ndvr
1.0.0
¿Segundo puesto en el Hackathon de búsqueda neuronal?
Hemos sido testigos de un crecimiento explosivo de datos de video en una variedad de sitios web para compartir videos con miles de millones de videos disponibles en Internet; realizar la recuperación de videos casi duplicados (NDVR) a partir de una base de datos de videos a gran escala se convierte en un desafío importante. NDVR tiene como objetivo recuperar videos casi duplicados de una base de datos de videos masiva, donde los videos casi duplicados se definen como videos visualmente cercanos a los videos originales.
Los usuarios tienen un fuerte incentivo para copiar un video corto de tendencia y cargar una versión aumentada para llamar la atención. Con el crecimiento de los vídeos cortos, aparecen nuevas dificultades y desafíos para detectar vídeos cortos casi duplicados.
Aquí, hemos creado una solución de búsqueda neuronal utilizando Jina para resolver el desafío de NDVR.
Tabla de contenido

Ejemplo de vídeos de candidatos positivos. Fila superior: tapizado lateral, filtrado de color y lavado con agua. Fila central: pantalla horizontal cambiada a pantalla vertical con grandes márgenes negros. Fila inferior: girada
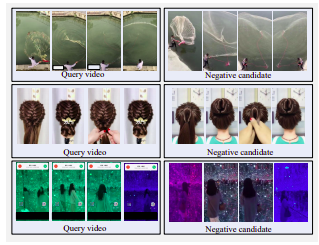
Ejemplo de vídeos negativos duros. Todos los candidatos son visualmente similares a la consulta, pero no están casi duplicados.
Hay tres estrategias para seleccionar videos candidatos:
Decidimos optar por la estrategia de recuperación transformada debido a la limitación de tiempo y recursos. En aplicaciones reales, los usuarios copiarían videos de tendencia como incentivos personales. Los usuarios suelen optar por modificar ligeramente sus vídeos copiados para evitar la detección. Estas modificaciones incluyen recorte de vídeo, inserción de bordes, etc.
Para imitar dicho comportamiento del usuario, definimos una transformación temporal, es decir, aceleración del video, y tres transformaciones espaciales, es decir, recorte de video, inserción de borde negro y rotación de video.
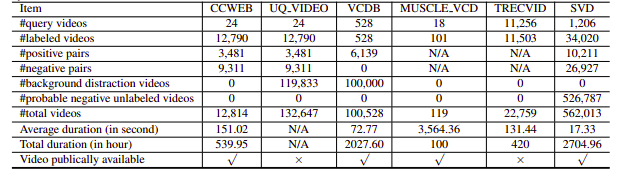
Desafortunadamente, los conjuntos de datos de NDVR investigados eran de baja resolución o enormes, específicos de un dominio o no estaban disponibles públicamente (también contactamos a algunos personalmente). Por lo tanto, decidimos crear nuestro pequeño conjunto de datos personalizado para experimentar.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexEl índice Flujo se define de la siguiente manera:
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueEsto se divide en los siguientes pasos:
Aquí usamos un archivo YAML para definir un flujo y usarlo para indexar los datos. La función index toma un parámetro input_fn que requiere un iterador para pasar rutas de archivos, que se incluirán en una IndexRequest y se enviarán al flujo.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query Luego puede abrir Jinabox con el punto final personalizado http://localhost:45678/api/search
El flujo de consulta se define de la siguiente manera:
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlEl flujo de consulta se divide en los siguientes pasos:


