sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
Mantenedor: jcudit y lsgos
Proyecto mantenido hasta al menos (AAAA-MM-DD): 2023-03-14
Este es un ejemplo de cómo utilizar la API Cohere para crear un motor de búsqueda semántica simple. No está destinado a estar listo para producción ni escalar de manera eficiente (aunque podría adaptarse a estos fines), sino que sirve para mostrar la facilidad de producir un motor de búsqueda impulsado por representaciones producidas por los modelos de lenguajes grandes (LLM) de Cohere.
El algoritmo de búsqueda utilizado aquí es bastante simple: simplemente encuentra el párrafo que más se aproxima a la representación de la pregunta, utilizando el punto final co.embed . Esto se explica con más detalle a continuación, pero aquí hay un diagrama simple de lo que está sucediendo. Primero dividimos el texto de entrada en una serie de párrafos, almacenamos sus direcciones en la entrada en una lista y generamos una incrustación vectorial para cada párrafo usando co.embed :
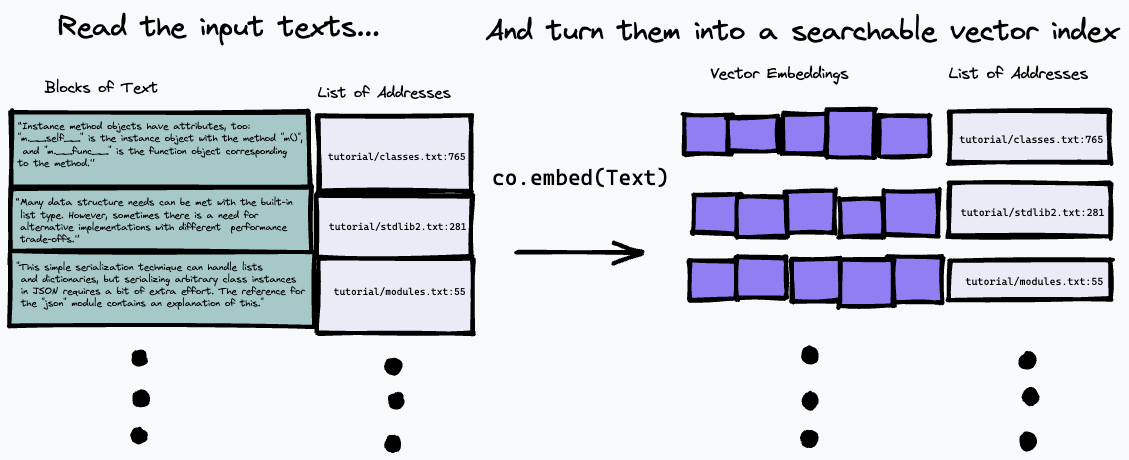
Luego, podemos consultar nuestro índice incrustando la consulta de texto y buscando los párrafos en el texto fuente que tengan la coincidencia más cercana usando alguna medida de similitud vectorial (usamos la similitud del coseno): 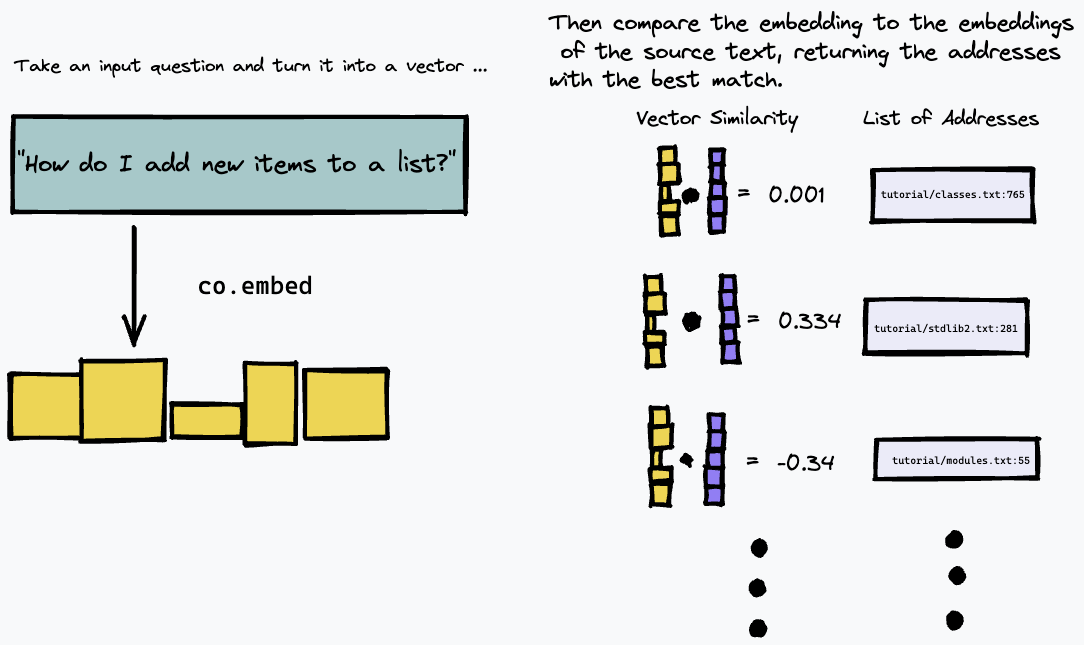
Como resultado, funciona mejor en fuentes de texto donde la respuesta a una pregunta determinada probablemente esté dada en un párrafo concreto del texto, como documentación técnica o wikis internos que están estructurados como una lista de instrucciones o hechos concretos. No funciona tan bien, por ejemplo, para responder preguntas sobre textos de formato libre, como novelas, donde la información puede estar distribuida en varios párrafos; necesitaría utilizar un método diferente para indexar el texto para esto.
Como ejemplo, este repositorio crea un motor de búsqueda semántico simple sobre la versión de texto de la última documentación de Python.
Para instalar los requisitos de Python, asegúrese de tener Poesía instalada y ejecutar:
# install python deps
poetry installTambién deberías tener Docker instalado. En OS X, si usas homebrew, te recomendamos ejecutar
brew install --cask dockerAntes de ejecutar Docker (por ejemplo, para ejecutar nuestro servidor) por primera vez en OS X, abra la aplicación Docker y concédale los privilegios que necesita para ejecutarse en su sistema.
También necesitará tener una clave API de Cohere en COHERE_TOKEN . Obtenga uno de la plataforma Cohere (cree una cuenta si es necesario) y escríbalo en su entorno
export COHERE_TOKEN= < MY_API_KEY > (donde <MY_API_KEY> es la clave que obtuvo, sin los corchetes <...> ).
Alternativamente, puede pasar COHERE_TOKEN=<MY_API_KEY> como argumento adicional a cualquier comando make a continuación.
Siga estos pasos para crear primero un índice semántico de su colección de documentos. Estos pasos producen un índice semántico para los documentos oficiales de Python, pero podrían adaptarse para recopilaciones de datos arbitrarios.
Primero, descargue la documentación de Python ejecutando uno de los siguientes comandos.
Si desea comenzar rápidamente, ejecute
make download-python-docs-smallpara limitar el conjunto de documentos al tutorial de Python. Sólo recomendamos hacer esto para una prueba rápida, ya que los resultados serán muy limitados .
Si desea probar el motor de búsqueda en toda la documentación de Python, ejecute
make download-python-docspero tenga en cuenta que producir las incrustaciones llevará horas (aunque solo es necesario hacerlo una vez).
Alternativamente, si desea experimentar con su propio texto, simplemente descárguelo como archivos .txt a un directorio llamado txt/ en este repositorio.
Una vez que tenga algo de texto, debemos procesarlo en un índice de búsqueda de incrustaciones y direcciones.
Esto se puede hacer usando el comando
make embeddings suponiendo que su texto de destino esté en el directorio ./txt/ .
El comando buscará en el directorio ./txt/ de forma recursiva archivos con una extensión .txt y creará una base de datos simple de las incrustaciones, el nombre del archivo y el número de línea de cada párrafo.
Advertencia: si tienes mucho texto para buscar, ¡esto puede tardar un poco en finalizar!
Una vez que haya creado un archivo embeddings.npz , puede usar el siguiente comando para crear una imagen de la ventana acoplable que servirá como una aplicación REST simple para permitirle consultar la base de datos que ha creado:
make buildLuego puede iniciar el servidor usando
make runEsto es un poco excesivo para un ejemplo simple, pero está diseñado para reflejar el hecho de que crear un índice de un gran cuerpo de texto es relativamente lento y garantiza que las consultas al motor sean rápidas.
Si desea utilizar este proyecto como bloque de construcción para una aplicación real, es probable que desee mantener su base de datos de incrustaciones de texto en una arquitectura de servidor y consultarla con un cliente liviano. Empaquetar el servidor como una aplicación acoplable significa que es muy sencillo convertirlo en una aplicación "real" implementándola en un servicio en la nube.
Si abre una nueva ventana de terminal para cualquiera de las siguientes opciones, recuerde ejecutar
export COHERE_TOKEN= < MY_API_KEY > Con diferencia, la opción más sencilla es ejecutar nuestro script auxiliar:
scripts/ask.sh " My query here "para consultar la base de datos. El script toma un segundo argumento opcional que especifica la cantidad de resultados deseados.
El script muestra una interfaz vim modificada, con los siguientes comandos:
q para salir.El panel superior le mostrará la posición en el documento donde se encuentra el resultado.
Una vez que el servidor se esté ejecutando, puede consultarlo utilizando una API REST simple. Puede explorar la API directamente yendo a /docs#/default/search_search_post aquí. Es una API REST JSON simple; Así es como puedes hacer una consulta usando curl :
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
Esto devolverá una lista JSON de longitud num_results , cada uno con el nombre de archivo y el número de línea ( doc_url y block_url ) de los bloques que eran la coincidencia semántica más cercana a su consulta. Pero probablemente quieras leer la parte de los archivos que es la mejor respuesta.
Mientras buscamos en archivos de texto locales, en realidad es un poco más fácil analizar el resultado usando herramientas de línea de comandos; utilice el script de Python utils/query_server.py proporcionado para consultarlo en la línea de comando. query_server.py imprime los resultados en el formato estándar file_name:line_number: para que podamos revisar los resultados reales de una manera agradable aprovechando el modo de corrección rápida de vim .
Suponiendo que tiene vim en su máquina, simplemente puede
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
para que vim abra los archivos de texto indexados en las ubicaciones devueltas por el algoritmo de búsqueda. (use :qall para cerrar tanto la ventana como el navegador de corrección rápida). Puede recorrer los resultados devueltos usando :cn y :cp . Los resultados no son perfectos; Es una búsqueda semántica, por lo que es de esperar que la coincidencia sea un poco confusa. A pesar de esto, a menudo encuentro que puede obtener la respuesta a su pregunta en los primeros resultados, y el uso de la API de Cohere le permite expresar su pregunta en lenguaje natural y le permite crear un motor de búsqueda sorprendentemente efectivo en solo unas pocas líneas de código.
Algunas consultas que es bueno probar en el caso de los documentos de Python y que muestran que la búsqueda funciona bien en preguntas genéricas en lenguaje natural son:
How do I put new items in a list? (Tenga en cuenta que esta pregunta evita el uso de la palabra clave 'agregar' y no coincide exactamente con cómo los documentos explican agregar (dicen que se usa para agregar nuevos elementos al final de una lista). Pero la búsqueda semántica descubre correctamente que el El párrafo relevante sigue siendo el que mejor se adapta.)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (tenga en cuenta que para esta pregunta, el primer resultado para mí es una pregunta frecuente sobre básicamente este tema exacto, pero con una pregunta redactada de manera diferente. Sin embargo, dado que se trata de una búsqueda semántica, nuestro algoritmo selecciona correctamente un resultado que coincide con el significado, no solo con el redacción, de nuestra consulta)How do I remove an item from a set?How do list comprehensions work? Este repositorio utiliza una estrategia muy simple para indexar un documento y buscar la mejor coincidencia. Primero, divide cada documento en párrafos o "bloques". Luego, llama co.embed en cada párrafo para generar una incrustación de vectores utilizando el modelo de lenguaje de Cohere. Luego almacena cada vector de incrustación, junto con el documento correspondiente y el número de línea del párrafo, en una matriz simple como una "base de datos".
Para realizar la búsqueda, utilizamos la biblioteca de búsqueda de similitudes FAISS. Cuando recibimos una consulta, utilizamos la misma llamada a la API de Cohere para insertar la consulta. Luego usamos FAISS para encontrar la cima
Si tiene alguna pregunta o comentario, presente un problema o comuníquese con nosotros en Discord.
Si desea contribuir a este proyecto, lea CONTRIBUTORS.md en este repositorio y firme el Acuerdo de licencia de colaborador antes de enviar cualquier solicitud de extracción. Se generará un enlace para firmar el CLA de Cohere la primera vez que realice una solicitud de extracción a un repositorio de Cohere.
Toy Semantic Search tiene una licencia MIT, como se encuentra en el archivo LICENCIA.


