fine grained sentiment app streamlit
1.0.0
Este repositorio contiene el equivalente Streamlit de una aplicación interactiva existente, que explica los resultados de la clasificación detallada de sentimientos, que se describe en detalle en esta serie mediana.
Se implementan varios clasificadores y sus resultados se explican utilizando el explicador LIME. Los clasificadores se entrenaron en el conjunto de datos Stanford Sentiment Treebank (SST-5). Las etiquetas de clase son cualquiera de [1, 2, 3, 4, 5] , donde 1 es muy negativo y 5 es muy positivo.
Streamlit es un marco minimalista y liviano para crear paneles en Python. El objetivo principal de Streamlit es brindar a los desarrolladores la capacidad de crear rápidamente prototipos de sus diseños de interfaz de usuario utilizando la menor cantidad de líneas de código posible. Todo el trabajo pesado que normalmente se requiere para implementar una aplicación web, como definir el servidor backend y sus rutas, manejar solicitudes HTTP, etc., se abstrae del usuario. Como resultado, resulta muy fácil implementar rápidamente una aplicación web, independientemente de la experiencia del desarrollador.
Primero, configure el entorno virtual e instálelo desde requirements.txt :
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
Para un mayor desarrollo, simplemente active el entorno virtual existente.
source venv/bin/activate
Una vez configurado y activado el entorno virtual, ejecute la aplicación con el siguiente comando.
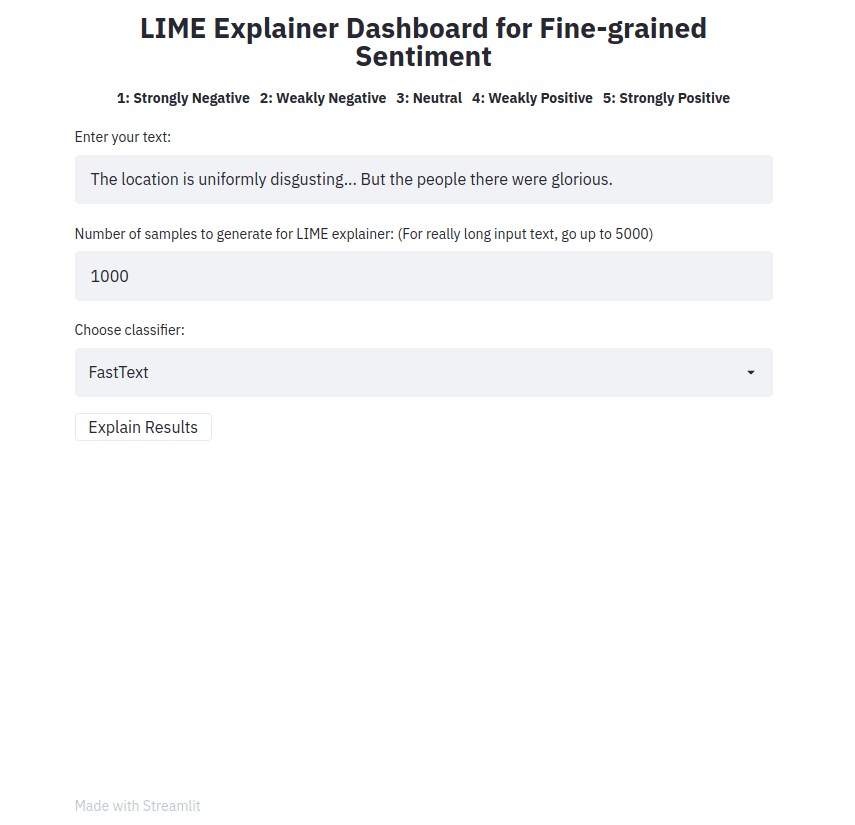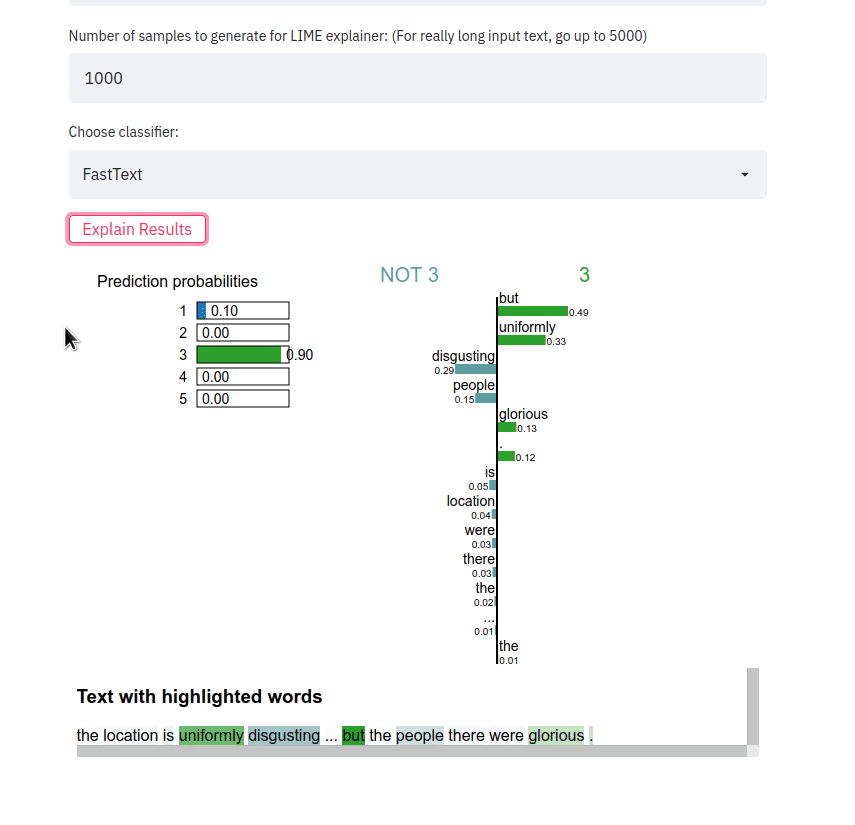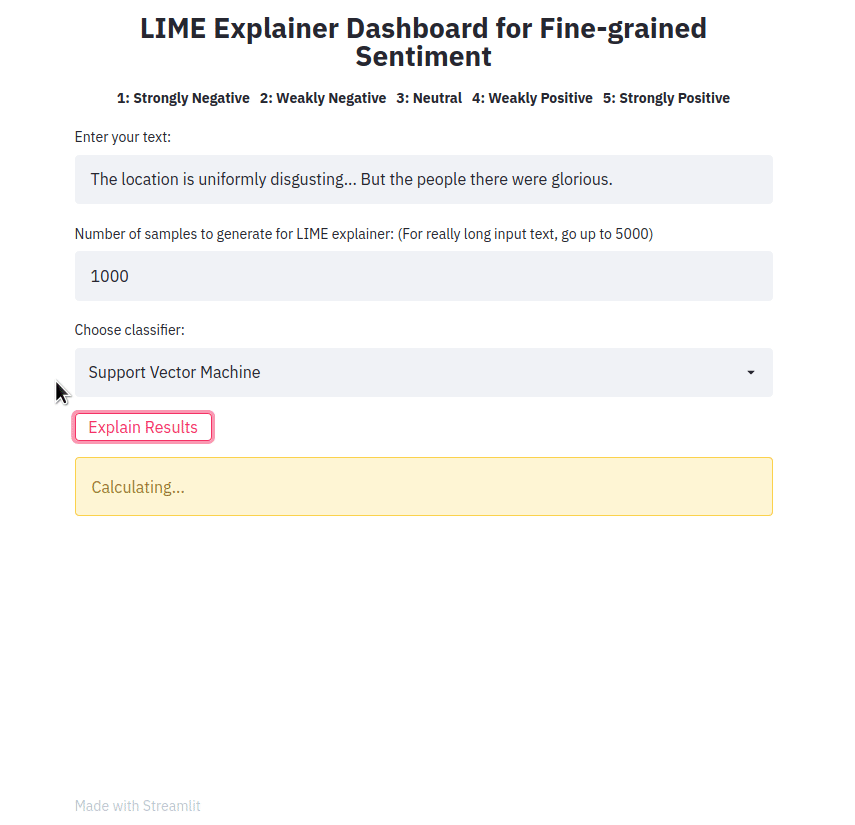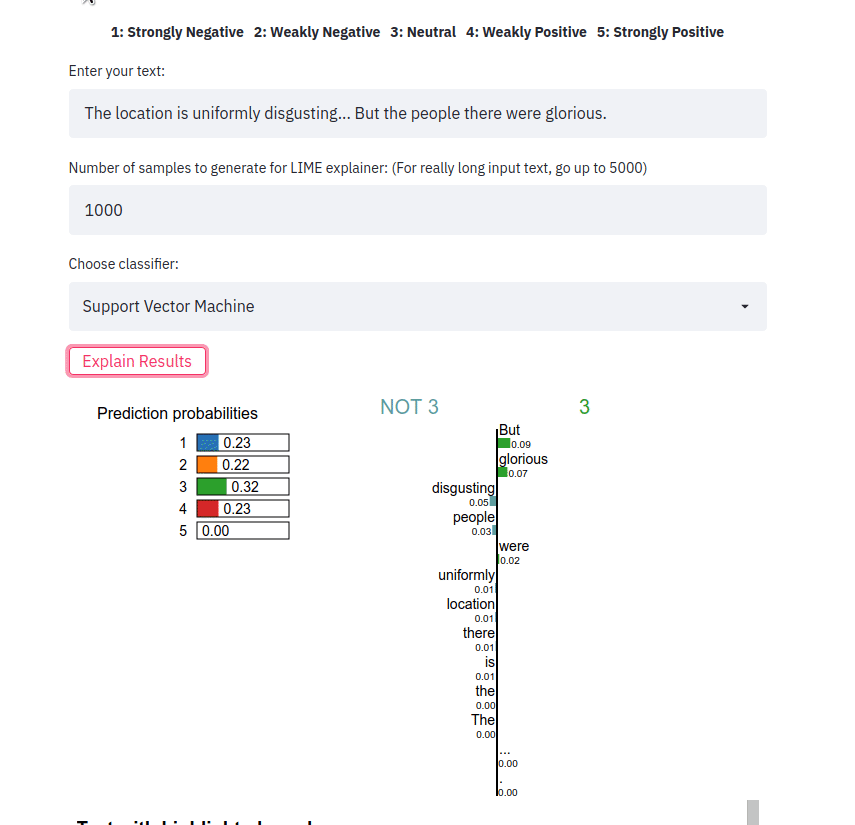
streamlit run app.py Introduce una frase, elige un tipo de clasificador y pulsa en el botón Explain results . Luego podemos observar las características (es decir, palabras o tokens) que contribuyeron a que el clasificador predijera una etiqueta de clase particular.
La aplicación de interfaz de usuario toma una muestra de texto y genera explicaciones LIME para los diferentes métodos. La aplicación se implementa usando Heroku en esta ubicación: https://sst5-explainer-streamlit.herokuapp.com/
Juegue con sus propios ejemplos de texto como se muestra a continuación y vea cómo se explican los resultados detallados de las opiniones.
NOTA: Debido a que los modelos basados en PyTorch (Flair y el transformador causal) son bastante costosos para ejecutar inferencias (requieren una GPU), estos métodos no se implementan. Sin embargo, se pueden ejecutar en una instancia local de la aplicación.