yagooglesearch
v1.10.0
yagooglesearch es una biblioteca de Python para ejecutar búsquedas en Google inteligentes, realistas y ajustables. Simula el comportamiento humano real de búsqueda en Google para evitar que Google limite la velocidad (la temida respuesta HTTP 429), y si HTTP 429 es bloqueado por Google, la lógica es dar marcha atrás y continuar intentándolo. La biblioteca no utiliza la API de Google y se basa en gran medida en la biblioteca de búsqueda de Google. Las características incluyen:
requests para solicitudes HTTP y gestión de cookiesEste código se proporciona tal cual y usted es totalmente responsable de cómo se utiliza. La eliminación de los resultados de la Búsqueda de Google puede violar sus Términos de servicio. Otra biblioteca de búsqueda de Python en Google tenía información/discusión interesante al respecto:
El método preferido de Google es utilizar su API.
pip install yagooglesearchgit clone https://github.com/opsdisk/yagooglesearch
cd yagooglesearch
virtualenv -p python3 .venv # If using a virtual environment.
source .venv/bin/activate # If using a virtual environment.
pip install . # Reads from pyproject.toml import yagooglesearch
query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
tbs = "li:1" ,
max_search_result_urls_to_return = 100 ,
http_429_cool_off_time_in_minutes = 45 ,
http_429_cool_off_factor = 1.5 ,
# proxy="socks5h://127.0.0.1:9050",
verbosity = 5 ,
verbose_output = True , # False (only URLs) or True (rank, title, description, and URL)
)
client . assign_random_user_agent ()
urls = client . search ()
len ( urls )
for url in urls :
print ( url ) Aunque buscar en Google a través de la GUI mostrará un mensaje como "Aproximadamente 13.000.000 de resultados", eso no significa que yagooglesearch encontrará algo parecido a eso. Las pruebas muestran que, como máximo, se devuelven unos 400 resultados. Si configura 400 < max_search_result_urls_to_return , se imprimirá un mensaje de advertencia en los registros. Vea el #28 para la discusión.
Baja y lenta es la estrategia a la hora de ejecutar búsquedas en Google utilizando yagooglesearch . Si comienzas a recibir respuestas HTTP 429, Google te ha detectado legítimamente como un bot y bloqueará tu IP durante un período de tiempo determinado. yagooglesearch no puede omitir CAPTCHA, pero puede hacerlo manualmente realizando una búsqueda en Google desde un navegador y demostrando que es un humano.
Se desconocen los criterios y umbrales para ser bloqueado, pero en general, debería ser suficiente aleatorizar el agente de usuario, esperar suficiente tiempo entre los resultados de búsqueda paginados (7-17 segundos) y esperar suficiente tiempo entre diferentes búsquedas en Google (30-60 segundos). Sin embargo, su kilometraje definitivamente variará. Usar esta biblioteca con Tor probablemente te bloqueará rápidamente.
Si yagooglesearch detecta una respuesta HTTP 429 de Google, se suspenderá durante http_429_cool_off_time_in_minutes minutos y luego volverá a intentarlo. Cada vez que se detecta un HTTP 429, aumenta el tiempo de espera en un factor de http_429_cool_off_factor .
El objetivo es que yagooglesearch se preocupe por la detección y recuperación de HTTP 429 y no sobrecargar al script que lo utiliza.
Si no desea que yagooglesearch maneje HTTP 429 y prefiere hacerlo usted mismo, pase yagooglesearch_manages_http_429s=False al crear una instancia del objeto yagooglesearch. Si se detecta un HTTP 429, la cadena "HTTP_429_DETECTED" se agrega a un objeto de lista que se devolverá y usted decide cuál debe ser el siguiente paso. El objeto de lista contendrá todas las URL encontradas antes de que se detectara HTTP 429.
import yagooglesearch
query = "site:twitter.com"
client = yagooglesearch . SearchClient (
query ,
tbs = "li:1" ,
verbosity = 4 ,
num = 10 ,
max_search_result_urls_to_return = 1000 ,
minimum_delay_between_paged_results_in_seconds = 1 ,
yagooglesearch_manages_http_429s = False , # Add to manage HTTP 429s.
)
client . assign_random_user_agent ()
urls = client . search ()
if "HTTP_429_DETECTED" in urls :
print ( "HTTP 429 detected...it's up to you to modify your search." )
# Remove HTTP_429_DETECTED from list.
urls . remove ( "HTTP_429_DETECTED" )
print ( "URLs found before HTTP 429 detected..." )
for url in urls :
print ( url )
yagooglesearch admite el uso de un proxy. El proxy proporcionado se utiliza durante todo el ciclo de vida de la búsqueda para que parezca más humano, en lugar de rotar entre varios proxy para diferentes partes de la búsqueda. El ciclo de vida de la búsqueda general es:
google.com Para utilizar un proxy, proporcione una cadena de proxy al inicializar un objeto yagooglesearch.SearchClient :
client = yagooglesearch . SearchClient (
"site:github.com" ,
proxy = "socks5h://127.0.0.1:9050" ,
) Los esquemas de proxy admitidos se basan en los admitidos en la biblioteca requests de Python (https://docs.python-requests.org/en/master/user/advanced/#proxies):
httphttpssocks5 : "hace que la resolución DNS se realice en el cliente, en lugar de en el servidor proxy". Probablemente no desee esto, ya que todas las búsquedas de DNS se originarían desde donde se ejecuta yagooglesearch en lugar del proxy.socks5h - "Si desea resolver los dominios en el servidor proxy, utilice calcetines5h como esquema". Esta es la mejor opción si está utilizando SOCKS porque la búsqueda de DNS y la búsqueda de Google provienen de la dirección IP del proxy. Si está utilizando un certificado autofirmado para un proxy HTTPS, probablemente necesitará deshabilitar la verificación SSL/TLS cuando:
yagooglesearch.SearchClient : import yagooglesearch
query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
proxy = "http://127.0.0.1:8080" ,
verify_ssl = False ,
verbosity = 5 ,
) query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
proxy = "http://127.0.0.1:8080" ,
verbosity = 5 ,
)
client . verify_ssl = False Si desea utilizar varios servidores proxy, esa carga recae en el script que utiliza la biblioteca yagooglesearch para crear una instancia de un nuevo objeto yagooglesearch.SearchClient con el proxy diferente. A continuación se muestra un ejemplo de cómo recorrer una lista de servidores proxy:
import yagooglesearch
proxies = [
"socks5h://127.0.0.1:9050" ,
"socks5h://127.0.0.1:9051" ,
"http://127.0.0.1:9052" , # HTTPS proxy with a self-signed SSL/TLS certificate.
]
search_queries = [
"python" ,
"site:github.com pagodo" ,
"peanut butter toast" ,
"are dragons real?" ,
"ssh tunneling" ,
]
proxy_rotation_index = 0
for search_query in search_queries :
# Rotate through the list of proxies using modulus to ensure the index is in the proxies list.
proxy_index = proxy_rotation_index % len ( proxies )
client = yagooglesearch . SearchClient (
search_query ,
proxy = proxies [ proxy_index ],
)
# Only disable SSL/TLS verification for the HTTPS proxy using a self-signed certificate.
if proxies [ proxy_index ]. startswith ( "http://" ):
client . verify_ssl = False
urls_list = client . search ()
print ( urls_list )
proxy_rotation_index += 1 Si tiene un valor de cookie GOOGLE_ABUSE_EXEMPTION , se puede pasar a google_exemption al crear una instancia del objeto SearchClient .
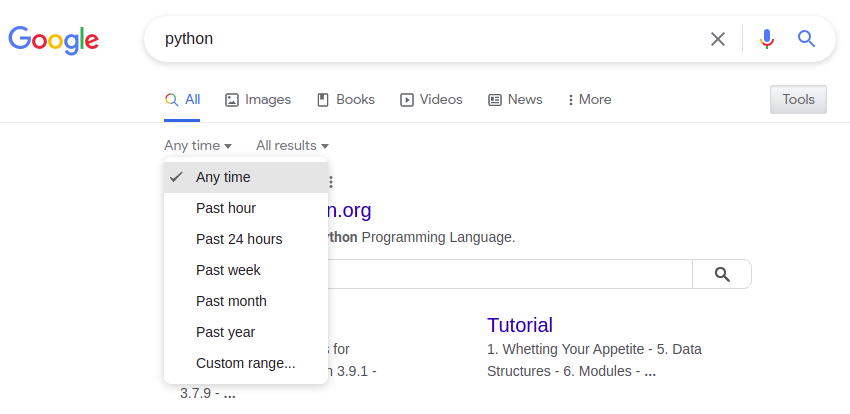
El parámetro &tbs= se utiliza para especificar filtros textuales o basados en tiempo.
&tbs=li:1
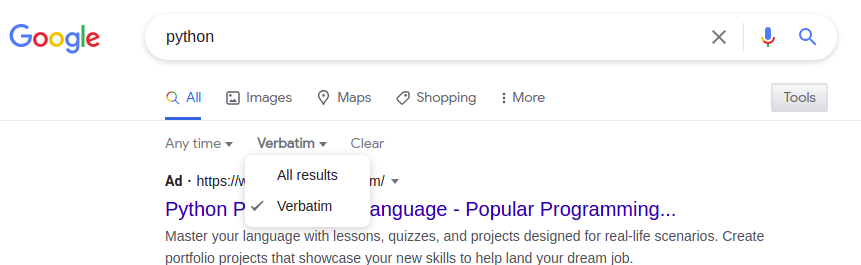
| Filtro de tiempo | &tbs= parámetro de URL | Notas |
|---|---|---|
| hora pasada | qdr:h | |
| dia pasado | qdr:d | Últimas 24 horas |
| La semana pasada | qdr:w | |
| El mes pasado | qdr: m | |
| El año pasado | qdr:y | |
| Costumbre | cdr:1,cd_min:1/1/2021,cd_max:6/1/2021 | Ver función yagooglesearch.get_tbs() |
Actualmente, la función .filter_search_result_urls() eliminará cualquier URL que contenga la palabra "google". Esto es para evitar que las URL de búsqueda devueltas se contaminen con las URL de Google. Tenga en cuenta esto si intenta buscar explícitamente resultados que puedan tener "google" en la URL, como site:google.com computer
Distribuido bajo la licencia BSD de 3 cláusulas. Consulte LICENCIA para obtener más información.
@opsdisk
Enlace del proyecto: https://github.com/opsdisk/yagooglesearch


