nnl
gpt2-xl assets
nnl es un motor de inferencia para modelos grandes en una plataforma GPU con poca memoria.
Los modelos grandes son demasiado grandes para caber en la memoria de la GPU. nnl aborda este problema con una compensación entre el ancho de banda PCIE y la memoria.
Un proceso de inferencia típico es el siguiente:
Con el grupo de memoria de la GPU y la desfragmentación de la memoria, NNIL hace posible inferir un modelo grande en una plataforma de GPU de gama baja.
Este es solo un proyecto de hobby escrito en unas pocas semanas; actualmente solo se admite el backend CUDA.
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aEste comando construirá las dos bibliotecas estáticas: lib/lib nnl _cuda.a y lib/lib nnl _cuda_kernels.a . La primera es la biblioteca central con backend CUDA en C++, y la segunda es para los núcleos CUDA.
Aquí se proporciona un programa de demostración de GPT2-XL (1.6B). Este programa se puede compilar con este comando:
make gpt2_1558mDespués de descargar todos los pesos de la versión, podemos ejecutar el siguiente comando en una plataforma GPU de gama baja como GTX 1050 (2 GB de memoria):
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " Y la salida es así: 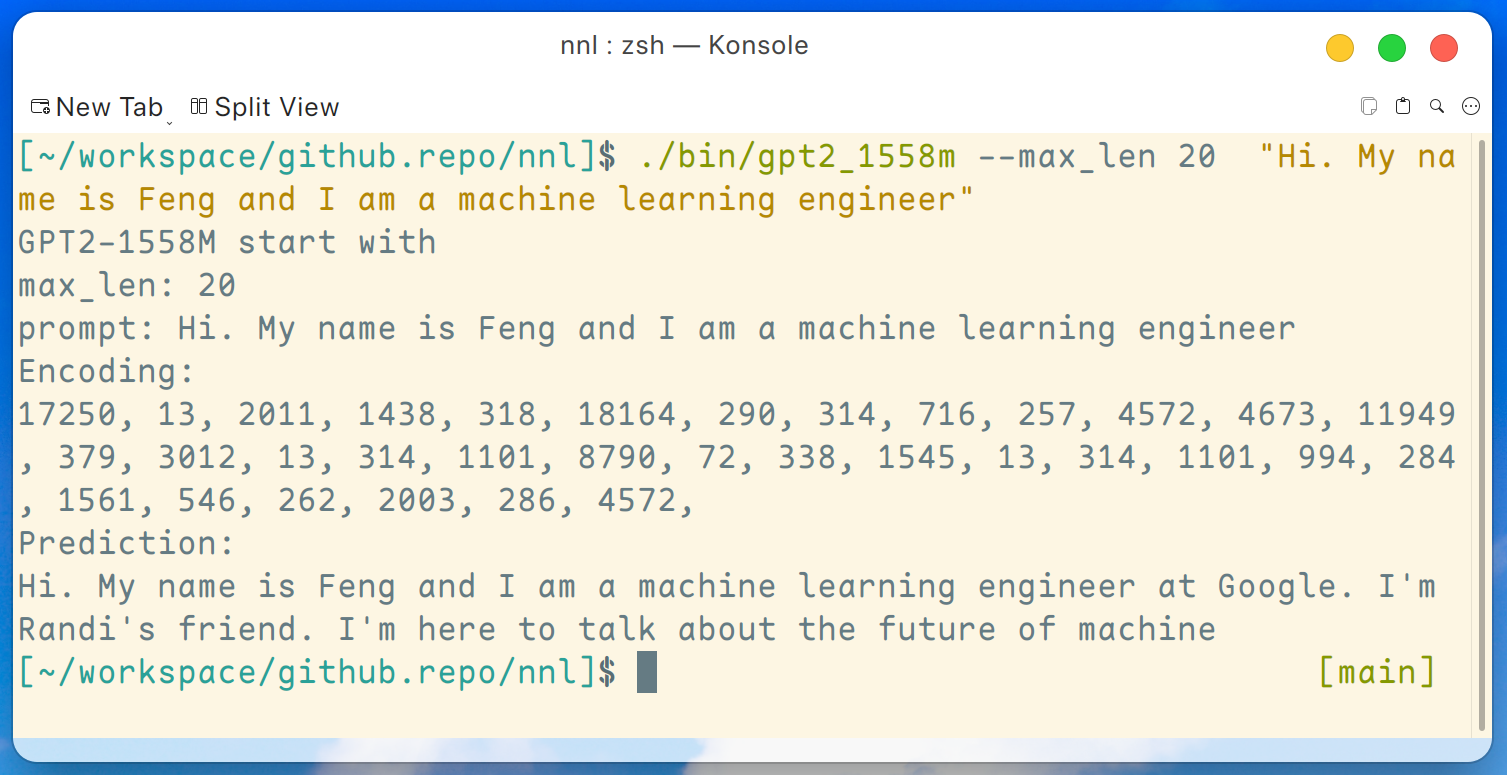
Descargo de responsabilidad: este es solo un ejemplo generado por gpt2-xl, no trabajo en Google y no conozco a Randi.
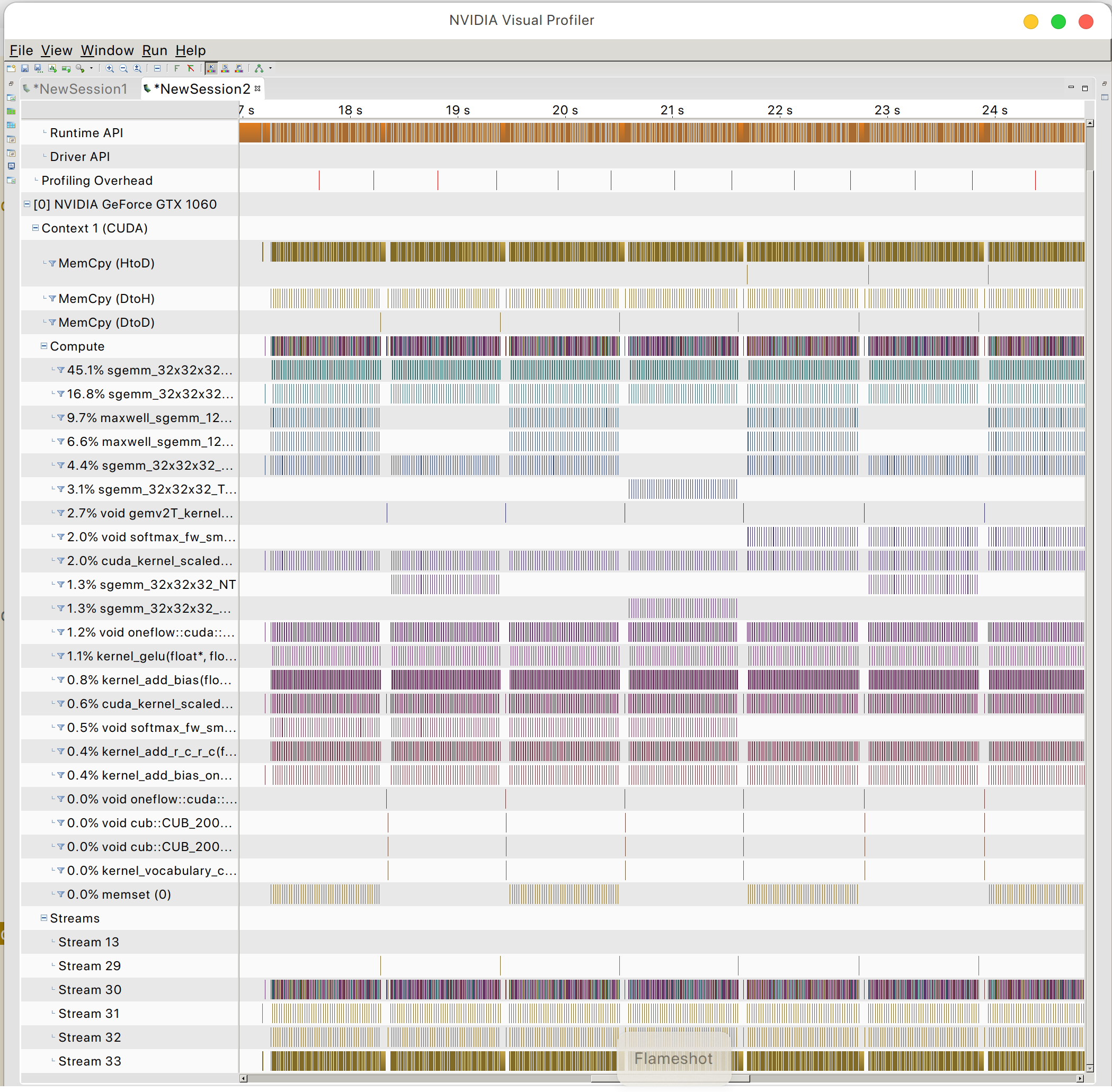
Y puedes encontrar el patrón de acceso a la memoria de la GPU.
PazOSL