project omega
El último patrón de arquitectura web empresarial que necesitará. Hasta la próxima.
TL;DR
El objetivo es optimizar la experiencia del desarrollador al poder:
- Desarrollar localmente como si fuera un monolito
- Implementar como microservicios separados
- Simule el entorno de producción localmente usando Docker
Manifestación
project omega Prueba de concepto: microservicios monolito híbrido
Demostración project omega : microservicios de Kubernetes e implementación de contenedores independientes
Por qué
Quiero demostrar que no tenemos que sacrificar la eficiencia del desarrollador para obtener escalabilidad. Más debates sobre los pros y los contras de los microservicios y los monolitos aquí: Microservicios y monolitos.
Mi impresión es que muchos expertos del sector nos harían creer que estas son nuestras 3 opciones principales:
- Monolito
- Microservicios
- "Híbrido" (no es realmente un híbrido, es un monolito y también algunos microservicios)
Quiero mostrar que no tenemos que elegir ninguna de estas opciones. Con un poco de creatividad podemos tener un verdadero "híbrido" que sea a la vez un monolito y un conjunto de microservicios. Con mi estrategia actual no creo que podamos eliminar todas las desventajas del monolito y los microservicios, pero sí podemos deshacernos de muchos de los puntos débiles de ambos.
Lo que no es
- No estoy intentando crear un marco (al menos no todavía...). Simplemente estoy juntando todos los legos que tengo en una configuración diferente a modo de experimento.
- Este no pretende ser un proyecto comunitario. Tengo la intención de realizar frecuentes cambios importantes sin previo aviso. Si este concepto te parece interesante y te gustaría contribuir, contáctame primero.
Objetivos del proyecto
- Cree un patrón que funcione para proyectos como pequeños proyectos de hobby de un solo desarrollador y también escale a docenas o incluso cientos de desarrolladores que trabajan en aplicaciones web empresariales grandes y complejas.
- Ser capaz de desarrollarse localmente como si fuera un monolito:
- Un repositorio. Por las mismas razones, las empresas eligen un enfoque monorepo.
- Máximo 3 procesos para ejecutar (interfaz de usuario del cliente, servidor, dependencias de la ventana acoplable con la base de datos, cola de mensajes, etc.). No queremos que se pongan en funcionamiento páginas de documentos de configuración.
- Ser capaz de implementar como microservicios.
- Ser capaz de simular un entorno de producción con microservicios ejecutándose en contenedores Docker.
- Tiempo de configuración extremadamente rápido. Todas las dependencias distintas de Node y .NET deben incluirse como dependencias de Docker (base de datos, cola de mensajes, etc.). Los nuevos usuarios deberían poder instalar .NET, Node, clonar el repositorio y luego ejecutar los comandos de instalación y ejecución.
- Recarga en caliente extremadamente rápida tanto para el cliente como para el servidor en el entorno de desarrollo.
- Ser capaz de desarrollar y ejecutar la aplicación en Windows, Linux y Mac.
- Ser capaz de poner en marcha rápidamente un nuevo servicio.
Pila de tecnología
La pila tecnológica es prácticamente irrelevante para el concepto de alto nivel que intento demostrar, pero para este proyecto voy a usar:
- .NET 5 para servicios
- React front-end (aplicación create-react-app básica con mecanografiado)
- Estibador
Conceptos de alto nivel
Las empresas con grandes aplicaciones se ven cada vez más impulsadas hacia los microservicios para que puedan escalar horizontalmente (entre otras razones). Entonces, para lograr eso, estamos viendo algo como lo siguiente:
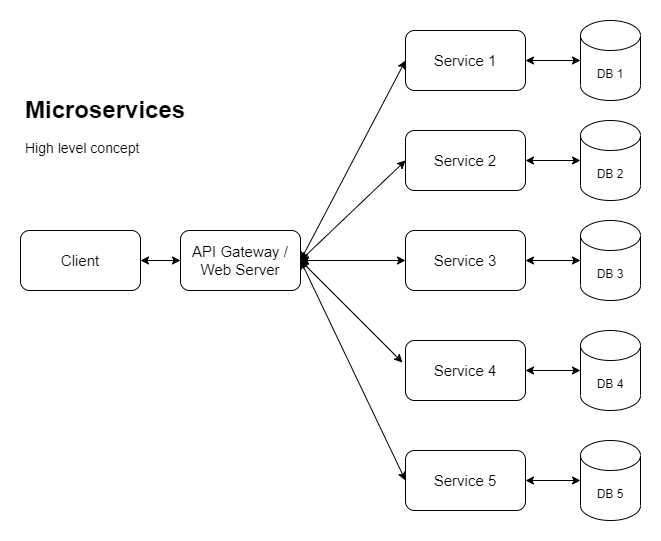
Aquí hay otra versión que muestra una forma en que se podría implementar la escala horizontal:
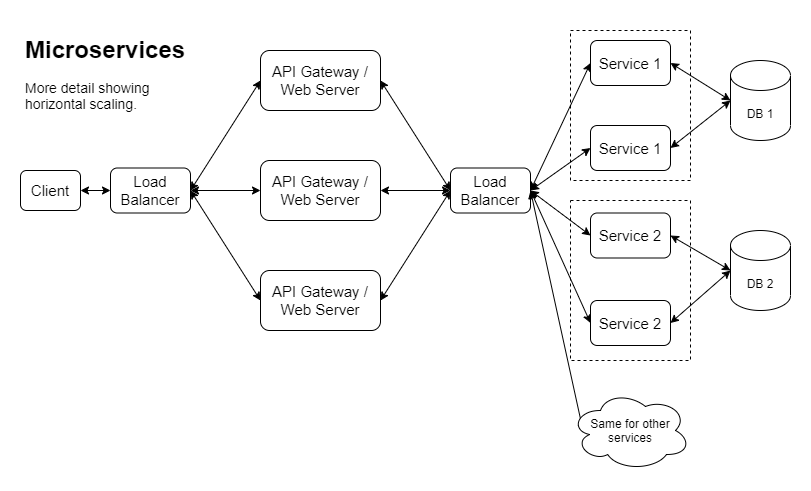
Una vez que tomamos este camino, terminamos con un problema real de desarrollo local. Realmente depende de cómo es el producto, cuántos desarrolladores hay, quién trabaja en qué y con qué frecuencia. Dicho esto, una gran parte de las empresas que eligen microservicios terminarán en una situación en la que los desarrolladores tendrán que tomar decisiones difíciles sobre cómo realizar su desarrollo diario. Con project omega , el objetivo es mostrar que podemos eliminar la sobrecarga de ejecutar un servicio localmente combinándolos todos en una sola aplicación mientras se ejecuta localmente:
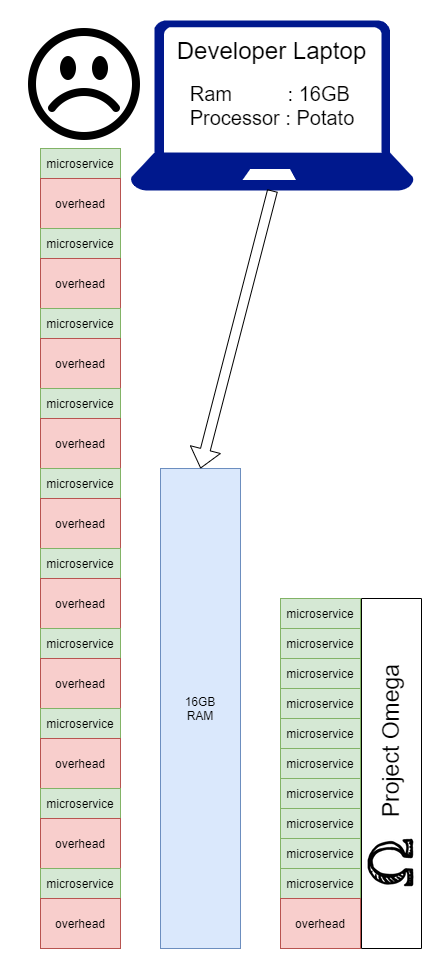
Aquí está la estructura de carpetas:
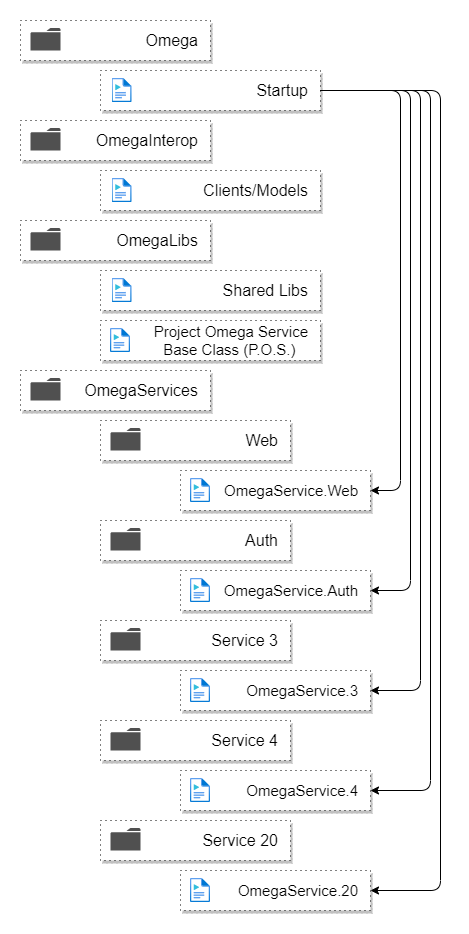
Y así es como se vería implementado como microservicios:
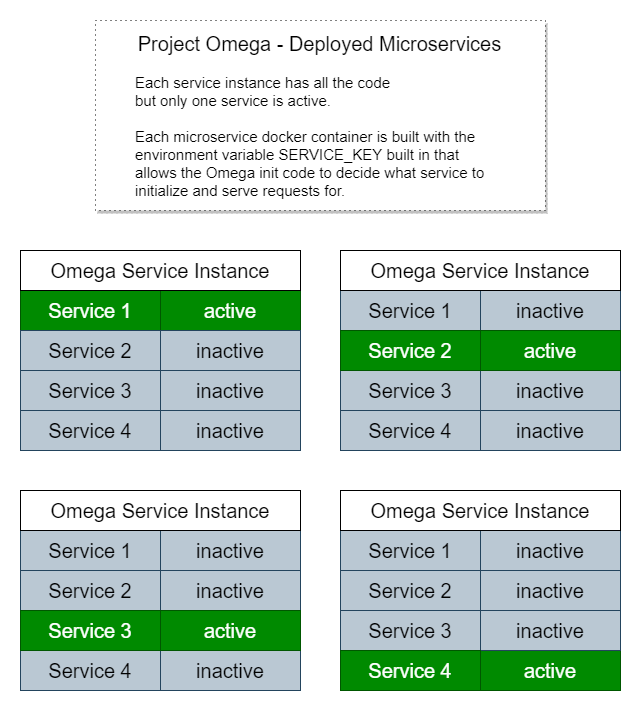
Cada instancia tiene una copia de todo el código, pero solo ejecuta la inicialización, las rutas de los puntos finales del servicio y los procesos de trabajo para un microservicio específico.
Por eso es tan sencillo ejecutar la aplicación localmente como un monolito porque simplemente buscamos una variable de entorno llamada SERVICE_KEY o si no está presente, inicializamos todos los servicios.
Ejemplos de inicialización específica de otros servicios:
- Configuración de inyección de dependencia
- Cadenas de conexión de base de datos
- Migraciones de bases de datos
- Inicialización de la cola de mensajes
- Configurar la conectividad de caché distribuida
- Otra configuración de conectividad de recursos en la nube
- Inicialización de API de terceros
Cuando se llama a Startup, escanea los ensamblados en busca de tipos que hereden ProjectOmegaService , crea una instancia y ejecuta la lógica de inicialización de ese servicio. Cuando se ejecuta localmente, los ejecutará todos.
Instrucciones de configuración
Instalar requisitos previos:
- .NET 5
- Nodo
- Hilo
- Estibador
Tenga en cuenta que ejecutar la última versión de Docker en Windows puede requerir algunos pasos adicionales si no lo ha hecho por un tiempo, como instalar WSL 2 y actualizar su distribución WSL. Siga las instrucciones en el sitio web de Docker.
Pasos:
- Clonar este repositorio
- En una terminal desde la raíz del repositorio, ejecute
yarn run installAll - Si desea ejecutar el servidor SQL en un puerto distinto del 1434:
- Ejecutar
yarn run syncEnvFiles - Cambie
OMEGA_DEFAULT_DB_PORT y OMEGA_MSSQL_HOST_PORT en .env.server
- Inicie las dependencias usando el comando
yarn run dockerDepsUpDetached - Ejecute migraciones de base de datos la primera vez que lo ejecute, o cuando obtenga cambios de otra persona con las actualizaciones de la base de datos:
yarn run dbMigrate - Ejecute la aplicación en modo de desarrollo local usando una de estas opciones:
- Opción 1: en una terminal desde la raíz del repositorio, ejecute
yarn run both (esto se usa simultáneamente para ejecutar los comandos de las opciones 2) - Opción 2: utilizar 2 terminales separados. En una terminal ejecute
yarn run client y en la otra ejecute yarn run server
- Acceda a https://localhost:3000 (haga clic en más allá de la advertencia https)
Antes de ejecutar pruebas unitarias con dotnet test por primera vez o después de agregar pruebas unitarias en un nuevo esquema de base de datos:
- Inicie las dependencias si aún no se están ejecutando con
yarn run dockerDepsUpDetached - Ejecutar
yarn run testDbMigrate - Luego ejecute
dotnet test
Para simular producción y microservicios en Docker:
- Asegúrese de que las dependencias de Docker se estén ejecutando con
yarn run dockerDepsUpDetached - En una terminal desde la raíz del repositorio, ejecute
yarn run dockerRecreateFull - Acceda a https://localhost:3000 (haga clic en más allá de la advertencia https)
Próximos pasos
- Cambios de registro
- Experimente con el formateador Serilog json
- Agregue ID de correlación y otra información contextual para registrar entradas
- Añadir documentación adicional
- Diagramas de cómo funciona la simulación de Docker.
- dependencias de Docker
- Descripción textual de qué es, cómo funciona.
- Diagramas de cómo encaja Docker Deps en el proceso de desarrollo.
- Documentación de enrutamiento/proxy
- Migraciones de bases de datos
- Prueba RPC entre servicios en lugar de llamadas http rest (tal vez con algo como esto: https://github.com/aspnet/AspLabs/tree/main/src/GrpcHttpApi)
- Agregar a la clase base de cliente entre servicios para abstraer el manejo y el registro de errores
- Implementación de autenticación
- Registro del sitio front-end
- Autenticación de servicio a servicio (¿OAuth?)
- Generación automática de documentación (salida de documentación swagger y html xml)
- Servicios de configuración de colas y procesos de trabajo.
- Definición de cola abstracta (para permitir el uso de servicios en la nube como opción)
- Servicio básico de tipo proceso de trabajo con un bucle de eventos que busca mensajes
- RabbitMQ en docker-compose.deps.yml
- Implementación básica de RabbitMQ conectada al servicio de proceso de trabajo
- Trabajo de demostración adicional de Kubernetes local
- La base de datos probablemente requerirá aprender a usar un volumen persistente de Kubernetes, a menos que pueda descubrir cómo ajustar la red para exponer la base de datos del host.
- Agregue Seq o haga que la funcionalidad Seq sea opcional y no la use cuando se ejecute en Kubernetes
- Metaproyecto/script para analizar la solución
- Analizar los servicios afectados en función de los archivos modificados (para granularidad de la implementación)
- Andamio del proyecto:
- Posibilidad de crear una nueva copia del proyecto utilizando alguna otra "clave" de proyecto además de Omega para todos los nombres de proyecto/directorio
- Capacidad para hacer que un nuevo proyecto ponga en marcha contenedores acoplables y realice pruebas de integración efectivas para garantizar la creación exitosa de nuevos proyectos.
Varios
Si está desarrollando en Linux, puede encontrarse con este error al iniciar el servidor:
System.AggregateException: se produjeron uno o más errores. (Se alcanzó el límite de usuario configurado (128) en la cantidad de instancias de inotify, o se alcanzó el límite por proceso en la cantidad de descriptores de archivos abiertos).
Es probable que esto se deba a que vscode utiliza demasiadas visualizaciones de archivos. Puede aumentar su límite de instancias inotify (no solo el límite de vigilancia, que probablemente ya esté establecido en un nivel muy alto en su archivo /etc/sysctl.conf ) ejecutando este comando:
echo fs.inotify.max_user_instances=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p
Otra documentación
Análisis de costo-beneficio del patrón de diseño: DesignPatternCostBenefit.md
Variaciones de patrones de diseño: DesignPatternVariations.md
Decisiones: Decisiones.md
Filosofías y diatribas del desarrollo de software: https://gist.github.com/mikey-t/3d5d6f0f5316abf9e74fb553be9fdef3


