SeekStorm
v0.11.0

SeekStorm es una biblioteca de búsqueda de texto completo de código abierto y un servidor multiinquilino implementado en Rust .
El desarrollo comenzó en 2015, en producción desde 2020, puerto Rust en 2023, código abierto en 2024, trabajo en progreso.
SeekStorm es de código abierto y tiene licencia Apache 2.0.
Publicaciones de blog: SeekStorm ahora es de código abierto y SeekStorm obtiene búsqueda por facetas, búsqueda de proximidad geográfica y clasificación de resultados.
Tipos de consulta
Tipos de resultados
Actuación
Menor latencia, mayor rendimiento, menor costo y consumo de energía, especialmente. para consultas multicampo y simultáneas.
Las latencias de cola bajas garantizan una experiencia de usuario fluida y evitan la pérdida de clientes e ingresos.
Mientras que algunos dependen de aceleradores de hardware propietarios (FPGA/ASIC) o clústeres para mejorar el rendimiento,
SeekStorm logra algorítmicamente un impulso similar en un único servidor básico.
Consistencia
No hay latencia de consultas impredecible durante y después de la indexación de grandes volúmenes, ya que SeekStorm no requiere fusiones de segmentos que consumen muchos recursos.
Latencias estables: sin costos de arranque en frío debido a la compilación justo a tiempo, sin retrasos impredecibles en la recolección de basura.
Escalada
Mantiene una latencia baja, un alto rendimiento y un bajo consumo de RAM incluso para índices de miles de millones de escala.
Número de campo, longitud de campo y tamaño de índice ilimitados.
Pertinencia
La clasificación de proximidad de términos proporciona resultados más relevantes en comparación con BM25.
en tiempo real
Verdadera búsqueda en tiempo real, a diferencia de NRT: cada documento indexado se puede buscar inmediatamente, incluso antes y durante la confirmación.
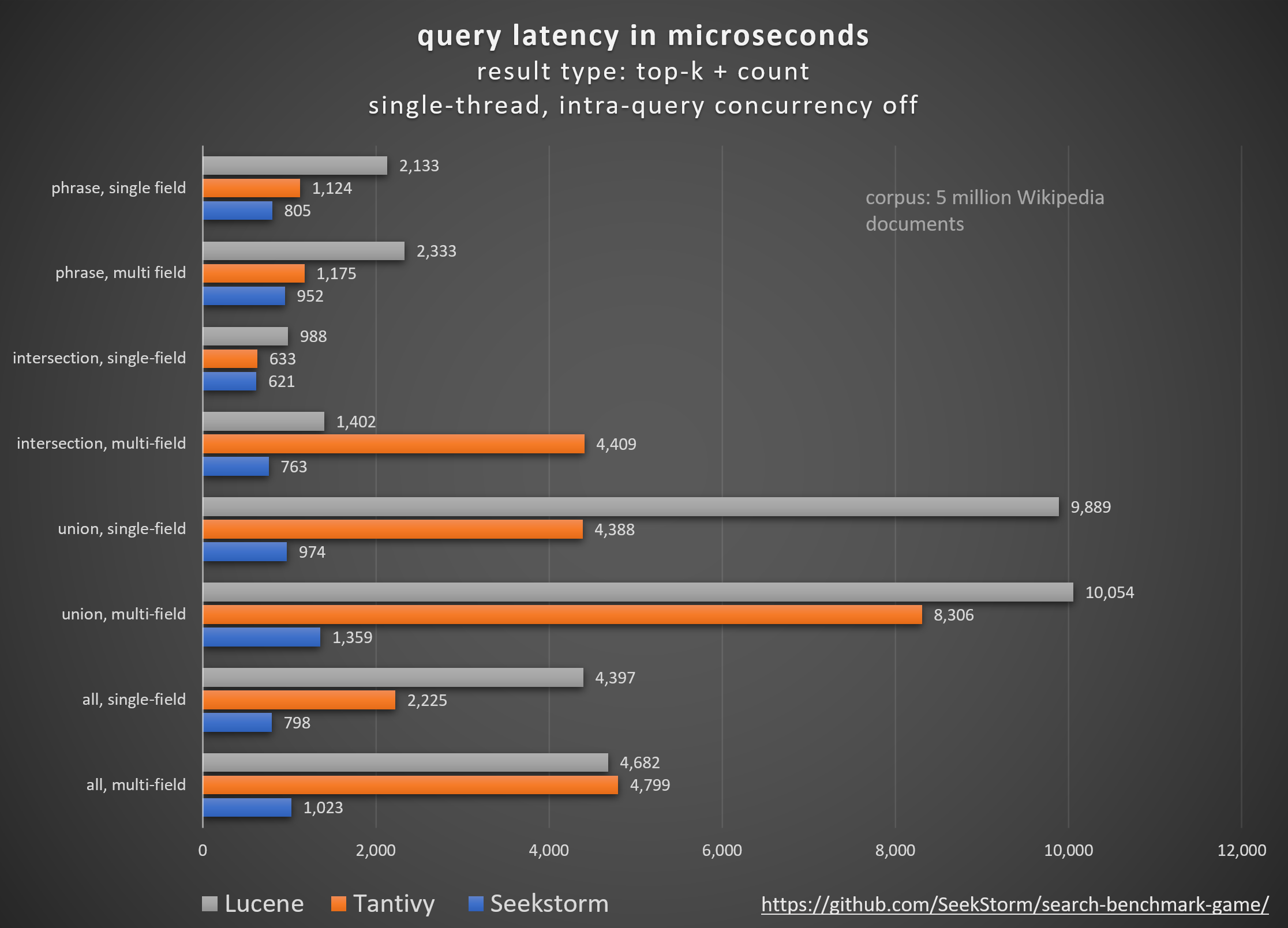
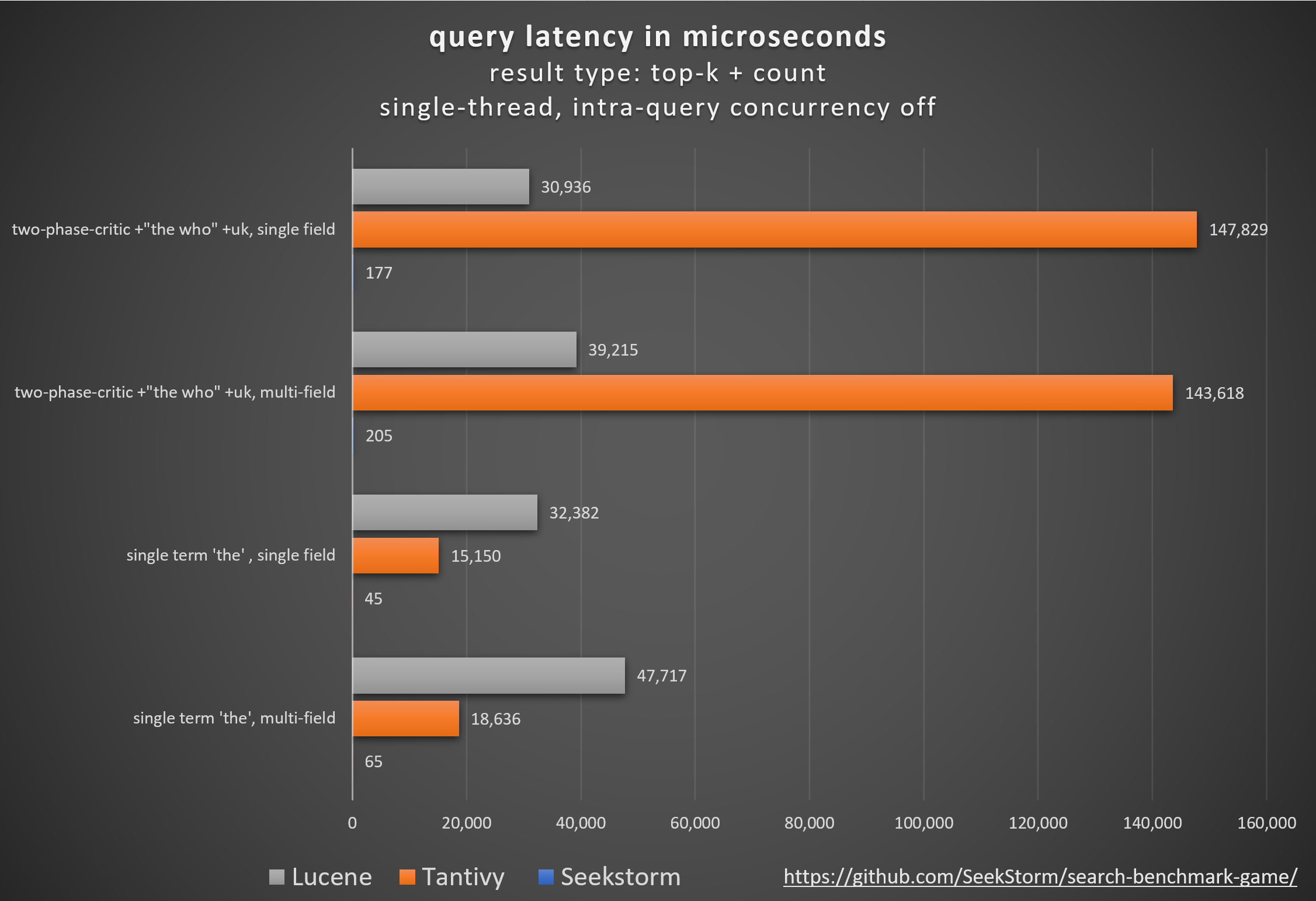
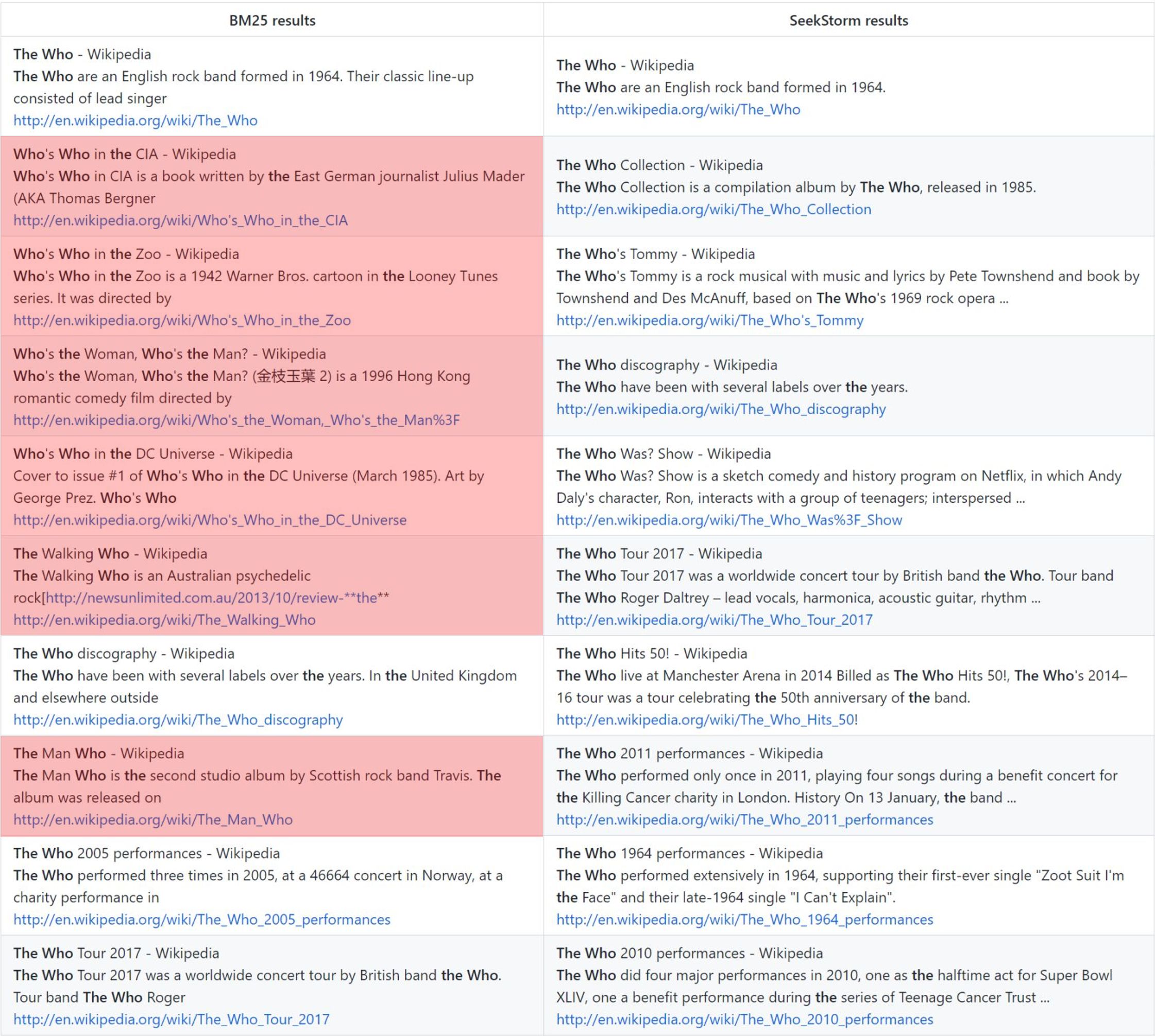
quién: clasificación básica de BM25 frente a clasificación de proximidad de SeekStorm
Metodología
Comparación de diferentes bibliotecas de motores de búsqueda de código abierto (búsqueda léxica BM25) utilizando el search_benchmark_game de código abierto desarrollado por Tantivy y Jason Wolfe.
Beneficios
Resultados de referencia detallados https://seekstorm.github.io/search-benchmark-game/
Repositorio de código de referencia https://github.com/SeekStorm/search-benchmark-game/
Consulte las publicaciones de nuestro blog para obtener información más detallada: SeekStorm ahora es de código abierto y SeekStorm obtiene búsqueda por facetas, búsqueda de proximidad geográfica y clasificación de resultados.
A pesar de lo que los ciclos publicitarios https://www.bitecode.dev/p/hype-cycles quieren hacerle creer, la búsqueda de palabras clave no está muerta, ya que NoSQL no fue la muerte de SQL.
Debe mantener una caja de herramientas y elegir la mejor herramienta para la tarea que tiene entre manos. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
La búsqueda de palabras clave es solo un filtro para un conjunto de documentos, que devuelve aquellos en los que aparecen determinadas palabras clave, generalmente combinado con una métrica de clasificación como BM25. Una funcionalidad muy básica y central, que resulta muy difícil de implementar a escala con baja latencia. Debido a que la funcionalidad es tan básica, existe una cantidad ilimitada de campos de aplicación. Es un componente que se utiliza junto con otros componentes. Hay casos de uso que se pueden resolver mejor hoy en día con la búsqueda vectorial y los LLM, pero para muchos más, la búsqueda de palabras clave sigue siendo la mejor solución. La búsqueda de palabras clave es exacta, sin pérdidas y muy rápida, con mejor escalado, mejor latencia, menor costo y consumo de energía. La búsqueda vectorial funciona con similitud semántica, devolviendo resultados con una proximidad y probabilidad determinadas.
Si busca resultados exactos como nombres propios, números, matrículas, nombres de dominio y frases (por ejemplo, detección de plagio), entonces la búsqueda de palabras clave es su amiga. La búsqueda vectorial, por otro lado, ocultará el resultado exacto que está buscando entre una miríada de resultados que sólo de alguna manera están relacionados semánticamente. Al mismo tiempo, si no conoce los términos exactos o está interesado en un tema, significado o sinónimo más amplio, sin importar qué términos exactos se utilicen, la búsqueda de palabras clave le fallará.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.La búsqueda vectorial es perfecta si no conoce los términos de consulta exactos o si está interesado en un tema, significado o sinónimo más amplio, sin importar qué términos de consulta exactos se utilicen. Pero si busca términos exactos, por ejemplo, nombres propios, números, matrículas, nombres de dominio y frases (por ejemplo, detección de plagio), entonces siempre debe utilizar la búsqueda por palabras clave. La búsqueda vectorial no hará más que ocultar el resultado exacto que está buscando entre una multitud de resultados que sólo están relacionados de alguna manera. Tiene una buena recuperación, pero baja precisión y mayor latencia. Es propenso a falsos positivos, por ejemplo, en la detección de plagio, ya que se pierden las palabras exactas y el orden de las mismas.
La búsqueda de vectores le permite buscar no solo texto similar, sino todo lo que se puede transformar en un vector: texto, imágenes (reconocimiento facial, huellas dactilares), audio y le permite hacer cosas mágicas como reina - mujer + hombre = rey .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationLa búsqueda vectorial no reemplaza la búsqueda de palabras clave, sino que es una adición complementaria ; es mejor utilizarla dentro de una solución híbrida donde se combinan las fortalezas de ambos enfoques. La búsqueda de palabras clave no está desactualizada, sino que está probada en el tiempo .
Hemos portado (parcialmente) el código base de SeekStorm de C# a Rust.
Rust es excelente para aplicaciones críticas para el rendimiento que manejan big data y/o muchos usuarios simultáneos. ¿Los algoritmos rápidos brillarán aún más con un lenguaje de programación centrado en el rendimiento?
ver ARQUITECTURA.md
cargo build --release
ADVERTENCIA : asegúrese de configurar la variable de entorno MASTER_KEY_SECRET en un secreto; de lo contrario, las claves API generadas se verán comprometidas.
https://docs.rs/seekstorm
Documentación de compilación
cargo doc --no-deps
Acceda a la documentación localmente
BuscarStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
Agregue las cajas requeridas a su proyecto
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;utilizar un tiempo de ejecución asincrónico de Rust
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {crear índice
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;abrir índice (alternativamente para crear índice)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; documentos indexados
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; comprometer documentos
index_arc . commit ( ) . await ;índice de búsqueda
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;mostrar resultados
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}búsqueda multiproceso
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}indexar archivos JSON en formato JSON, JSON delimitado por nuevas líneas y JSON concatenado
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;indexar todos los archivos PDF en directorios y subdirectorios
ingest de la consola): [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;indexar archivo PDF
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;indexar bytes de archivos PDF
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;obtener bytes de archivo PDF
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;borrar índice
index . clear_index ( ) ;eliminar índice
index . delete_index ( ) ;cerrar índice
index . close_index ( ) ;cadena de versión de la biblioteca seekstorm
let version= version ( ) ;
println ! ( "version {}" ,version ) ;Las facetas se definen en 3 lugares diferentes:
Un ejemplo funcional mínimo de indexación y búsqueda por facetas requiere solo 60 líneas de código. Pero descifrarlo todo a partir únicamente de la documentación puede resultar tedioso. Es por eso que proporcionamos aquí un ejemplo de inicio rápido:
Agregue las cajas requeridas a su proyecto
cargo add seekstorm
cargo add tokio
cargo add serde_jsonAgregar declaraciones de uso
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;utilizar un tiempo de ejecución asincrónico de Rust
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {crear índice
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;documentos indexados
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; confirmar documentos
index_arc . commit ( ) . await ;índice de búsqueda
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;mostrar resultados
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}mostrar facetas
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;fin de la función principal
Ok ( ( ) )
} Un rápido tutorial paso a paso sobre cómo crear un motor de búsqueda de Wikipedia a partir de un corpus de Wikipedia utilizando el servidor SeekStorm en 5 sencillos pasos.

Descargar SeekStorm
Descarga SeekStorm desde el repositorio de GitHub
Descomprímalo en el directorio de su elección y ábralo en código de Visual Studio.
o alternativamente
git clone https://github.com/SeekStorm/SeekStorm.git
Construir SeekStorm
Instale Rust (si aún no está presente): https://www.rust-lang.org/tools/install
En la terminal de Visual Studio Code escriba:
cargo build --release
Obtener el corpus de Wikipedia
Corpus preprocesado de Wikipedia en inglés (5.032.105 documentos, 8,28 GB descomprimidos). Aunque wiki-articles.json tiene una extensión .JSON, no es un archivo JSON válido. Es un archivo de texto, donde cada línea contiene un objeto JSON con atributos de URL, título y cuerpo. El formato se llama ndjson ("JSON delimitado por nuevas líneas").
Descargar el corpus de Wikipedia
Descomprimir el corpus de Wikipedia.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
Mueva el wiki-articles.json descomprimido al directorio de lanzamiento
Iniciar el servidor SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indexación
Escriba 'ingest' en la línea de comando del servidor SeekStorm en ejecución:
ingest
Esto crea el índice de demostración e indexa el archivo de Wikipedia local.
Comience a buscar dentro de la WebUI integrada
Abra la interfaz de usuario web integrada en el navegador: http://127.0.0.1
Ingrese una consulta en el cuadro de búsqueda
Prueba de los puntos finales de la API REST
Abra src/seekstorm_server/test_api.rest en VSC junto con la extensión VSC "Rest client" para ejecutar llamadas API e inspeccionar respuestas
ejemplos de puntos finales de API interactivos
Establezca la 'clave de API individual' en test_api.rest en la clave de API que se muestra en la consola del servidor cuando escribió 'índice' arriba.
Eliminar índice de demostración
Escriba 'eliminar' en la línea de comando del servidor SeekStorm en ejecución:
delete
Apagar servidor
Escriba 'salir' en la línea de comando del servidor SeekStorm en ejecución.
quit
Personalización
¿Quieres utilizar algo similar para tu propio proyecto? Eche un vistazo a la documentación de ingesta y de interfaz de usuario web.
Un rápido tutorial paso a paso sobre cómo crear un motor de búsqueda de PDF a partir de un directorio que contiene archivos PDF utilizando el servidor SeekStorm.
Haga que todos sus artículos científicos, libros electrónicos, currículums, informes, contratos, documentación, manuales, cartas, extractos bancarios, facturas y albaranes se puedan buscar, en casa o en su organización.
Construir SeekStorm
Instale Rust (si aún no está presente): https://www.rust-lang.org/tools/install
En la terminal de Visual Studio Code escriba:
cargo build --release
Descargar PDFio
Descargue y copie la biblioteca Pdfium en la misma carpeta que seekstorm_server.exe: https://github.com/bblanchon/pdfium-binaries
Iniciar el servidor SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indexación
Elija un directorio que contenga archivos PDF que desee indexar y buscar, por ejemplo, sus documentos o directorio de descargas.
Escriba 'ingest' en la línea de comando del servidor SeekStorm en ejecución:
ingest C:UsersJohnDoeDownloads
Esto crea pdf_index e indexa todos los archivos PDF del directorio especificado, incluidos los subdirectorios.
Comience a buscar dentro de la WebUI integrada
Abra la interfaz de usuario web integrada en el navegador: http://127.0.0.1
Ingrese una consulta en el cuadro de búsqueda
Eliminar índice de demostración
Escriba 'eliminar' en la línea de comando del servidor SeekStorm en ejecución:
delete
Apagar servidor
Escriba 'salir' en la línea de comando del servidor SeekStorm en ejecución.
quit
Búsqueda de texto completo en 30 millones de publicaciones de Hacker News Y páginas web vinculadas
DeepHN.org
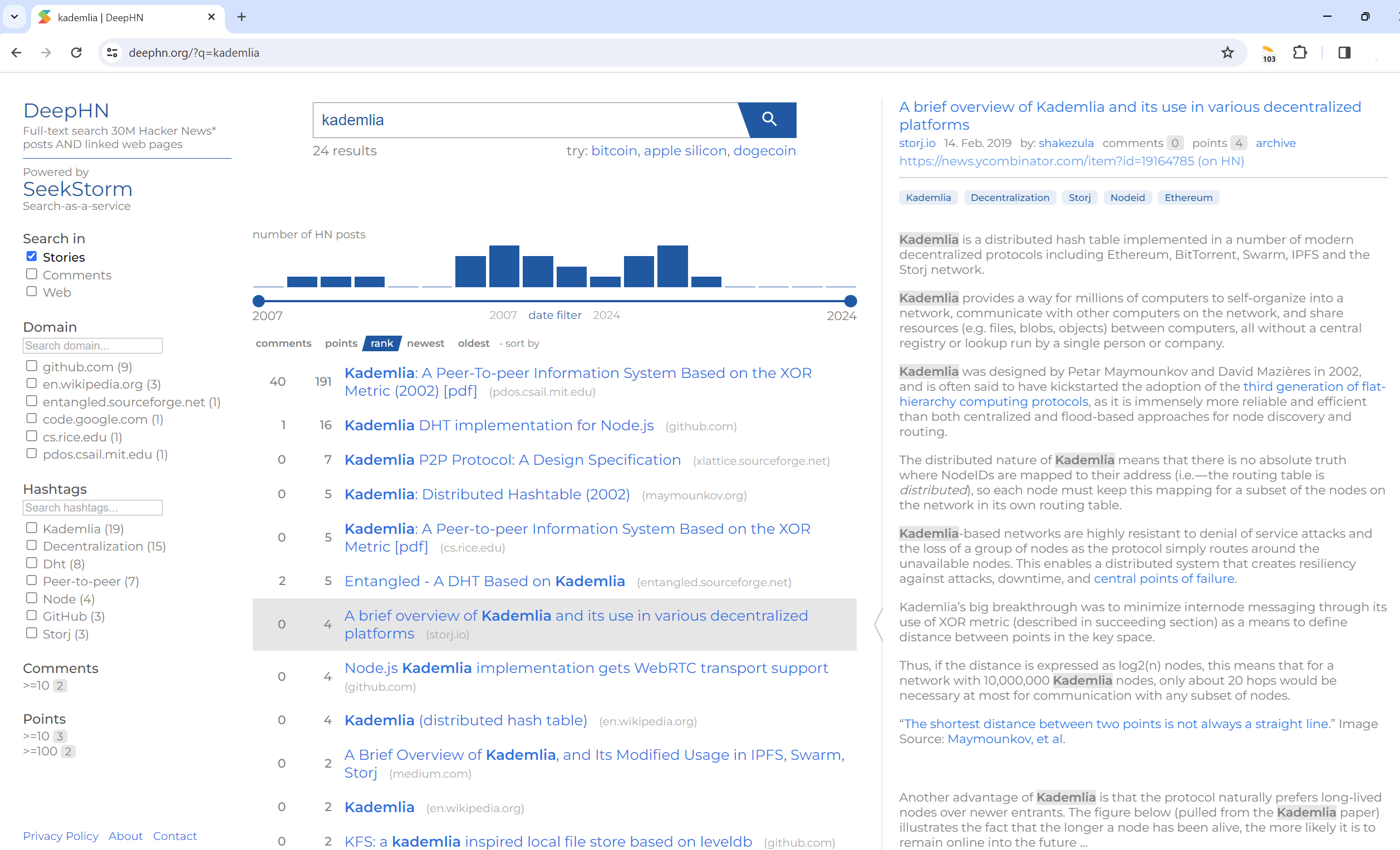
La demostración de DeepHN todavía se basa en el código base de SeekStorm C#.
Actualmente estamos transfiriendo todas las funciones faltantes requeridas.
Consulte la hoja de ruta a continuación.
El port de Rust aún no tiene todas las funciones. Las siguientes características están actualmente portadas.
Portabilidad
Mejoras
Nuevas características


