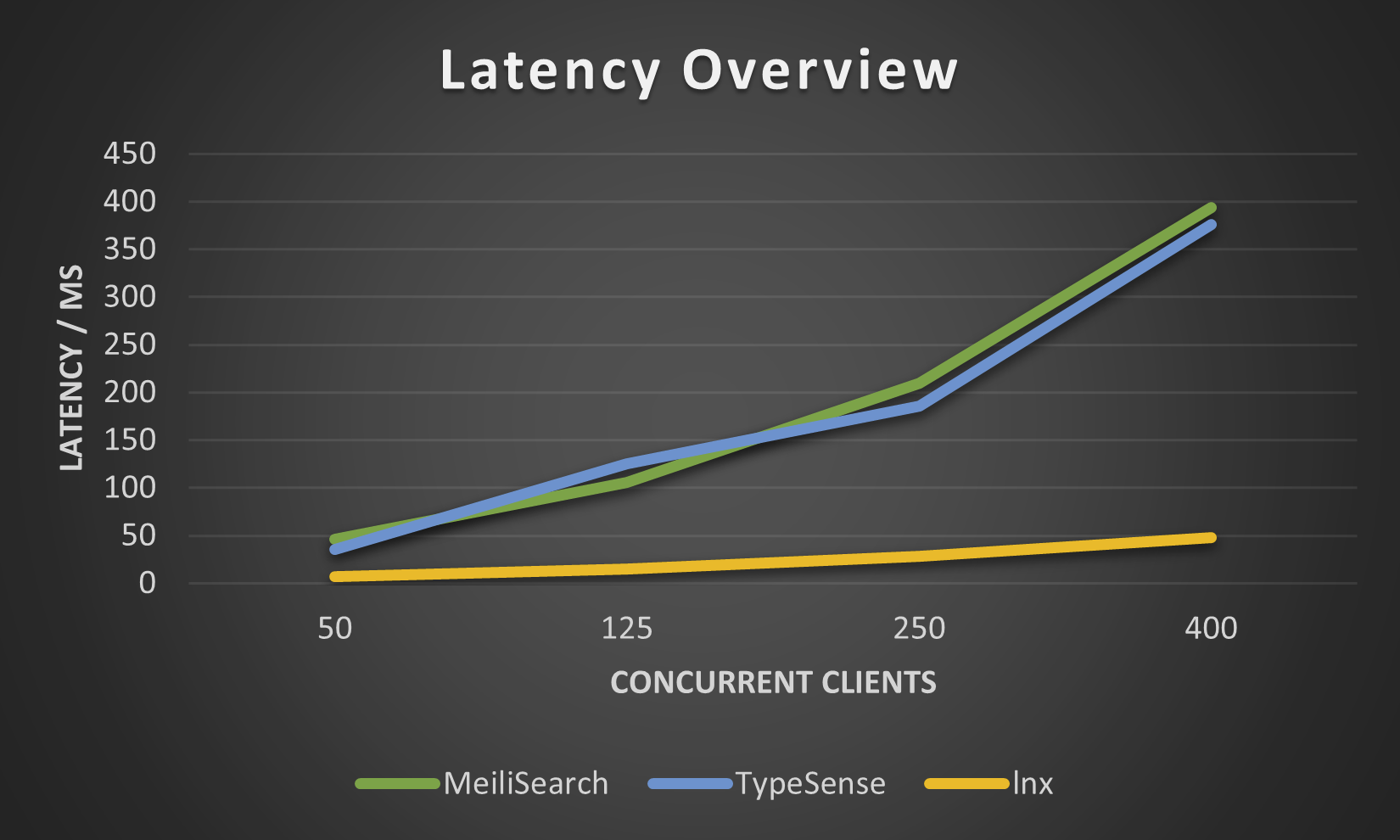
Por mucho que lnx proporcione una amplia gama de funciones, no puede hacerlo todo siendo un sistema tan joven. Naturalmente, tiene algunas limitaciones:


