wagtail_textract
1.0.0
Este paquete no se mantiene y no tenemos planes de mantenerlo.
Le recomendamos que lo utilice como ejemplo, tal vez copie el código en su propio proyecto, pero no instale el paquete.
Este paquete sirve para reemplazar la clase Documento de Wagtail por una que permita buscar en el contenido del archivo Documento mediante extracto de texto.
Textract puede extraer texto de (entre otros) archivos PDF, Excel y Word.
El paquete se inspiró en el problema "Buscar: extraer texto de documentos" en Wagtail.
Los documentos funcionarán como antes, excepto que la búsqueda de documentos en la interfaz de administración de Wagtail también encontrará términos de búsqueda en el contenido de los archivos.
Algunas capturas de pantalla para ilustrar.
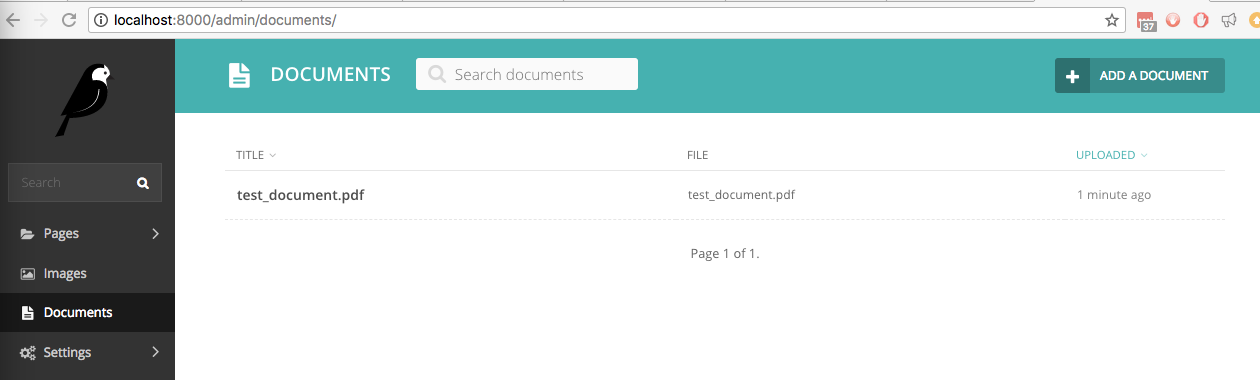
En nuestro nuevo sitio Wagtail con wagtail_textract instalado, cargamos un archivo llamado test_document.pdf con texto escrito a mano. Aparece en la interfaz de administración en Documentos:
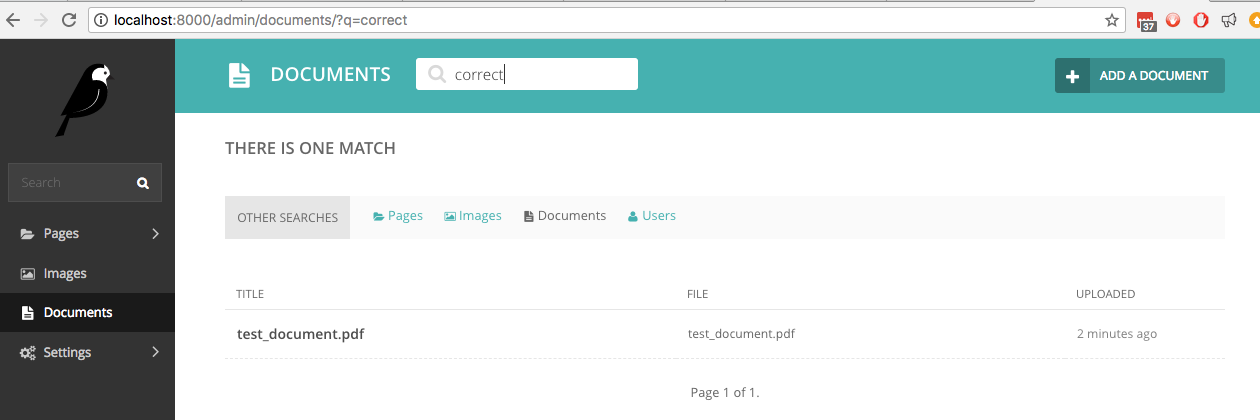
Si ahora buscamos en Documentos la palabra correct , que es una de las palabras escritas a mano, la búsqueda en vivo la encuentra:
Se supone que esta búsqueda no solo debería estar disponible en la interfaz de administración de Wagtail, sino también en una vista de búsqueda pública, para lo cual proporcionamos un código de ejemplo.
Hemos estado utilizando este paquete en producción desde agosto de 2018 en https://nuffic.nl.
wagtail_textract a sus requisitos y/o pip install wagtail_textractINSTALLED_APPS .WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document" en su configuración de Django.Nota: Recibirá una advertencia de incompatibilidad durante la instalación de wagtail_textract (Wagtail 2.0.1 instalado):
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
No hemos visto que esto genere problemas, pero es algo a tener en cuenta.
Para hacer que textract utilice Tesseract, lo que sucede si textract normal no encuentra texto, debe agregar los archivos de datos en los que Tesseract puede basar su coincidencia de palabras.
Cree un directorio tessdata en el directorio de su proyecto y descargue los idiomas que desee.
La transcripción se realiza automáticamente después de guardar el documento, en un ejecutor asyncio para evitar el bloqueo de la respuesta durante el procesamiento.
Para transcribir todos los documentos existentes, ejecute el comando de administración::
./manage.py transcribe_documents
Obviamente, esto puede llevar mucho tiempo.
A continuación se muestra un ejemplo de código para una vista de búsqueda (fuera de la interfaz de administración de Wagtail) que muestra resultados de página y documento.
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
}) Su plantilla debe permitir el manejo de documentos de manera diferente a las páginas, porque no puede generar pageurl result en un documento:
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} Para utilizar wagtail_textract, su modelo CustomizedDocument debe hacer lo mismo que el documento de wagtail_textract:
TranscriptionMixinsearch_fields from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
] Tenga en cuenta que la primera clase en la subclase debe ser TranscriptionMixin , por lo que save() tiene prioridad sobre la de las otras clases principales.
Para ejecutar pruebas, consulte este repositorio y:
make test
Se generará un informe de cobertura en ./coverage_html_report/ .


