CrawlerTutorial
1.0.0
Cuando navegamos por Internet, a menudo vemos una variedad de contenidos interesantes, como noticias, productos, vídeos, imágenes, etc. Pero si desea recopilar una gran cantidad de información específica de estas páginas web, las operaciones manuales llevarán mucho tiempo y serán laboriosas.
¡En este momento, el rastreador web (Web Crawler) es útil! En pocas palabras, un rastreador web es un programa que puede imitar el comportamiento de un navegador humano y rastrear automáticamente información web. Utilizando las capacidades de automatización de este programa, podemos "rastrear" fácilmente los datos que nos interesan del sitio web y luego almacenarlos para análisis futuros.
La forma en que suele funcionar un rastreador web es enviar primero una solicitud HTTP al sitio web de destino, luego obtener la respuesta HTML del sitio web, analizar el contenido de la página y luego extraer datos útiles. Por ejemplo, si queremos recopilar el título, el autor, la hora y otra información de los artículos en el foro de chismes de PTT, podemos utilizar la tecnología de rastreo web para capturar automáticamente esta información y almacenarla. De esta manera podrá obtener la información que necesita sin tener que navegar manualmente por el sitio web.
Los rastreadores web tienen muchas aplicaciones prácticas, como por ejemplo:
Por supuesto, cuando utilizamos rastreadores web, debemos cumplir con los términos de uso y la política de privacidad del sitio web y no podemos rastrear información que viole las regulaciones del sitio web. Al mismo tiempo, para garantizar el funcionamiento normal del sitio web, también debemos diseñar estrategias de rastreo adecuadas para evitar una carga excesiva en el sitio web.
Este tutorial utiliza Python3 y utilizará pip para instalar los paquetes necesarios. Es necesario instalar los siguientes paquetes:
requests : se utiliza para enviar y recibir solicitudes y respuestas HTTP.requests_html : utilizado para analizar y rastrear elementos en HTML.rich : Deje que la información se envíe a la consola de manera hermosa, como mostrar una hermosa tabla.lxml o PyQuery : se utiliza para analizar elementos en HTML.Utilice las siguientes instrucciones para instalar estos paquetes:
pip install requests requests_html rich lxml PyQueryEn el capítulo básico, presentaremos brevemente cómo recopilar información de la página web de PTT, como el título del artículo, el autor y la hora.
¡Utilicemos los artículos de lectura de versiones de PTT como objetivos de nuestro rastreador!
Al rastrear una página web, utilizamos la función requests.get() para simular que el navegador envía una solicitud HTTP GET para "navegar" la página web. Esta función devolverá un objeto requests.Response , que contiene el contenido de respuesta de la página web. Sin embargo, cabe señalar que este contenido se presenta en forma de código fuente de texto puro y el navegador no lo representa. Podemos obtenerlo a través de la propiedad response.text .
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )
En usos posteriores, necesitaremos usar requests_html para expandir requests Además de navegar como un navegador, también necesitaremos analizar las páginas web HTML. requests_html empaquetará el código fuente de texto sin formato en response.text para requests_html.HTML uso posterior. Reescribir también es muy simple. Utilice session.get() para reemplazar el requests.get() anterior.
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )Sin embargo, cuando intentamos aplicar este método a Gossiping, podemos encontrarnos con errores. Esto se debe a que cuando navegamos por el foro de chismes por primera vez, el sitio web confirmará si somos mayores de 18 años cuando hagamos clic para confirmar, el navegador registrará las cookies correspondientes para que no nos vuelva a preguntar la próxima vez; ingresa nuevamente (puedes intentar usar el modo incógnito para abrir la prueba y echar un vistazo a la página de inicio del tablero de Bagua). Sin embargo, para los rastreadores web, debemos registrar esta cookie especial para que podamos fingir que hemos pasado la prueba de los dieciocho años mientras navegamos.
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) A continuación, podemos usar el método response.html.find() para ubicar el elemento y usar el selector CSS para especificar el elemento de destino. En este paso podemos observar que en la versión web PTT, la información del título de cada artículo se ubica en una etiqueta div con una categoría r-ent . Por lo tanto, podemos utilizar el selector CSS div.r-ent para apuntar a estos elementos.
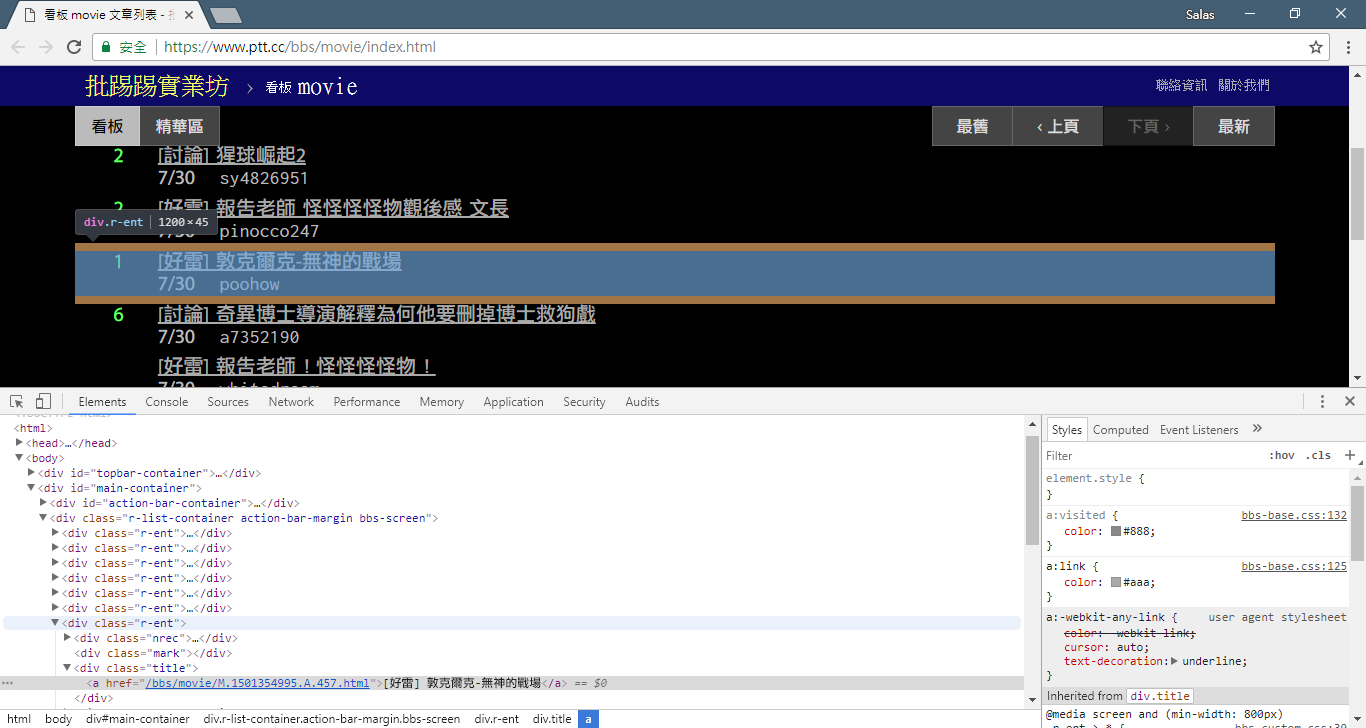
El uso del método response.html.find() devolverá una lista de elementos que cumplen las condiciones, por lo que podemos usar for para procesar estos elementos uno por uno. Dentro de cada elemento, podemos usar element.find() para analizar aún más el elemento y usar selectores CSS para especificar la información a extraer. En este ejemplo, podemos usar el selector CSS div.title para apuntar al elemento de título. Asimismo, podemos utilizar la propiedad element.text para obtener el contenido de texto de un elemento.
Aquí hay un código de muestra usando requests_html :
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... En el paso anterior, utilizamos el método response.html.find() para localizar los elementos de cada artículo. Estos elementos se seleccionan mediante el selector CSS div.r-ent . Puede utilizar la función Herramientas de desarrollador para observar la estructura de elementos de una página web. Después de abrir la página web y presionar la tecla F12, se mostrará un panel de herramientas para desarrolladores, que contiene la estructura HTML de la página web y otra información.
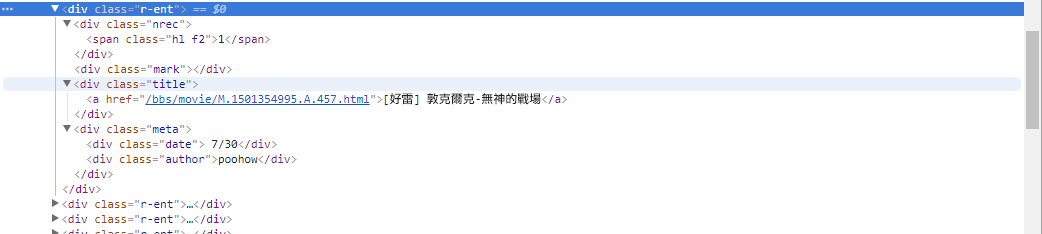
Con las herramientas de desarrollador, puede utilizar el puntero del mouse para seleccionar un elemento específico en la página web y luego ver la estructura HTML del elemento, los atributos CSS y otros detalles en el panel de herramientas de desarrollador. Esto le ayuda a determinar a qué elemento apuntar y el selector CSS correspondiente. Además, podrá descubrir por qué el programa a veces sale mal. ! Al mirar la versión web, descubrí que cuando se eliminaba un artículo de la página, la結構del código fuente del elemento <本文已被刪除> de la página web era diferente de la original. De esta manera podemos fortalecerlo aún más para manejar la situación en la que se eliminan artículos.
Ahora, volvamos al código de muestra para la extracción de información usando requests_html :
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )Procesamiento de textos de salida:
Aquí podemos usar rich para mostrar una salida hermosa. Primero cree un objeto de tabla rich y luego reemplace print en el bucle del código de ejemplo anterior con add_row a la tabla. Finalmente, usamos la función print de rich para enviar correctamente la tabla al terminal.
Resultado de la ejecución
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )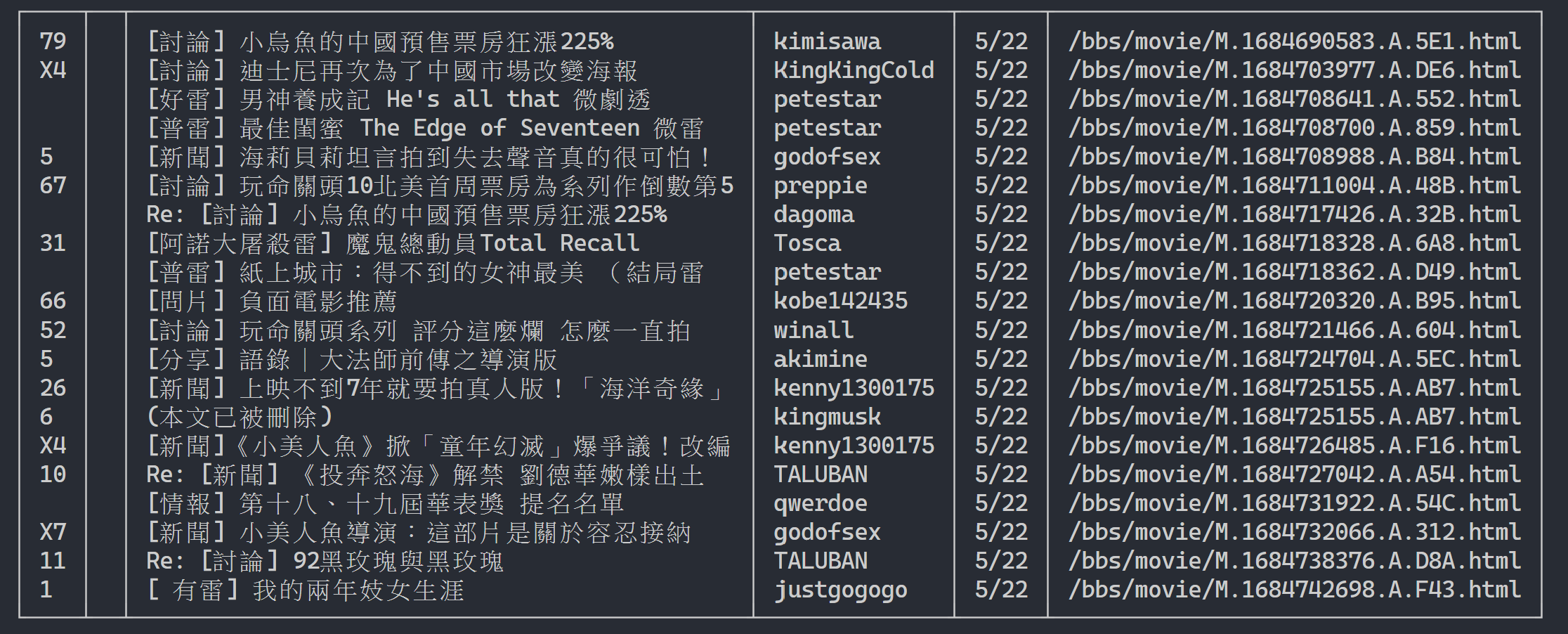
Ahora usaremos el "método de observación" para encontrar el enlace a la página anterior. No, no le estoy preguntando dónde está el botón en su navegador, sino el "árbol de fuentes" en las herramientas de desarrollo. Creo que ha descubierto que el hipervínculo para el salto de página se encuentra en el elemento <a class="btn wide"> de <div class="action-bar"> . Por tanto, podemos extraerlos así:
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )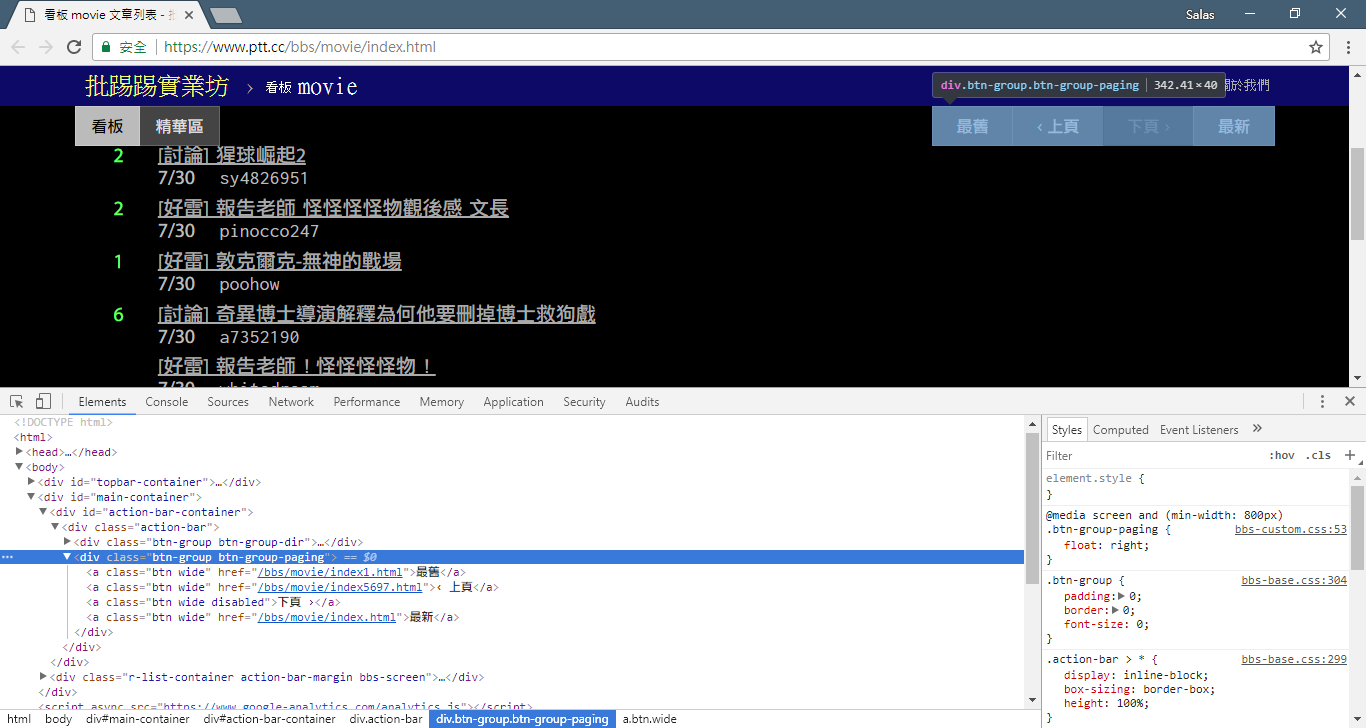
Lo que necesitamos es la función "página anterior". Debido a que PTT muestra los artículos más recientes al principio, debe desplazarse hacia adelante si desea buscar información.
Entonces, ¿cómo usarlo? Primero tome el segundo href en control (el índice es 1), luego puede verse así /bbs/movie/index3237.html y la dirección completa del sitio web (URL) debe ser https://www.ptt.cc/ ( URL del dominio), así que use urljoin() (o conexión de cadena directa) para comparar y fusionar el enlace de la página de inicio de la película con el nuevo enlace en una URL completa.
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url Ahora reorganicemos la función para facilitar la explicación posterior. Cambiemos el ejemplo de procesamiento de cada elemento del artículo en el Paso 3: echemos un vistazo a estos mensajes de título en una función independiente parse_article_entries(elements)
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return resultsA continuación, podemos manejar contenido de varias páginas.
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
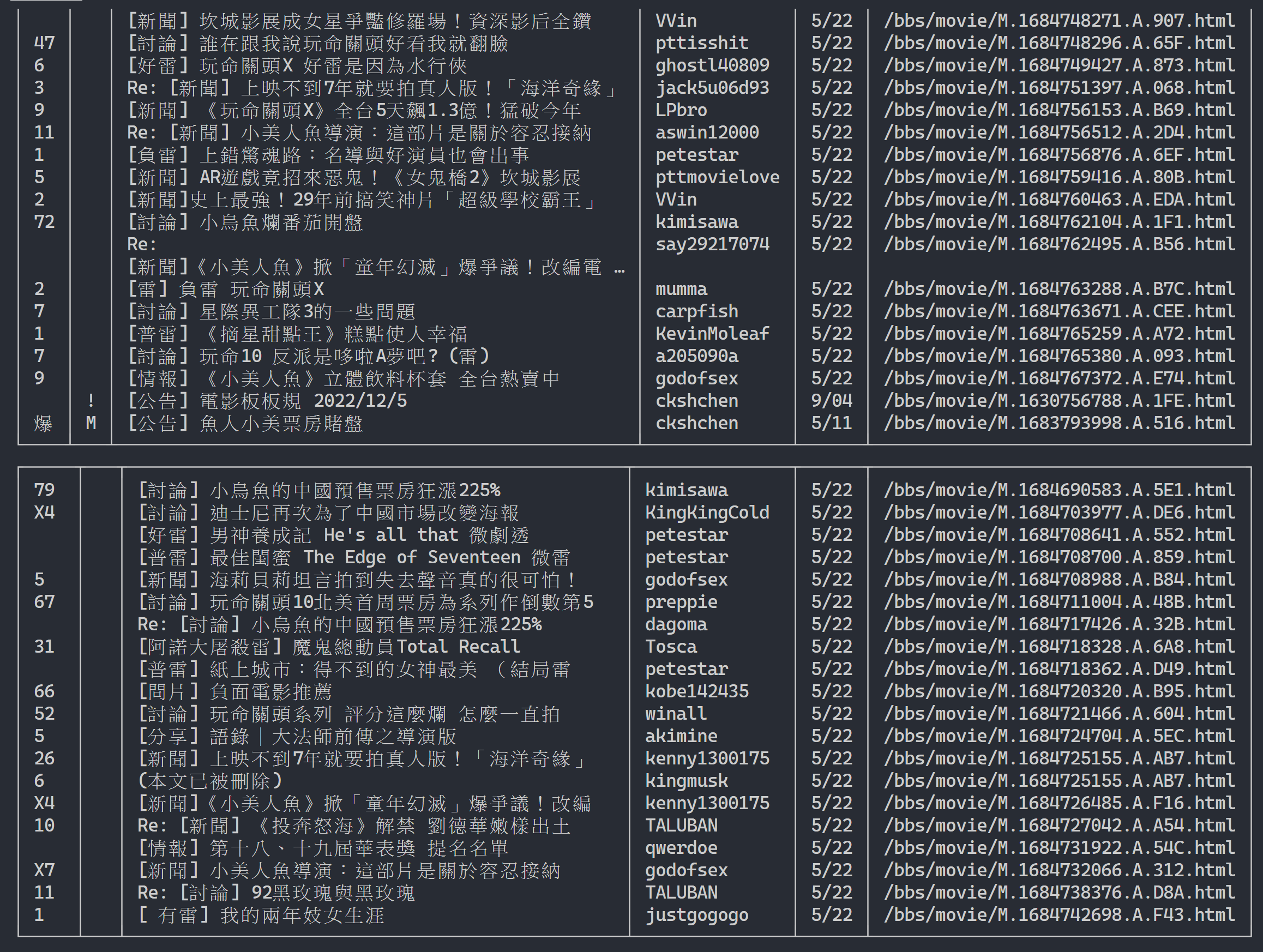
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_urlResultado de salida:
Después de obtener la información de la lista de artículos, el siguiente paso es obtener el contenido del artículo (artículo PO) (contenido de la publicación). link en los metadatos es el enlace de cada artículo. También usamos urllib.parse.urljoin para concatenar la URL completa y luego emitimos HTTP GET para obtener el contenido del artículo. Podemos observar que la tarea de capturar el contenido de cada artículo es altamente repetitiva y es muy adecuada para su procesamiento mediante un método de paralelización.
En Python, puede usar multiprocessing.Pool para realizar programación multiprocesamiento de alto nivel ~ ¡Esta es la forma más fácil de usar multiproceso en Python! Es muy adecuado para este escenario de aplicación SIMD (Instrucción única de datos múltiples). Utilice la sintaxis de la instrucción with para liberar automáticamente los recursos del proceso después de su uso. El uso de ProcessPool también es muy simple, pool.map(function, items) , que es un poco como el concepto de programación funcional. Aplique funciones a cada elemento y finalmente obtenga la misma cantidad de listas de resultados que elementos.
Se utiliza en la tarea de rastrear el contenido del artículo presentado anteriormente:
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )Adjunto los resultados experimentales:
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章Se puede ver que la velocidad de ejecución general se ha acelerado casi cinco veces, pero cuanto más Process mejor. Además de las especificaciones de hardware como la CPU, depende principalmente de las limitaciones de los dispositivos externos como las tarjetas de red y. velocidades de red.
¡El código anterior se puede encontrar en ( src/basic_crawler.py )!
Nueva función en PTT Web: ¡Buscar! Por fin disponible en la versión web.
¡Utilicemos también la versión cinematográfica de PTT como nuestro objetivo del rastreador! El contenido que se puede buscar en la nueva función incluye:
Los tres primeros pueden encontrar reglas de la nueva versión del código fuente de la página y enviar solicitudes, pero la búsqueda del recuento de tweets no parece haber aparecido en la interfaz de usuario de la versión web, por lo que aquí están los parámetros extraídos por el autor PTT 網站原始碼. El PTT que normalmente navegamos en realidad incluye el servidor BBS (es decir, BBS) y el servidor web front-end (versión web). El servidor web front-end está escrito en lenguaje Go (Golang) y puede acceder directamente al back-end. Datos y uso de BBS El modo de interacción general del sitio web convierte el contenido en una página web para navegar.
De hecho, es muy sencillo utilizar estas nuevas funciones. Sólo necesita obtener esta información a través de una solicitud HTTP GET y el método de cadena de consulta estándar. La URL endpoint que proporciona la función de búsqueda es /bbs/{看板名稱}/search . Simplemente use la consulta correspondiente para obtener los resultados de la búsqueda desde aquí. Primero, tome la palabra clave del título como ejemplo,
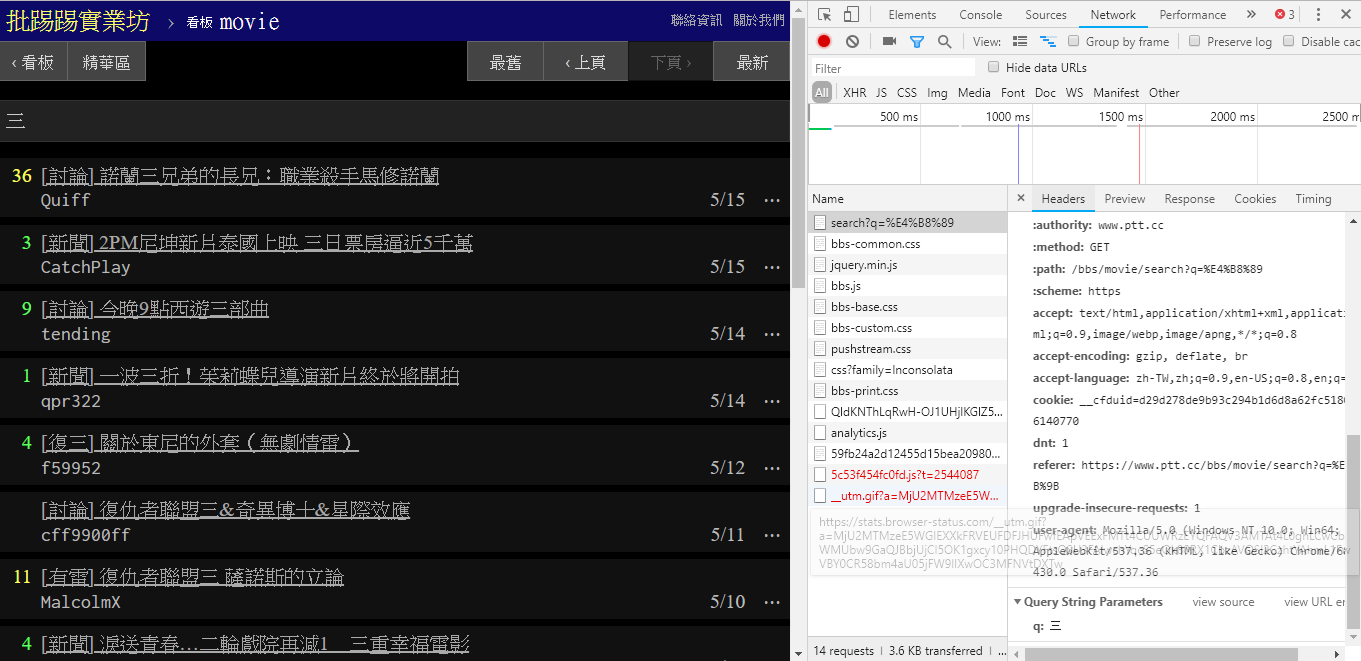
Como se puede ver en la esquina inferior derecha de la imagen, durante la búsqueda, en realidad se envía una solicitud GET con q=三al endpoint , por lo que la URL completa debería ser como https://www.ptt.cc/bbs/movie/search?q=三, la URL copiada de la barra de direcciones puede tener el formato https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 porque el chino ha sido HTML. codificado pero Representa el mismo significado. En requests , si desea agregar parámetros de consulta adicionales, no necesita construir manualmente el formulario de cadena usted mismo. Solo necesita colocarlos en los parámetros de la función a través de dict() de param= , de esta manera:
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })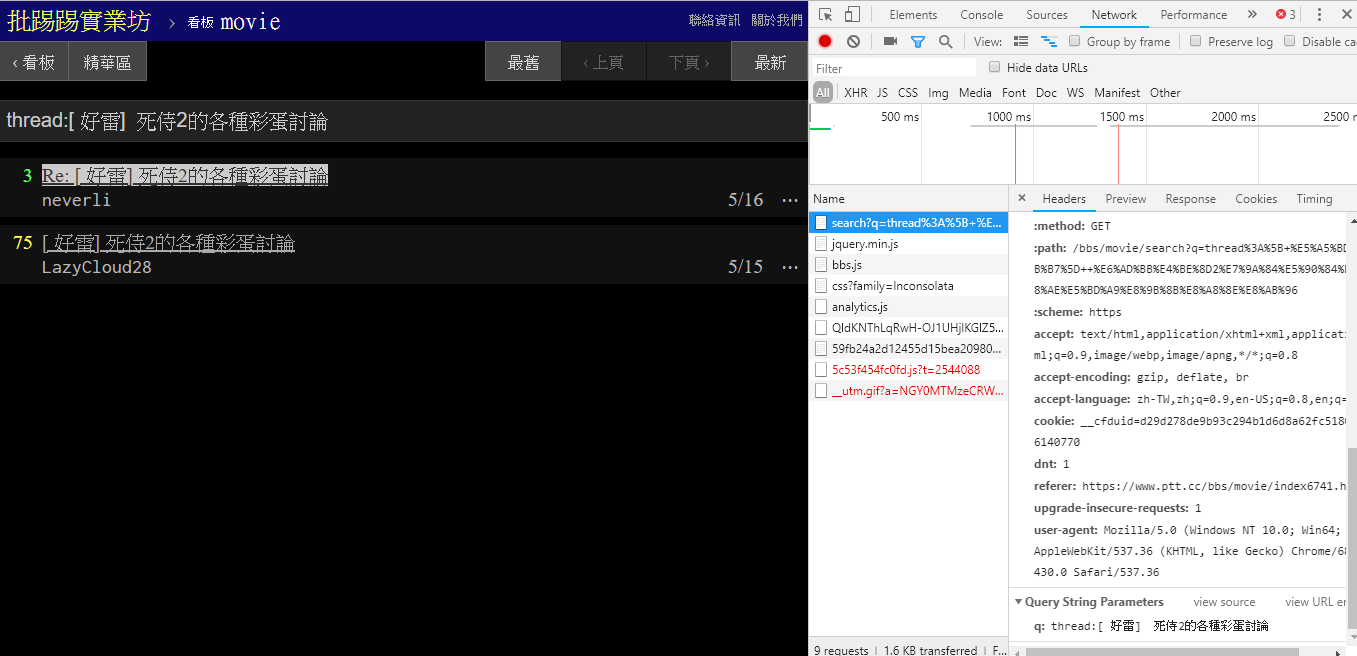
Al buscar el mismo artículo (hilo), puede ver en la información en la esquina inferior derecha que en realidad coloca la cadena thread: delante del título y envía la consulta.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })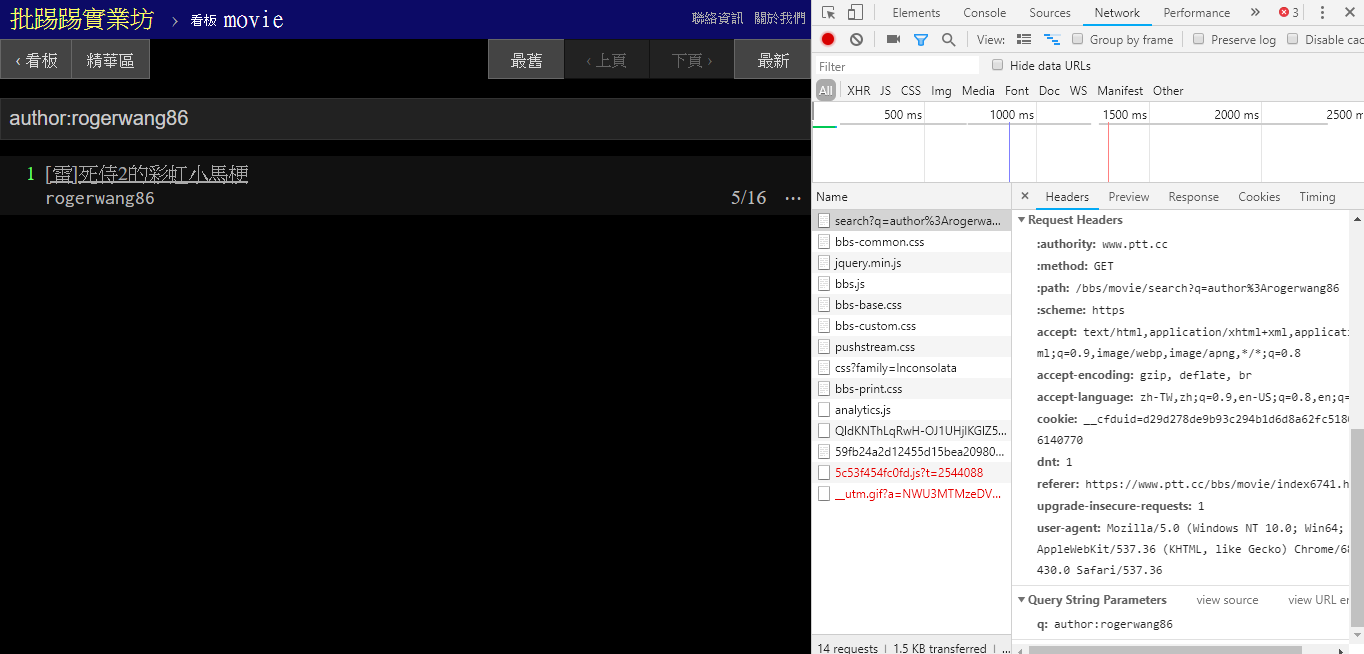
Al buscar artículos con el mismo autor (autor), también se puede ver en la información en la esquina inferior derecha que author: se concatena con el nombre del autor y luego se envía la consulta.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })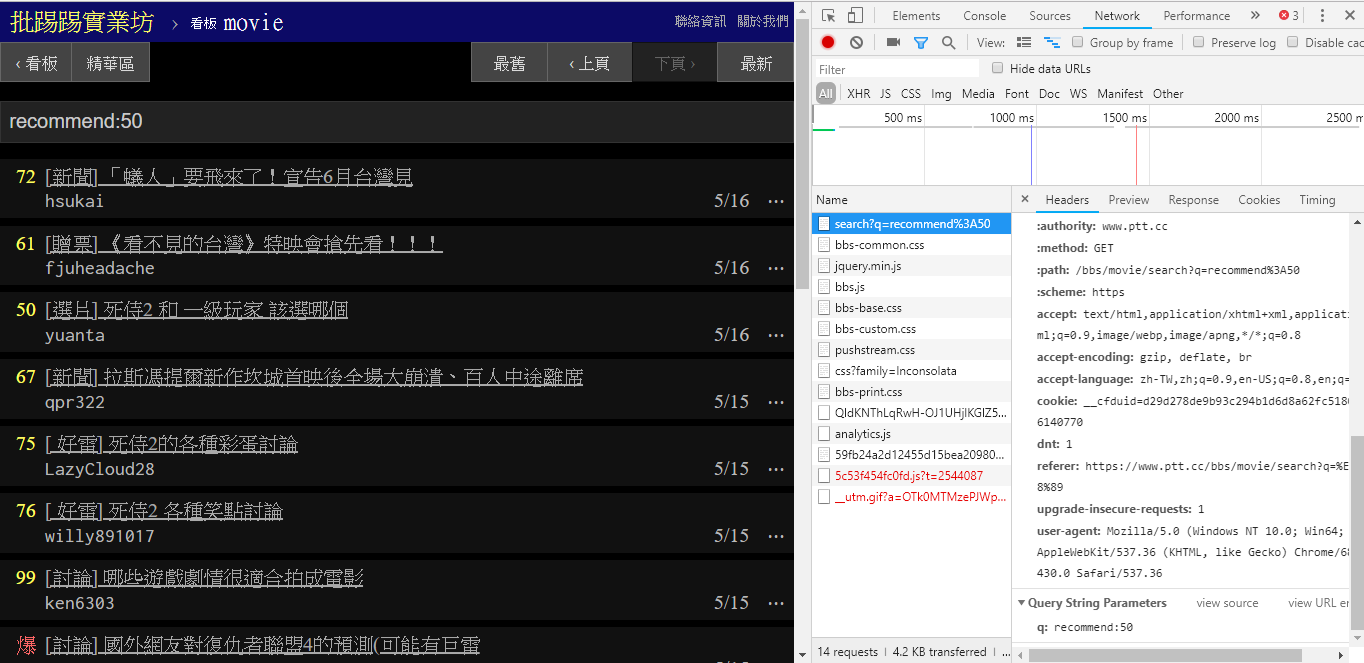
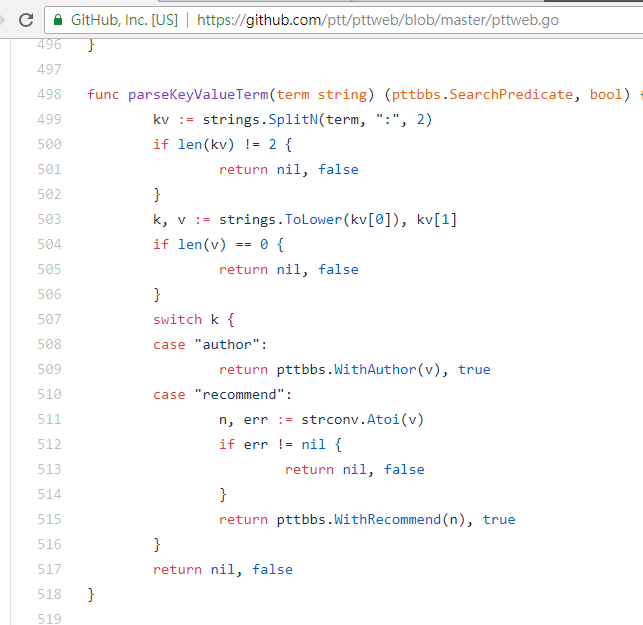
Al buscar artículos con un número de tweets mayor a (recomendar), encadene la cadena recommend: con el número mínimo de tweets que desea buscar y luego envíe la consulta. Además, en el código fuente del servidor web PTT se puede encontrar que el número de tweets solo se puede establecer dentro de ±100.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })Código fuente de la función de análisis web PTT de estos parámetros
También vale la pena mencionar que la presentación final de los resultados de la búsqueda es la misma que el diseño general mencionado en los conceptos básicos, por lo que puede reutilizar directamente las funciones anteriores. Don't do it again!
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] Hay otro parámetro en la búsqueda. El número de page es como la búsqueda de Google. Lo buscado puede tener muchas páginas, por lo que puede usar este parámetro adicional para controlar qué página de resultados desea obtener sin tener que analizar el enlace. la página.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) La integración de todas las funciones anteriores en ptt-parser puede proporcionar funciones de línea de comandos y爬蟲en forma de API que se pueden llamar mediante programación.
scrapy para rastrear datos PTT de forma estable.
Este trabajo fue producido por leVirve y se publica bajo una licencia internacional Creative Commons Attribution 4.0.


