pianola
1.0.0
 pianola en acción" style="max-width: 100%;">
pianola en acción" style="max-width: 100%;">
pianola es una aplicación que reproduce música de piano generada por IA. Los usuarios inician (es decir, "indican") el modelo de IA tocando notas en el teclado o eligiendo fragmentos de ejemplo de piezas clásicas.
En este archivo Léame, explicamos cómo funciona la IA y entramos en detalles sobre la arquitectura del modelo.
La música se puede representar de muchas maneras, desde formas de onda de audio sin formato hasta estándares MIDI semiestructurados. En pianola , dividimos los tiempos musicales en intervalos regulares y uniformes (por ejemplo, semicorcheas/semicorcheas). Se considera que las notas tocadas dentro de un intervalo pertenecen al mismo paso de tiempo y una serie de pasos de tiempo forma una secuencia. Utilizando la secuencia basada en cuadrícula como entrada, el modelo de IA predice las notas en el siguiente paso de tiempo, que a su vez se utiliza como entrada para predecir el siguiente paso de tiempo de manera autorregresiva.
Además de las notas a tocar, el modelo también predice la duración (el tiempo que se mantiene presionada la nota) y la velocidad (con qué fuerza se presiona una tecla) de cada nota.
El modelo se compone de tres módulos: un embebedor, un transformador y un decodificador. Estos módulos toman prestados arquitecturas conocidas como redes Inception, transformadores LLaMA y cadenas clasificadoras de etiquetas múltiples, pero están adaptados para trabajar con datos musicales y combinados en un enfoque novedoso.
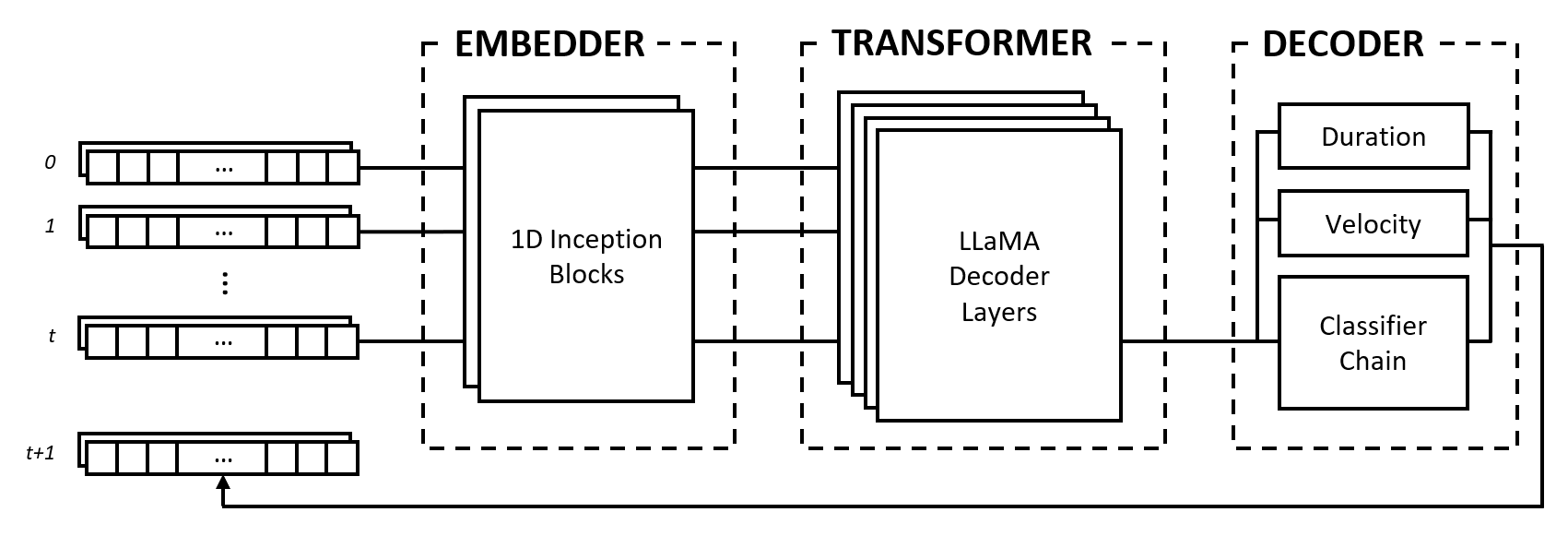
El incrustador convierte cada paso de tiempo de entrada de forma (num_notes, num_features) en un vector de incrustación que se puede introducir en el transformador. Sin embargo, a diferencia de las incrustaciones de texto que asignan vectores one-hot a otro espacio dimensional, proporcionamos un sesgo inductivo al aplicar capas convolucionales y de agrupación en la entrada. Hacemos esto por varias razones:
2^num_notes , donde num_notes es 64 u 88 para pianos cortos a normales), por lo tanto, no es posible representarlas como vectores one-hot.Para permitir que el integrador sepa qué distancias son útiles, nos inspiramos en las redes Inception y apilamos convoluciones de diferentes tamaños de kernel.
El módulo transformador está compuesto por capas transformadoras LLaMA que aplican autoatención a la secuencia de vectores de incrustación de entrada.
Como muchos modelos de IA generativa, este módulo utiliza sólo la parte "decodificadora" del modelo original de Transformers de Vaswani et al. (2017). Usamos aquí la etiqueta "transformador" para diferenciar este módulo del siguiente, que realiza la decodificación real de los estados producidos por las capas de autoatención.
Elegimos la arquitectura LLaMA sobre otros tipos de transformadores principalmente porque utiliza incrustaciones posicionales rotativas (RoPE), que codifica posiciones relativas con caída de distancia en pasos de tiempo. Dado que representamos datos musicales como intervalos fijos, las posiciones relativas y las distancias entre pasos de tiempo son piezas de información importantes que el transformador puede usar explícitamente para comprender y generar música con un ritmo consistente.
El decodificador toma en cuenta los estados atendidos y predice las notas que se tocarán junto con sus duraciones y velocidades. El módulo se compone de varios subcomponentes, a saber, una cadena clasificadora para la predicción de notas y perceptrones multicapa (MLP) para predicciones de características.
La cadena de clasificadores consta de clasificadores binarios num_notes , es decir, uno para cada tecla de un piano, para crear un clasificador de etiquetas múltiples. Para aprovechar las correlaciones entre notas, los clasificadores binarios se encadenan de modo que el resultado de las notas anteriores afecte las predicciones de las notas siguientes. Por ejemplo, si existe una correlación positiva entre notas de octava, una nota inferior activa (por ejemplo, C3 ) da como resultado una mayor probabilidad de que se prediga la nota más alta (por ejemplo, C4 ). Esto también es beneficioso en casos de correlaciones negativas, donde se puede elegir entre dos notas adyacentes que dan como resultado una escala mayor o menor (por ejemplo, CDE versus CD-Eb ), pero no ambas.
Para lograr eficiencia computacional, limitamos la longitud de la cadena a 12 eslabones, es decir, una octava. Finalmente, se utiliza una estrategia de decodificación de muestreo para seleccionar notas en relación con sus probabilidades de predicción.
Las características de duración y velocidad se tratan como problemas de regresión y se predicen utilizando MLP básicos. Si bien las características se predicen para cada nota, utilizamos una función de pérdida personalizada durante el entrenamiento que solo agrega pérdidas de características de las notas activas, similar a la función de pérdida utilizada en una clasificación de imágenes con tarea de localización.
Nuestra elección de representar datos musicales como una cuadrícula tiene sus ventajas y desventajas. Discutimos estos puntos comparándolos con el vocabulario basado en eventos propuesto por Oore et al. (2018), un aporte muy citado en la generación musical.
Una de las principales ventajas de nuestro enfoque es el desacoplamiento de la comprensión micro y macro de la música, lo que conduce a una clara separación de funciones entre el integrador y el transformador. La función del primero es interpretar la interacción de las notas a un nivel micro, como por ejemplo cómo las distancias relativas entre notas forman relaciones musicales como los acordes, y la tarea del segundo es sintetizar esta información en la dimensión del tiempo para comprender el estilo musical a un nivel macro. nivel.
Por el contrario, una representación basada en eventos coloca toda la carga en un modelo de secuencia para interpretar tokens únicos que podrían representar tono, sincronización o velocidad, tres conceptos distintos. Huang et al. (2018) encuentran que es necesario agregar un mecanismo de atención relativa a su modelo Transformer para generar continuaciones coherentes, lo que sugiere que el modelo requiere un sesgo inductivo para funcionar bien con esta representación.
En una representación de cuadrícula, la elección de la duración del intervalo es una compensación entre la fidelidad y la escasez de los datos. Un intervalo más largo reduce la granularidad de los tiempos de las notas, reduciendo la expresividad musical y potencialmente comprimiendo elementos rápidos como trinos y notas repetidas. Por otro lado, un intervalo más corto aumenta exponencialmente la escasez al introducir muchos pasos de tiempo vacíos, lo cual es un problema importante para los modelos Transformer, ya que están limitados en la longitud de la secuencia.
Además, los datos musicales se pueden asignar a una cuadrícula ya sea a través del paso del tiempo ( 1 timestep == X milliseconds ) o como están escritos en una partitura ( 1 timestep == 1 sixteenth note/semiquaver ), cada uno con sus propias compensaciones. . Una representación basada en eventos evita estos problemas por completo al especificar el paso del tiempo como un evento.
A pesar de sus inconvenientes, la representación en cuadrícula tiene una ventaja práctica: es mucho más fácil trabajar con ella en el desarrollo de pianola . El resultado del modelo es legible por humanos y el número de pasos de tiempo corresponde a una cantidad de tiempo fija, lo que hace que el desarrollo de nuevas funciones sea mucho más rápido.
Además, la investigación para ampliar la longitud de las secuencias de los modelos Transformer y las mejoras continuas del hardware reducirán progresivamente los problemas causados por la escasez de datos y, a finales de 2023, veremos grandes modelos de lenguaje que pueden manejar decenas de miles de tokens. A medida que las técnicas se optimicen y el hardware potente se vuelva más accesible, creemos que la fidelidad seguirá mejorando, tal como lo ha hecho con la generación de imágenes, lo que conducirá a una mayor expresividad y matices en la música generada por IA.
El código fuente de este proyecto es públicamente visible para fines de investigación académica e intercambio de conocimientos. Todos los derechos son retenidos por los creadores a menos que se hayan otorgado permisos explícitamente.
Icono del sitio modificado de Freepik - Flaticon.
Póngase en contacto en outlook.com en la dirección bruce <dot> ckc .


