CTCWordBeamSearch
1.0.0
Decodificador de Clasificación Temporal Conexionista (CTC) con diccionario y Modelo de Lenguaje (LM).
pip install .tests/ y ejecute pytest para comprobar si la instalación funcionó El siguiente ejemplo de juguete muestra cómo utilizar la búsqueda por haz de palabras. El modelo hipotético (por ejemplo, un modelo de reconocimiento de texto) es capaz de reconocer 3 caracteres diferentes: "a", "b" y " " (espacios en blanco). Las palabras en ese ejemplo de juguete pueden contener los caracteres "a" y "b" (pero no " ", que es el separador de palabras). El modelo de lenguaje se entrena a partir de un corpus de texto que contiene sólo dos palabras: "a" y "ba".
En este fragmento de código se crea una instancia de búsqueda por haz de palabras y se decodifica una matriz numpy con forma de TxBx(C+1):
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )El decodificador devuelve una lista con una cadena de etiqueta decodificada para cada elemento del lote. Para finalmente obtener las cadenas de caracteres, asigne cada etiqueta a su carácter correspondiente:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )Ejemplos:
tests/test_word_beam_search.py Parámetros del constructor de la clase WordBeamSearch :
0<len(wordChars)<len(chars) . En caso de que solo se deban detectar palabras individuales, no es necesario un carácter de separación, por lo que los dos parámetros también pueden ser iguales: 0<len(wordChars)<=len(chars) Entrada al método WordBeamSearch.compute :
La búsqueda por haz de palabras es un algoritmo de decodificación CTC. Se utiliza para tareas de reconocimiento de secuencias, como el reconocimiento de texto escrito a mano o el reconocimiento automático de voz.
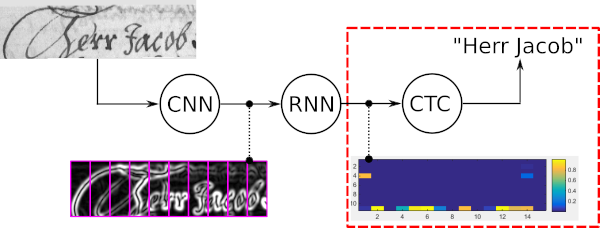
Las cuatro propiedades principales de la búsqueda por haz de palabras son:
El siguiente ejemplo muestra un caso de uso típico de búsqueda por haz de palabras junto con los resultados proporcionados por cinco decodificadores diferentes. La mejor decodificación de ruta y la búsqueda de haz básico interpretan mal las palabras, ya que estos decodificadores solo utilizan la salida ruidosa del modelo óptico. Ampliar la búsqueda de haz básico mediante un LM a nivel de personaje mejora el resultado al permitir solo secuencias de caracteres probables. El paso de tokens utiliza un diccionario y un LM a nivel de palabra y, por lo tanto, obtiene todas las palabras correctamente. Sin embargo, no puede reconocer cadenas de caracteres arbitrarias como números. La búsqueda por haz de palabras puede reconocer las palabras mediante el uso de un diccionario, pero también puede identificar correctamente los caracteres que no son palabras.

Más información:
extras/prototype/extras/tf/ Cite el siguiente artículo si utiliza la búsqueda por haces de palabras en su trabajo de investigación.
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


