cyac
1.0.0
Herramienta de reemplazo y coincidencia de palabras clave y Trie de alto rendimiento.
Está implementado por cython y se compilará en cpp. La estructura de datos trie es cedro, que es un trie de doble matriz optimizado. es compatible con Python2.7 y 3.4+. Soporta encurtidos para volcar y cargar.
Si esto te resultó útil, ¡dale una estrella!
Este módulo está escrito en cython. Necesitas instalar Cython.
pip install cyac
Luego crea un Trie
>>> from cyac import Trie
>>> trie = Trie()
agregar/obtener/eliminar palabra clave
>>> trie.insert(u"哈哈") # return keyword id in trie, return -1 if doesn't exist
>>> trie.get(u"哈哈") # return keyword id in trie, return -1 if doesn't exist
>>> trie.remove(u"呵呵") # return keyword in trie
>>> trie[id] # return the word corresponding to the id
>>> trie[u"呵呵"] # similar to get but it will raise exeption if doesn't exist
>>> u"呵呵" in trie # test if the keyword is in trie
obtener todas las palabras clave
>>> for key, id_ in trie.items():
>>> print(key, id_)
prefijo/predecir
>>> # return the string in the trie which starts with given string
>>> for id_ in trie.predict(u"呵呵"):
>>> print(id_)
>>> # return the prefix of given string which is in the trie.
>>> for id_, len_ in trie.prefix(u"呵呵"):
>>> print(id_, len_)
intentar extraer, reemplazar
>>> python_id = trie.insert(u"python")
>>> trie.replace_longest("python", {python_id: u"hahah"}, set([ord(" ")])) # the second parameter is seperator. If you specify seperators. it only matches strings tween seperators. e.g. It won't match 'apython'
>>> for id_, start, end in trie.match_longest(u"python", set([ord(" ")])):
>>> print(id_, start, end)
Extracto de Aho Corasick
>>> ac = AC.build([u"python", u"ruby"])
>>> for id, start, end in ac.match(u"python ruby"):
>>> print(id, start, end)
Exportar a archivo, luego podemos usar mmap para cargar archivos y compartir datos entre procesos.
>>> ac = AC.build([u"python", u"ruby"])
>>> ac.save("filename")
>>> ac.to_buff(buff_object)
Iniciar desde el búfer de Python
>>> import mmap
>>> with open("filename", "r+b") as bf:
buff_object = mmap.mmap(bf.fileno(), 0)
>>> AC.from_buff(buff_object, copy=True) # it allocs new memory
>>> AC.from_buff(buff_object, copy=False) # it shares memory
Ejemplo de multiproceso
import mmap
from multiprocessing import Process
from cyac import AC
def get_mmap():
with open("random_data", "r+b") as bf:
buff_object = mmap.mmap(bf.fileno(), 0)
ac_trie = AC.from_buff(buff_object, copy=False)
# Do your aho searches here. "match" function is process safe.
processes_list = list()
for x in range(0, 6):
p = Process(
target=get_mmap,
)
p.start()
processes_list.append(p)
for p in processes_list:
p.join()
Para obtener más información sobre multiprocesamiento y análisis de memoria en cyac, consulte este número.
La función "match" del autómata AC es segura para subprocesos y procesos. Es posible encontrar coincidencias en paralelo con un autómata AC compartido, pero no escribirle ni agregarle patrones.
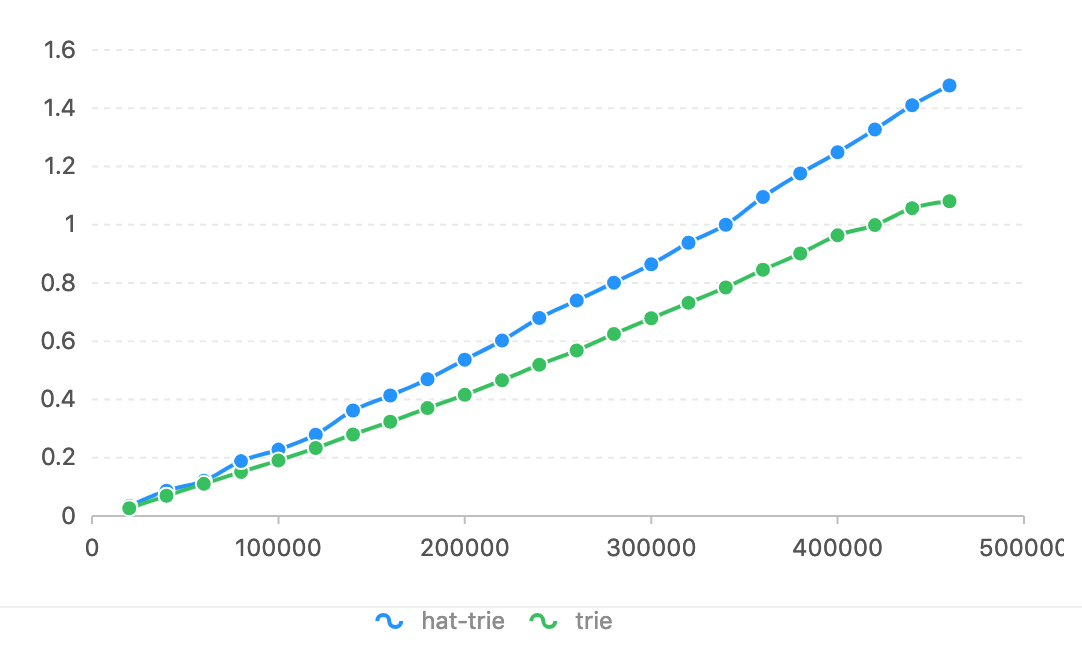
En Ubuntu 14.04.5/CPU Intel(R) Core(TM) i7-4790K a 4,00 GHz.
En comparación con HatTrie, el eje del horizonte es el número de token. El eje vertical se utiliza el tiempo (segundos).
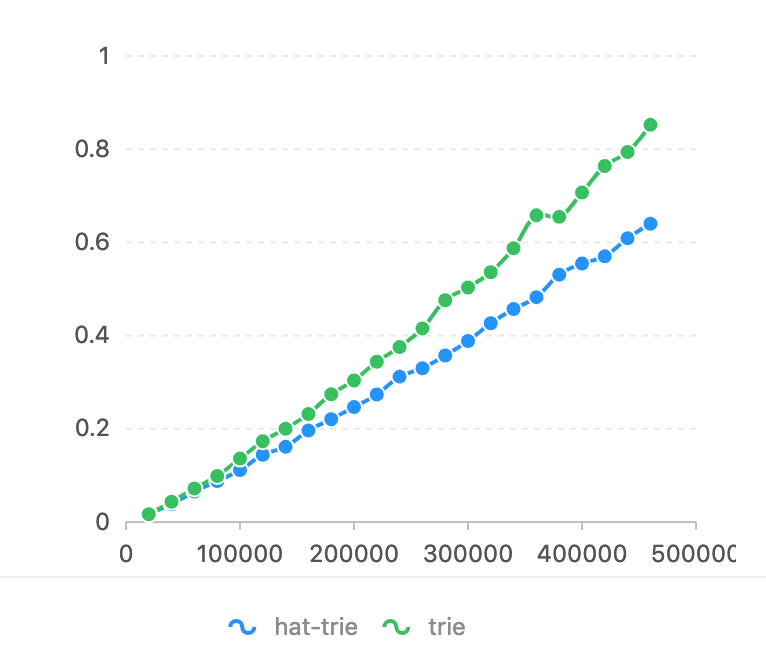
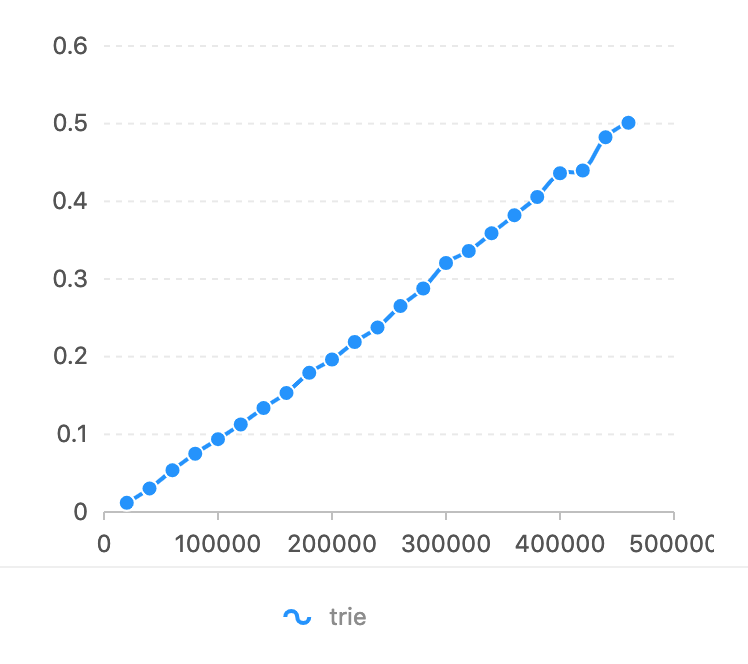
Comparado con flashText. La expresión regular es demasiado lenta en esta tarea (consulte la prueba comparativa de flashText). El eje del horizonte es el número de caracteres que debe coincidir. El eje vertical se utiliza el tiempo (segundos).
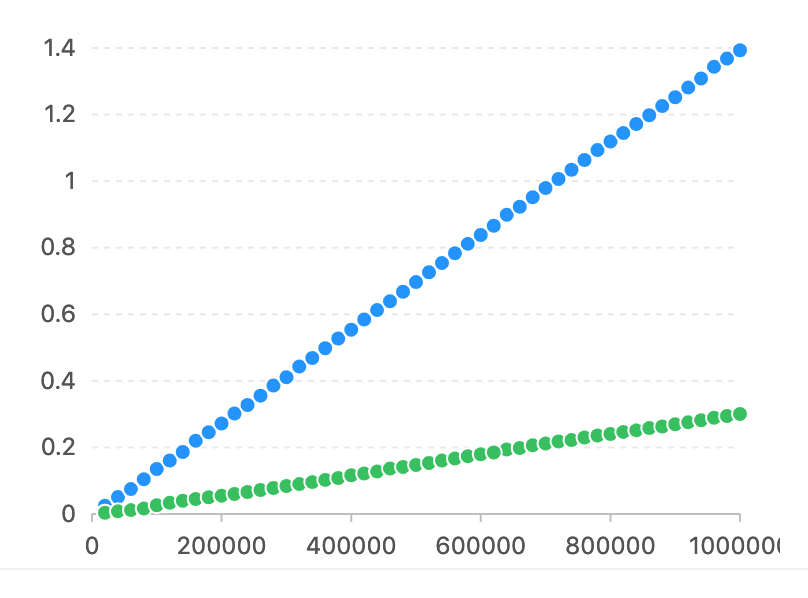
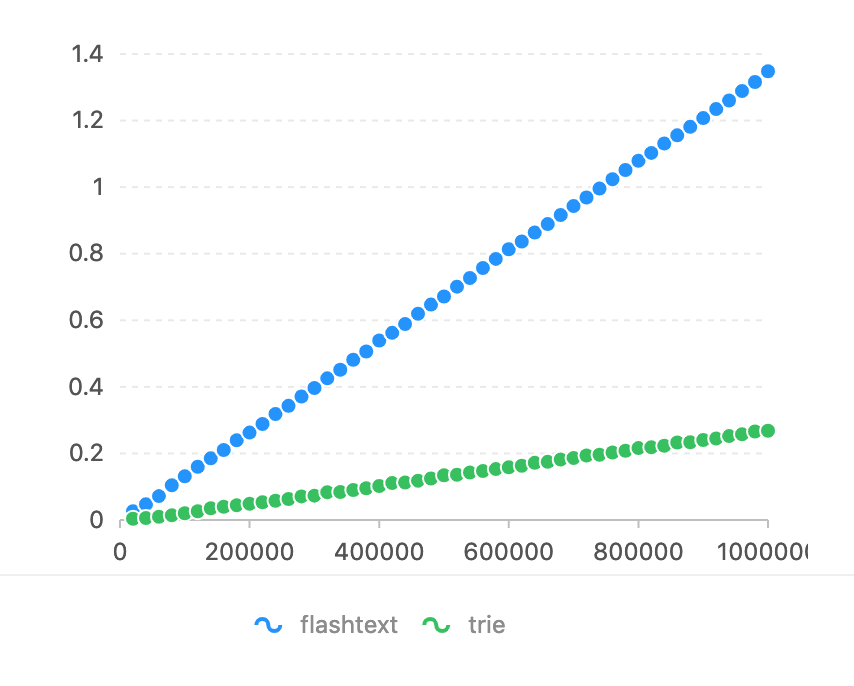
En comparación con pyahocorasick, el eje Horizon tiene un número de caracteres que coincide. El eje vertical se utiliza el tiempo (segundos). 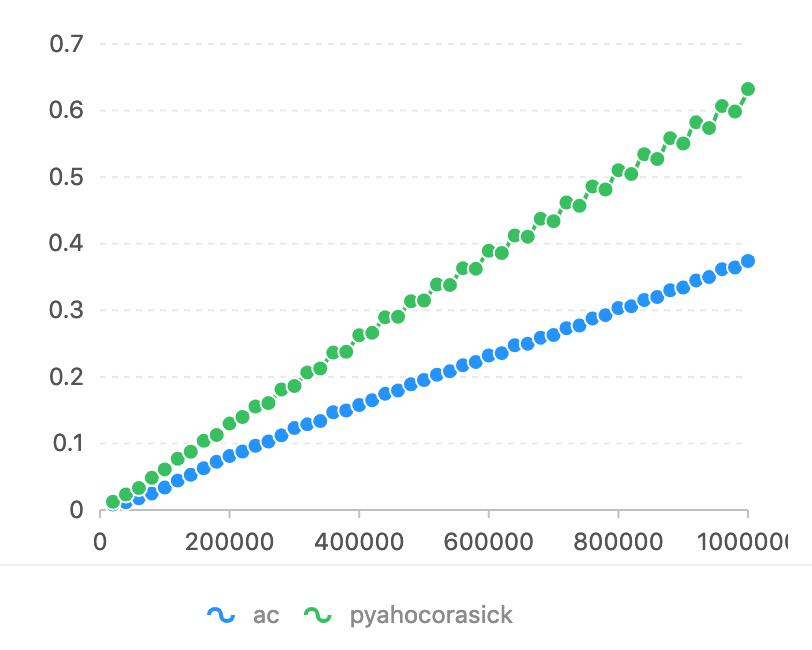
>>> len(char.lower()) == len(char) # this is always true in python2, but not in python3
>>> len(u"İstanbul") != len(u"İstanbul".lower()) # in python3
En caso de coincidencias que no distinguen entre mayúsculas y minúsculas, esta biblioteca se encarga del hecho y devuelve el desplazamiento correcto.
python setup.py build
PYTHONPATH= $( pwd ) /build/BUILD_DST python3 tests/test_all.py
PYTHONPATH= $( pwd ) /build/BUILD_DST python3 bench/bench_ * .py

