elastic_transformers
1.0.0
Elasticsearch semántica con transformadores de oraciones. Usaremos el poder de Elastic y la magia de BERT para indexar un millón de artículos y realizar búsquedas léxicas y semánticas sobre ellos.
El propósito es proporcionar una forma fácil de usar para configurar su propio Elasticsearch con capacidades casi de última generación de incrustaciones contextuales/búsqueda semántica utilizando transformadores de PNL.
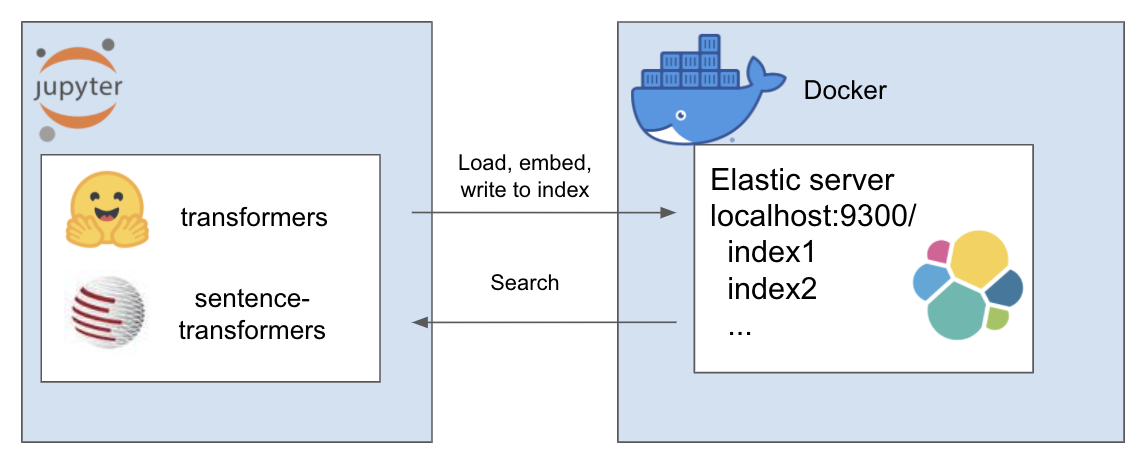
La configuración anterior funciona de la siguiente manera
Mi entorno se llama et y uso conda para esto. Navegar dentro del directorio del proyecto
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtPara este tutorial estoy usando A Million News Headlines de Rohk y lo coloco en la carpeta de datos dentro del directorio del proyecto.
elastic_transformers/
├── data/
Descubrirá que, por lo demás, los pasos son bastante abstractos, por lo que también puede hacerlo con el conjunto de datos que elija.
Siga las instrucciones sobre cómo configurar Elastic con Docker desde la página de Elastic aquí. Para este tutorial, solo necesita ejecutar los dos pasos:
El repositorio presenta la clase ElasiticTransformers. Utilidades que ayudan a crear, indexar y consultar índices de Elasticsearch que incluyen incrustaciones.
Inicie los enlaces de conexión así como (opcionalmente) el nombre del índice con el que trabajar
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec define la asignación para el índice. Se pueden proporcionar listas de campos relevantes para búsqueda de palabras clave o búsqueda semántica (vectorial denso). También tiene parámetros para el tamaño del vector denso, ya que pueden variar. create_index : utiliza la especificación creada anteriormente para crear un índice listo para la búsqueda.
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv : divide un archivo csv grande en fragmentos y utiliza de forma iterativa una utilidad de incrustación predefinida para crear la lista de incrustaciones para cada fragmento y posteriormente alimentar los resultados al índice.
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )búsqueda : permite seleccionar una búsqueda por palabra clave ('coincidencia' en Elastic) o semántica (densa en Elastic). En particular, requiere la misma función de incrustación utilizada en write_large_csv.
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )Después de una configuración exitosa, use los siguientes cuadernos para que todo esto funcione
Este repositorio combina los siguientes trabajos increíbles de personas brillantes. Por favor, mira su trabajo si aún no lo has hecho...


