loss_function_search
1.0.0
Xiaobo Wang*, Shuo Wang*, Cheng Chi, Shifeng Zhang, Tao Mei
Esta es la implementación oficial de nuestra función de pérdida de búsqueda de reconocimiento facial. Está aceptado por ICML 2020.
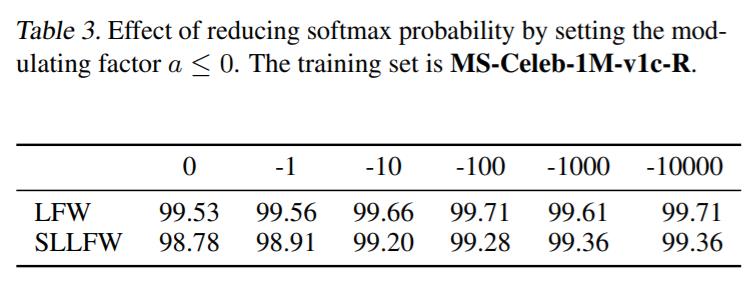
En el reconocimiento facial, el diseño de funciones de pérdida softmax basadas en márgenes (p. ej., angulares, aditivas, márgenes angulares aditivos) juega un papel importante en el aprendizaje de características discriminativas. Sin embargo, estos métodos heurísticos hechos a mano no son óptimos porque requieren mucho esfuerzo para explorar el gran espacio de diseño. Primero analizamos que la clave para mejorar la discriminación de características es en realidad cómo reducir la probabilidad softmax . Luego diseñamos una formulación unificada para las pérdidas softmax basadas en márgenes actuales. En consecuencia, definimos un espacio de búsqueda novedoso y desarrollamos un método de búsqueda guiado por recompensas para obtener automáticamente el mejor candidato. Los resultados experimentales en una variedad de puntos de referencia de reconocimiento facial han demostrado la efectividad de nuestro método sobre las alternativas de última generación.
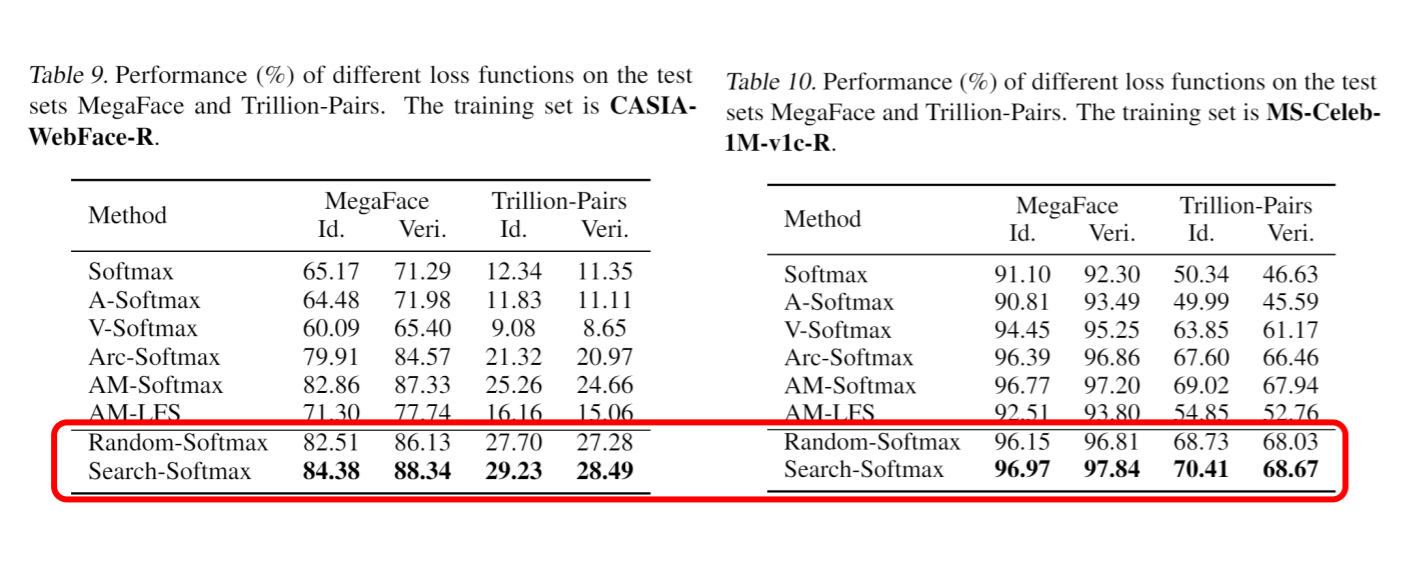

Para validar la efectividad de nuestro espacio de búsqueda, simplemente se puede elegir random-softmax. En train.sh, puedes configurar do_search=1. Si usamos softmax aleatorio para entrenar nuestra red, obtenemos el siguiente resultado.
Se requiere Pytorch 1.1 o superior.
En la implementación actual, usamos lmdb para empaquetar nuestras imágenes de entrenamiento. El formato de nuestro lmdb proviene principalmente de Caffe. Y podrías escribir tu propio archivo caffe.proto de la siguiente manera:
syntax = "proto2";
message Datum {
//the acutal image data, in bytes.
optional bytes data=1;
}
Aparte de lmdb, debería existir un archivo de texto que describa lmdb. Cada línea del archivo de texto contiene 2 campos separados por un espacio. La línea en el archivo de texto es la siguiente:
lmdb_key label
./train.shPodrías usar ./train.sh. TENGA EN CUENTA que antes de ejecutar train.sh, debe proporcionar su propio train_source_lmdb y train_source_file. Para más uso, por favor
python main . py - h

