Patron
1.0.0
Este repositorio contiene el código de nuestro artículo de ACL 2023: Selección de datos de inicio en frío para un ajuste fino del modelo de lenguaje de pocas oportunidades: un enfoque de propagación de la incertidumbre basado en indicaciones.
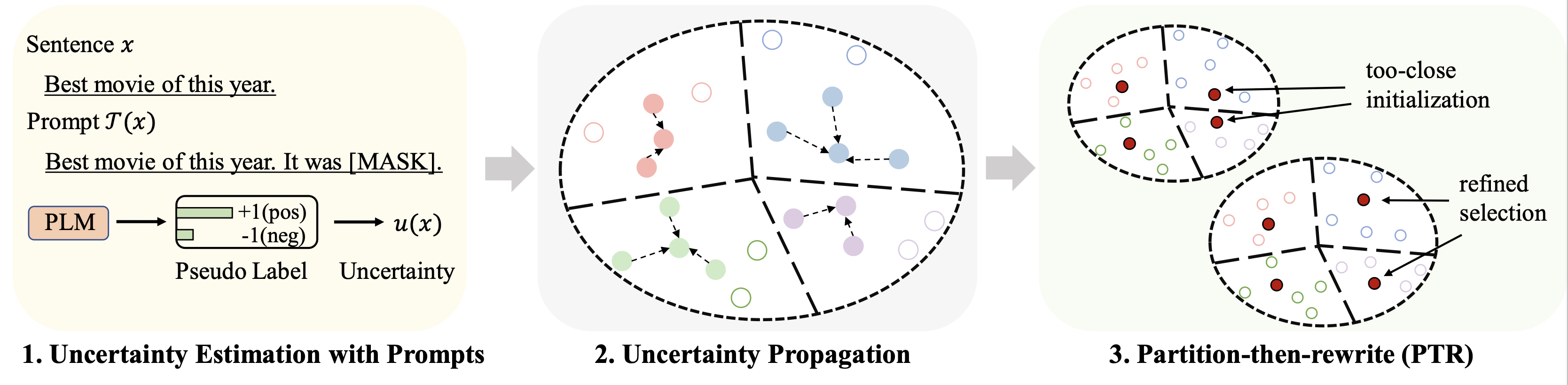
Los resultados de diferentes conjuntos de datos (utilizando 128 etiquetas como presupuesto) para el ajuste se resumen a continuación:
| Método | IMDB | Yelp completo | AGNoticias | Yahoo! | DBPedia | TREC | Significar |
|---|---|---|---|---|---|---|---|
| Supervisión completa (base RoBERTa) | 94.1 | 66,4 | 94.0 | 77,6 | 99,3 | 97,2 | 88.1 |
| Muestreo aleatorio | 86,6 | 47,7 | 84,5 | 60.2 | 95.0 | 85,6 | 76,7 |
| Mejor punto de referencia (Chang et al.2021) | 88,5 | 46.4 | 85,6 | 61.3 | 96,5 | 87,7 | 77,6 |
| Patron (Nuestro) | 89,6 | 51.2 | 87.0 | 65.1 | 97.0 | 91.1 | 80.2 |
Para el aprendizaje basado en indicaciones, utilizamos el mismo proceso que el LM-BFF. El resultado con 128 etiquetas se muestra a continuación.
| Método | IMDB | Yelp completo | AGNoticias | Yahoo! | DBPedia | TREC | Significar |
|---|---|---|---|---|---|---|---|
| Supervisión completa (base RoBERTa) | 94.1 | 66,4 | 94.0 | 77,6 | 99,3 | 97,2 | 88.1 |
| Muestreo aleatorio | 87,7 | 51.3 | 84,9 | 64,7 | 96.0 | 85.0 | 78.2 |
| Mejor punto de referencia (Yuan et al., 2020) | 88,9 | 51,7 | 87,5 | 65,9 | 96,8 | 86,5 | 79,5 |
| Patron (Nuestro) | 89,3 | 55,6 | 87,8 | 67,6 | 97,4 | 88,9 | 81.1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
Utilizamos los siguientes cuatro conjuntos de datos para los experimentos principales.
| Conjunto de datos | Tarea | Número de clases | Número de datos sin etiquetar/datos de prueba |
|---|---|---|---|
| IMDB | Sentimiento | 2 | 25k/25k |
| Yelp completo | Sentimiento | 5 | 39k/10k |
| Noticias AG | Tema de noticias | 4 | 119k/7,6k |
| Yahoo! Respuestas | Tema de control de calidad | 5 | 180k/30,1k |
| DBPedia | Tema de ontología | 14 | 280k/70k |
| TREC | Tema de la pregunta | 6 | 5k/0,5k |
Los datos procesados se pueden encontrar en este enlace. La carpeta para colocar estos conjuntos de datos se describirá en las siguientes partes.
Ejecute los siguientes comandos
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
Proporcionamos la pseudo predicción obtenida mediante indicaciones en el enlace anterior para conjuntos de datos. Consulte los documentos originales para obtener más detalles.
Ejecute los siguientes comandos (ejemplo en el conjunto de datos de AG News)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
Algunos hiperparámetros importantes:
rho : el parámetro utilizado para la propagación de la incertidumbre en la ecuación. 6 del papelbeta : la regularización de la distancia en la ecuación. 8 del papelgamma : el peso del término de regularización en la ecuación. 10 del papel Consulte la carpeta finetune para obtener instrucciones detalladas.
Consulte la carpeta prompt_learning para obtener instrucciones detalladas.
Vea este enlace como canal para generar predicciones basadas en indicaciones. Tenga en cuenta que necesita personalizar sus plantillas y verbalizadores de indicaciones.
Para generar las incrustaciones de documentos, puede seguir los comandos anteriores utilizando SimCSE.
Una vez que genere el índice para los datos seleccionados, podrá usar las canalizaciones en Running Fine-tuning Experiments y Running Prompt-based Learning Experiments para los experimentos de aprendizaje basados en indicaciones y ajustes finos de pocas tomas.
Por favor, cite el siguiente artículo si este repositorio le resulta útil para su investigación. ¡Gracias de antemano!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
Nos gustaría agradecer a los autores del repositorio SimCSE y OpenPrompt por el código bien organizado.


