omochi
1.0.0

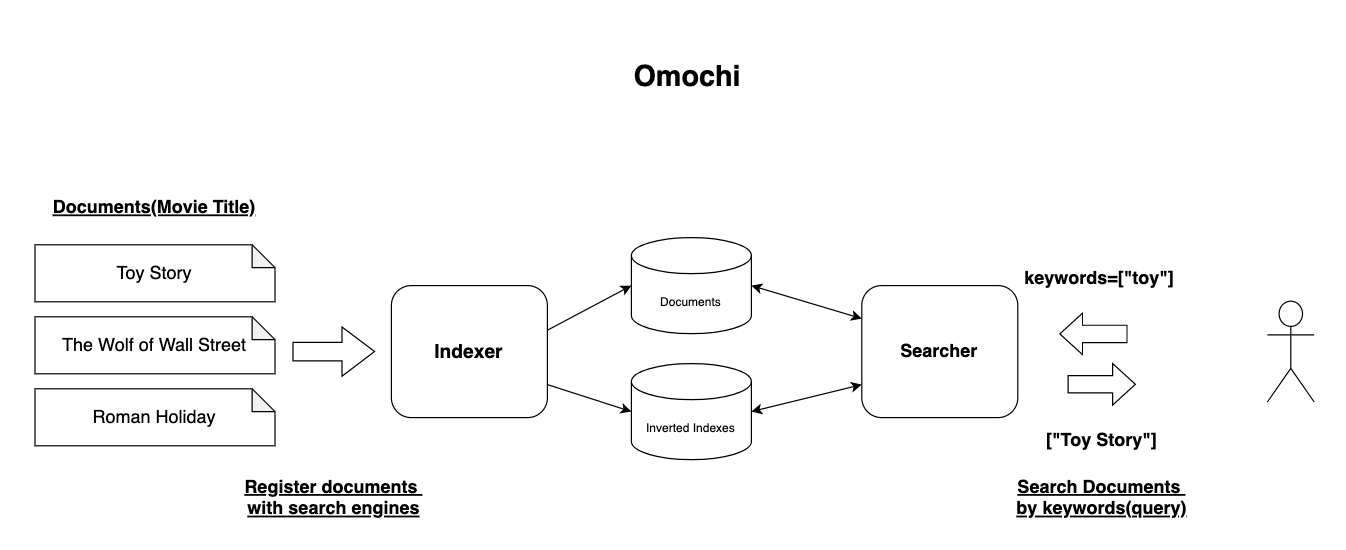
Motor de búsqueda de texto completo desde cero por Golangʕ◔ϖ◔ʔ (Solo un juguete)
Cree una red acoplable (omochi_network) mediante:
$ docker network create omochi_network
Omochi usa MariaDB para almacenar índices y documentos invertidos y Ent para ORM.
Para la migración de la base de datos, conecte el shell del contenedor Docker mediante:
$ docker-compose run api bash
Luego, ejecutando la migración de la base de datos mediante:
$ go run ./cmd/migrate/migrate.go
Para probar el motor de búsqueda, este proyecto proporciona dos conjuntos de datos como ejemplos en formato TSV.
El conjunto de datos para inglés es un conjunto de datos de títulos de películas y el conjunto de datos para japonés es un conjunto de datos de títulos de cómics de Doraemon .
Al principio, conecte el shell del contenedor Docker mediante:
$ docker-compose run api bash
Luego, sembrar datos por:
$ go run {path to seed.go}
Si inicializa con un conjunto de datos japonés, {path to seed.go} debe ser ./cmd/seeds/ja/seed.go . Por otro lado, para inglés, ./cmd/seeds/eng/seed.go .
Después de completar la configuración, puede iniciar la aplicación ejecutando:
$ docker-compose up
Esta aplicación inicia una API RESTful y escucha en el puerto 8081 las conexiones
Después de inicializar los datos, puede buscar documentos enviando una solicitud GET a /v1/document/search .
Los parámetros de consulta son los siguientes:
"keywords" : Palabras clave para buscar. Si hay varios términos de búsqueda, especifíquelos separados por comas como "hoge,fuga,piyo""mode" : modo de búsqueda. Los modos de búsqueda que se pueden especificar son "And" y "Or" Después de sembrar datos mediante el conjunto de datos de títulos de cómics de Doraemon , puede buscar documentos que incluyan "ドラえもん" mediante:
$ curl "http://localhost:8081/v1/document/search?keywords=ドラえもん" | jq .
{
"documents": [
{
"id": 12054,
"content": "ドラえもんの歌",
"tokenized_content": [
"ドラえもん",
"歌"
],
"created_at": "2022-07-08T12:59:49+09:00",
"updated_at": "2022-07-08T12:59:49+09:00"
},
{
"id": 11992,
"content": "恋するドラえもん",
"tokenized_content": [
"恋する",
"ドラえもん"
],
"created_at": "2022-07-08T12:59:48+09:00",
"updated_at": "2022-07-08T12:59:48+09:00"
},
{
"id": 11230,
"content": "ドラえもん登場!",
"tokenized_content": [
"ドラえもん",
"登場"
],
"created_at": "2022-07-08T12:59:44+09:00",
"updated_at": "2022-07-08T12:59:44+09:00"
},
...
Después de sembrar datos por conjunto de datos de título de película , puede buscar documentos que incluyan "juguete" e "historia" mediante:
$ curl "http://localhost:8081/v1/document/search?keywords=toy,story&mode=And" | jq .
{
"documents": [
{
"id": 1,
"content": "Toy Story",
"tokenized_content": [
"toy",
"story"
],
"created_at": "2022-07-08T13:49:24+09:00",
"updated_at": "2022-07-08T13:49:24+09:00"
},
{
"id": 39,
"content": "Toy Story of Terror!",
"tokenized_content": [
"toy",
"story",
"terror"
],
"created_at": "2022-07-08T13:49:34+09:00",
"updated_at": "2022-07-08T13:49:34+09:00"
},
{
"id": 83,
"content": "Toy Story That Time Forgot",
"tokenized_content": [
"toy",
"story",
"time",
"forgot"
],
"created_at": "2022-07-08T13:49:53+09:00",
"updated_at": "2022-07-08T13:49:53+09:00"
},
{
"id": 213,
"content": "Toy Story 2",
"tokenized_content": [
"toy",
"story"
],
"created_at": "2022-07-08T13:50:35+09:00",
"updated_at": "2022-07-08T13:50:35+09:00"
},
{
"id": 352,
"content": "Toy Story 3",
"tokenized_content": [
"toy",
"story"
],
"created_at": "2022-07-08T13:51:23+09:00",
"updated_at": "2022-07-08T13:51:23+09:00"
}
]
}
MIT


