UniIR
1.0.0
Página de inicio | ? Conjunto de datos (punto de referencia M-BEIR) | ? Puntos de control (modelos UniIR ) | arXiv | GitHub
Este repositorio contiene el código base para el documento ECCV-2024 " UniIR : capacitación y evaluación comparativa de recuperadores de información multimodales universales".
Proponemos el marco UniIR (Recuperación de información multimodal universal) para aprender a un único recuperador a realizar (posiblemente) cualquier tarea de recuperación. A diferencia de los sistemas de IR tradicionales, UniIR necesita seguir las instrucciones para realizar una consulta heterogénea y recuperarla de un grupo de candidatos heterogéneo con millones de candidatos en diversas modalidades.
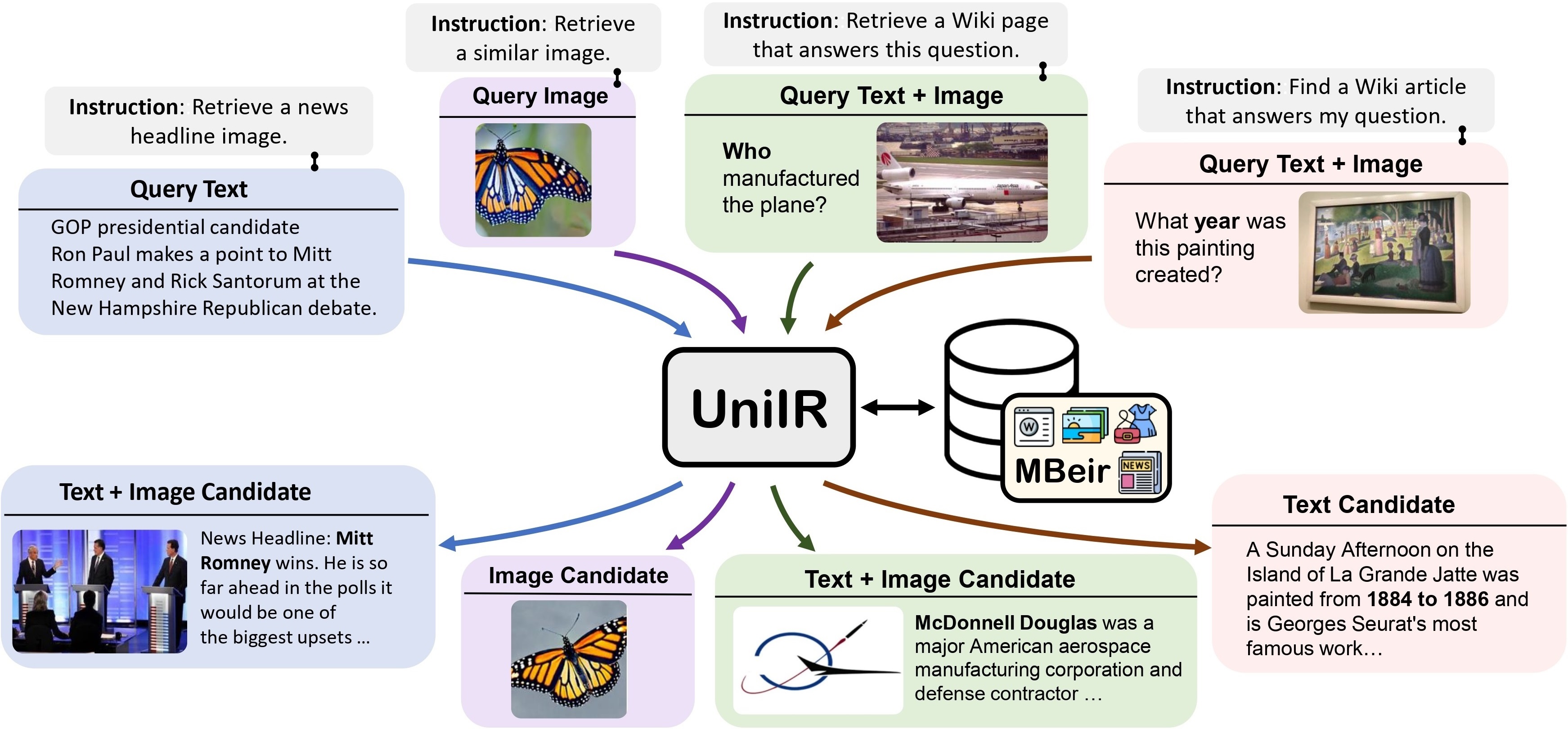 UniIR Teaser" estilo="ancho: 80%; ancho máximo: 100%;">
UniIR Teaser" estilo="ancho: 80%; ancho máximo: 100%;">
Para entrenar y evaluar modelos universales de recuperación multimodal, creamos un punto de referencia de recuperación a gran escala llamado M-BEIR (Multimodal BEnchmark for Instructed Retrieval).
Proporcionamos el conjunto de datos M-BEIR en el formato ? Conjunto de datos . Siga las instrucciones proporcionadas en la página de HF para descargar el conjunto de datos y prepararlos para la capacitación y la evaluación. Debes configurar GiT LFS y clonar directamente el repositorio:
git clone https://huggingface.co/datasets/TIGER-Lab/M-BEIR
Proporcionamos la base de código para entrenar y evaluar los modelos UniIR CLIP-ScoreFusion, CLIP-FeatureFusion, BLIP-ScoreFusion y BLIP-FeatureFusion.
Prepare la base de código del proyecto UniIR y el entorno Conda utilizando los siguientes comandos:
git clone https://github.com/TIGER-AI-Lab/UniIR
cd UniIR
cd src/models/
conda env create -f UniIR _env.ymlPara entrenar los modelos UniIR desde puntos de control CLIP y BLIP previamente entrenados, siga las instrucciones a continuación. Los scripts descargarán automáticamente los puntos de control CLIP y BLIP previamente entrenados.
Descargue el punto de referencia M-BEIR siguiendo las instrucciones en la sección M-BEIR .
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/train/inbatch/ Modifique inbatch.yaml para ajustar los hiperparámetros y run_inbatch.sh para su propio entorno y rutas.
UniIR _DIR en run_inbatch.sh al directorio donde desea almacenar los puntos de control.MBEIR_DATA_DIR en run_inbatch.sh al directorio donde almacena el punto de referencia M-BEIR.SRC_DIR en run_inbatch.sh al directorio donde almacena el código base del proyecto UniIR (este repositorio)..env con WANDB_API_KEY , WANDB_PROJECT y WANDB_ENTITY .Luego puede ejecutar el siguiente comando para entrenar el modelo UniIR CLIP_SF Large.
bash run_inbatch.sh cd src/models/ UniIR _blip/blip_featurefusion/configs_scripts/large/train/inbatch/ Modifique inbatch.yaml para ajustar los hiperparámetros y run_inbatch.sh para su propio entorno y rutas.
bash run_inbatch.shProporcionamos el proceso de evaluación para los modelos UniIR en el punto de referencia M-BEIR.
Cree un entorno para la biblioteca FAISS:
# From the root directory of the project
cd src/common/
conda env create -f faiss_env.ymlDescargue el punto de referencia M-BEIR siguiendo las instrucciones en la sección M-BEIR .
Puede entrenar los modelos UniIR desde cero o descargar los puntos de control UniIR previamente entrenados siguiendo las instrucciones en la sección Model Zoo .
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/eval/inbatch/ Modifique embed.yaml , index.yaml , retrieval.yaml y run_eval_pipeline_inbatch.sh para su propio entorno, rutas y configuración de evaluación.
UniIR _DIR en run_eval_pipeline_inbatch.sh al directorio donde desea almacenar archivos grandes, incluidos los puntos de control, incrustaciones, índices y resultados de recuperación. Luego puede colocar el archivo clip_sf_large.pth en la siguiente ruta: $ UniIR _DIR /checkpoint/CLIP_SF/Large/Instruct/InBatch/clip_sf_large.pthmodel.ckpt_config en el archivo embed.yaml .MBEIR_DATA_DIR en run_eval_pipeline_inbatch.sh al directorio donde almacena el punto de referencia M-BEIR.SRC_DIR en run_eval_pipeline_inbatch.sh al directorio donde almacena el código base del proyecto UniIR (este repositorio). La configuración predeterminada evaluará el modelo UniIR CLIP_SF Large en los puntos de referencia M-BEIR (grupo de candidatos heterogéneos de 5,6 millones) y M-BEIR_local (grupo de candidatos homogéneos). UNION en los archivos yaml se refiere al M-BEIR (grupo de candidatos heterogéneos de 5,6 millones). Puede seguir los comentarios en los archivos yaml y modificar las configuraciones para evaluar el modelo únicamente en el punto de referencia M-BEIR_local.
bash run_eval_pipeline_inbatch.sh embed , index , logger y retrieval_results se guardarán en el directorio $ UniIR _DIR .
cd src/models/unii_blip/blip_featurefusion/configs_scripts/large/eval/inbatch/ De manera similar, si descarga nuestro modelo UniIR previamente entrenado, puede colocar el archivo blip_ff_large.pth en la siguiente ruta:
$ UniIR _DIR /checkpoint/BLIP_FF/Large/Instruct/InBatch/blip_ff_large.pthLa configuración predeterminada evaluará el modelo UniIR BLIP_FF Large en los puntos de referencia M-BEIR y M-BEIR_local.
bash run_eval_pipeline_inbatch.shLa evaluación UniRAG es muy similar a la evaluación predeterminada con las siguientes diferencias:
retrieval_results . Esto resulta útil cuando los resultados recuperados se utilizarán en aplicaciones posteriores como RAG.retrieve_image_text_pairs en retrieval.yaml se establece en True , se buscará un candidato de complemento para cada candidato con modalidad de solo text o image . Con esta configuración, el candidato y su complemento siempre tendrán modalidad image, text . Los candidatos complementarios se obtienen utilizando los candidatos originales como consultas (por ejemplo, texto de consulta -> imagen candidata -> texto candidato complementario ).InBatch e inbatch con UniRAG y unirag , respectivamente. Proporcionamos los puntos de control del modelo UniIR en el ? Puntos de control . Puede utilizar directamente los puntos de control para tareas de recuperación o ajustar los modelos para sus propias tareas de recuperación.
| Nombre del modelo | Versión | Tamaño del modelo | Enlace modelo |
|---|---|---|---|
| UniIR (CLIP-SF) | Grande | 5,13GB | Enlace de descarga |
| UniIR (BLIP-FF) | Grande | 7,49GB | Enlace de descarga |
Puedes descargarlos por
git clone https://huggingface.co/TIGER-Lab/UniIR
BibTeX:
@article { wei2023 UniIR ,
title = { UniIR : Training and benchmarking universal multimodal information retrievers } ,
author = { Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu } ,
journal = { arXiv preprint arXiv:2311.17136 } ,
year = { 2023 }
}

