VSA
1.0.0
[Página del proyecto] [?Papel] [?Hugging Face Space] [Model Zoo] [Introducción] [?Video]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
La demostración local está basada en gradio y puedes ejecutarla simplemente con:
python app.py
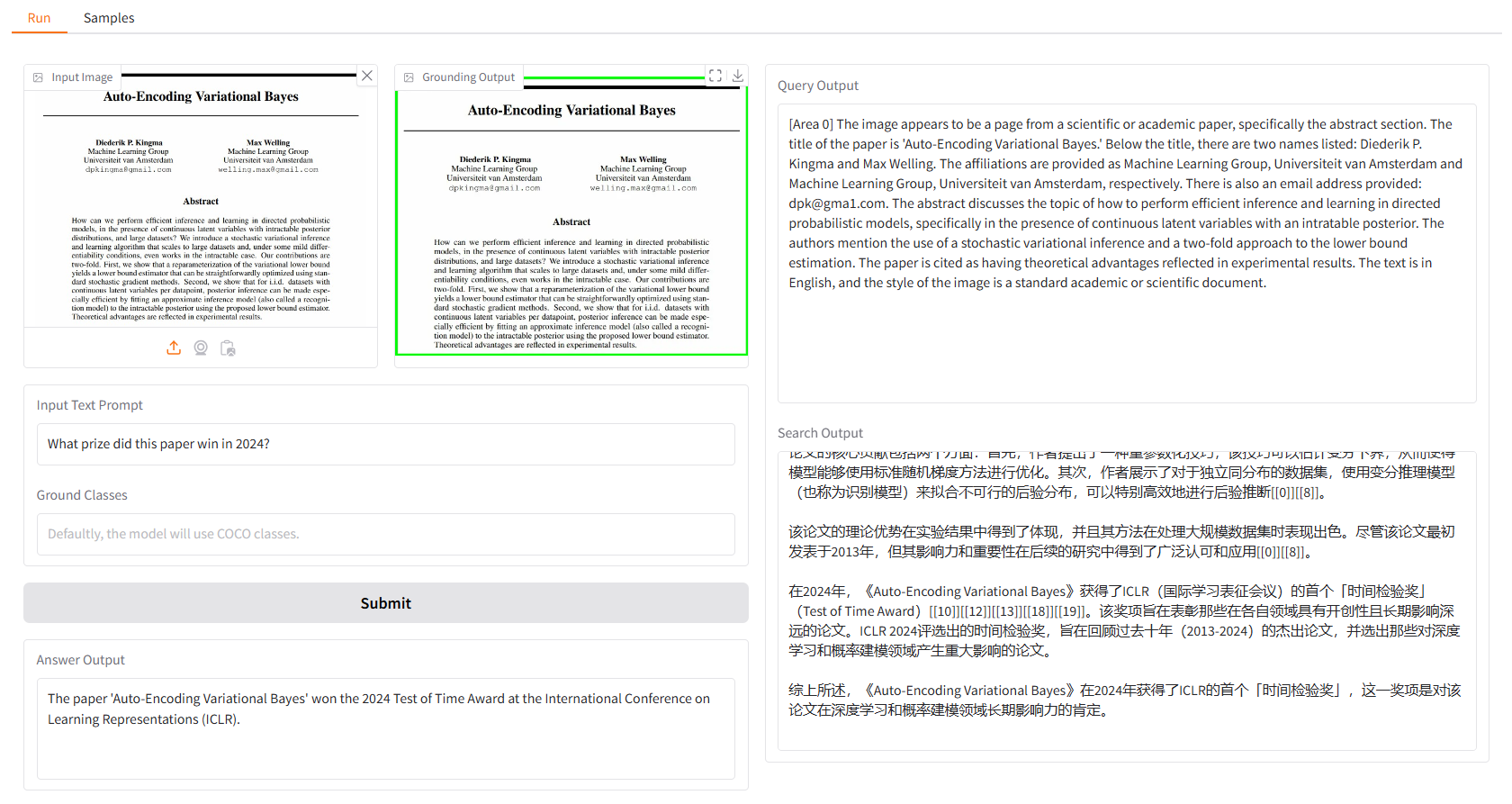
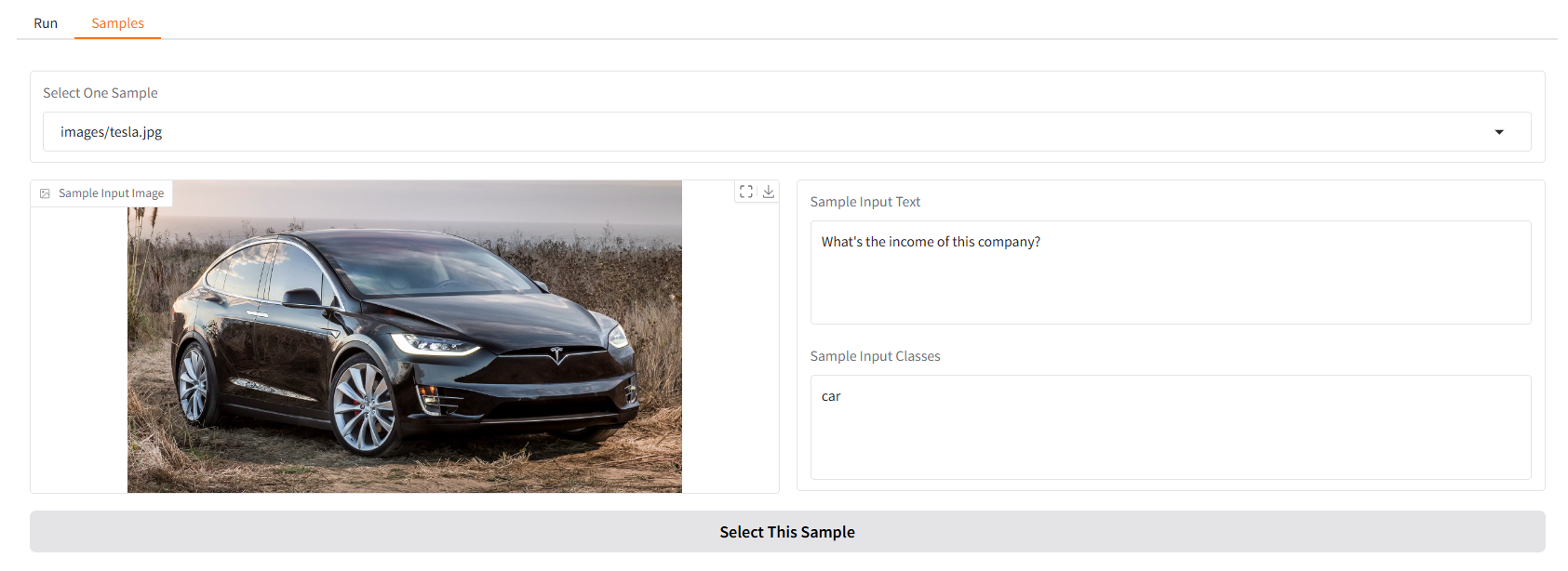
Le proporcionamos algunas muestras para que comience. En la interfaz de usuario "Muestras", puede seleccionar una en el panel "Muestras", hacer clic en "Seleccionar esta muestra" y verá que la entrada de muestra ya se ha completado en la interfaz de usuario "Ejecutar".
También puedes chatear con nuestro Asistente de búsqueda de visión en la terminal ejecutando.
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
Luego, seleccione una imagen y escriba su pregunta.
Este proyecto se publica bajo la licencia Apache 2.0.
Vision Search Assistant está muy inspirado en las siguientes contribuciones destacadas a la comunidad de código abierto: GroundingDINO, LLaVA, MindSearch.
Si encuentra útil este proyecto en su investigación, considere citar:
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


