KoGPT2 FineTuning
1.0.0
Usamos KoGPT2, que fue entrenado previamente por SKT-AI con aproximadamente 20 GB de datos coreanos. Primero, para escribir letras, ajustamos datos de letras refinadas, novelas, artículos, etc. cuyos derechos de autor han expirado, dando diferentes pesos a cada dato. También puede recibir géneros y ver los resultados de aprendizaje de letras para cada género musical.
Además, Colab ha vinculado Google Drive y Dropbbox para un aprendizaje fluido. Después de mover los resultados intermedios aprendidos de Google Drive a Dropbbox, elimine los resultados de Google Drive. Código relacionado con esto
Si resulta difícil trabajar con KoGPT2-FineTuning con el código modificado de la Versión 2, que recibe conjuntos de datos en formato CSV para cada género musical, utilice la Versión 1.1.
A continuación, puedes consultar los resultados de aprender varias letras coreanas. También trabajaremos en varios otros proyectos.

| peso | Género | lírica |
|---|---|---|
| 1100.0 | balada | 'Sabes cómo me sientonnnSolo te miro fijamente parado sin comprender como FaraónnnnNo tengo más remedio que rendirme...' |
| ... |
python main.py --epoch=200 --data_file_path=./dataset/lyrics_dataset.csv --save_path=./checkpoint/ --load_path=./checkpoint/genre/KoGPT2_checkpoint_296000.tar --batch_size=1
parser . add_argument ( '--epoch' , type = int , default = 200 ,
help = "epoch 를 통해서 학습 범위를 조절합니다." )
parser . add_argument ( '--save_path' , type = str , default = './checkpoint/' ,
help = "학습 결과를 저장하는 경로입니다." )
parser . add_argument ( '--load_path' , type = str , default = './checkpoint/Alls/KoGPT2_checkpoint_296000.tar' ,
help = "학습된 결과를 불러오는 경로입니다." )
parser . add_argument ( '--samples' , type = str , default = "samples/" ,
help = "생성 결과를 저장할 경로입니다." )
parser . add_argument ( '--data_file_path' , type = str , default = 'dataset/lyrics_dataset.txt' ,
help = "학습할 데이터를 불러오는 경로입니다." )
parser . add_argument ( '--batch_size' , type = int , default = 8 ,
help = "batch_size 를 지정합니다." )Puede ejecutar código de ajuste fino utilizando Colab.
function ClickConnect ( ) {
// 백엔드를 할당하지 못했습니다.
// GPU이(가) 있는 백엔드를 사용할 수 없습니다. 가속기가 없는 런타임을 사용하시겠습니까?
// 취소 버튼을 찾아서 클릭
var buttons = document . querySelectorAll ( "colab-dialog.yes-no-dialog paper-button#cancel" ) ;
buttons . forEach ( function ( btn ) {
btn . click ( ) ;
} ) ;
console . log ( "1분 마다 다시 연결" ) ;
document . querySelector ( "#top-toolbar > colab-connect-button" ) . click ( ) ;
}
setInterval ( ClickConnect , 1000 * 60 ) ; function CleanCurrentOutput ( ) {
var btn = document . querySelector ( ".output-icon.clear_outputs_enabled.output-icon-selected[title$='현재 실행 중...'] iron-icon[command=clear-focused-or-selected-outputs]" ) ;
if ( btn ) {
console . log ( "10분 마다 출력 지우기" ) ;
btn . click ( ) ;
}
}
setInterval ( CleanCurrentOutput , 1000 * 60 * 10 ) ; nvidia-smi.exe
python generator.py --temperature=1.0 --text_size=1000 --tmp_sent=""
python generator.py --temperature=5.0 --text_size=500 --tmp_sent=""
parser . add_argument ( '--temperature' , type = float , default = 0.7 ,
help = "temperature 를 통해서 글의 창의성을 조절합니다." )
parser . add_argument ( '--top_p' , type = float , default = 0.9 ,
help = "top_p 를 통해서 글의 표현 범위를 조절합니다." )
parser . add_argument ( '--top_k' , type = int , default = 40 ,
help = "top_k 를 통해서 글의 표현 범위를 조절합니다." )
parser . add_argument ( '--text_size' , type = int , default = 250 ,
help = "결과물의 길이를 조정합니다." )
parser . add_argument ( '--loops' , type = int , default = - 1 ,
help = "글을 몇 번 반복할지 지정합니다. -1은 무한반복입니다." )
parser . add_argument ( '--tmp_sent' , type = str , default = "사랑" ,
help = "글의 시작 문장입니다." )
parser . add_argument ( '--load_path' , type = str , default = "./checkpoint/Alls/KoGPT2_checkpoint_296000.tar" ,
help = "학습된 결과물을 저장하는 경로입니다." )Puede ejecutar el generador usando Colab.

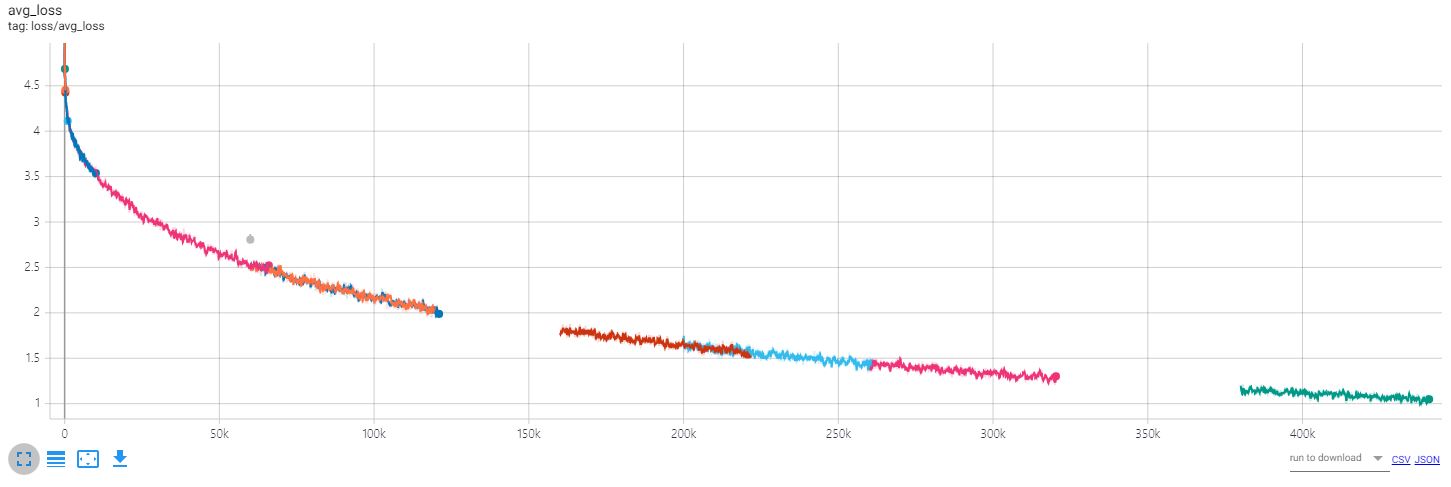
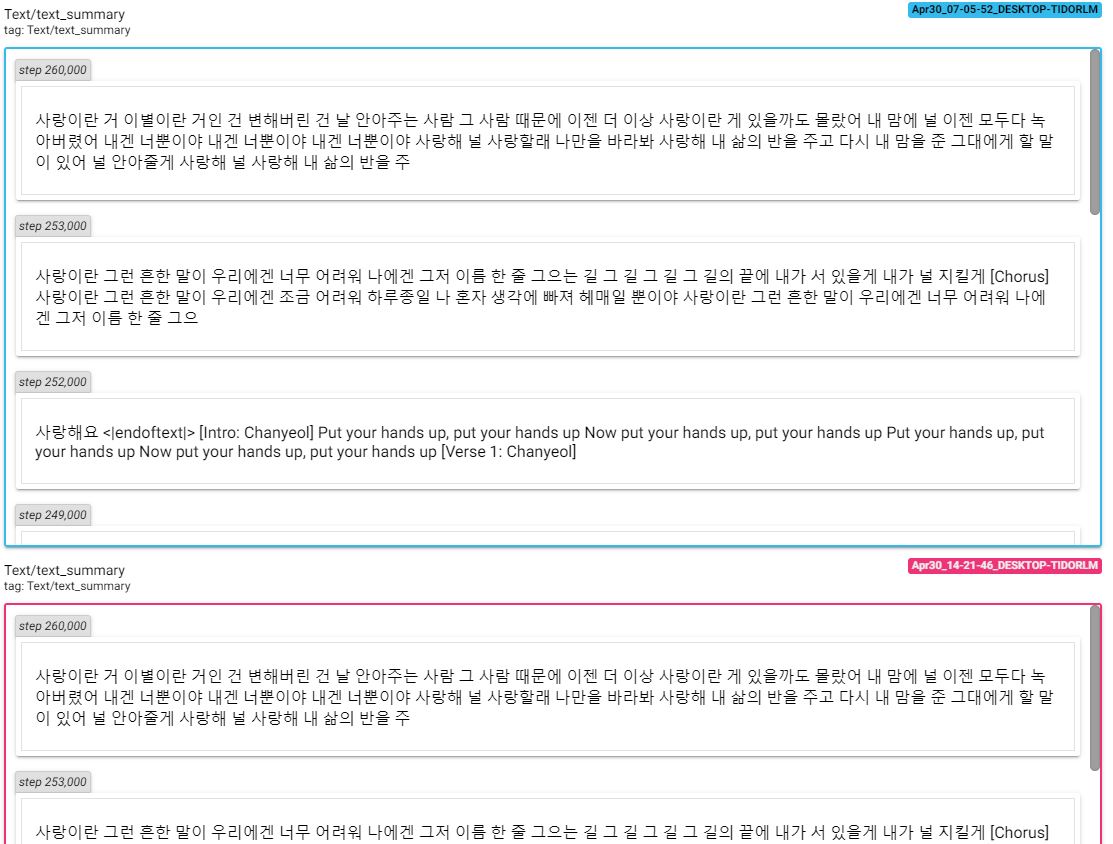
Para verificar los cambios debido al aprendizaje, acceda al tensorboard y verifique la pérdida y el texto.
tensorboard --logdir=runs
@misc{KoGPT2-FineTuning,
author = {gyung},
title = {KoGPT2-FineTuning},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gyunggyung/KoGPT2-FineTuning}},
}
Los resultados detallados se pueden encontrar en las muestras. Puede encontrar más información sobre el aprendizaje en publicaciones relacionadas.
https://github.com/openai/gpt-2
https://github.com/nshepperd/gpt-2
https://github.com/SKT-AI/KoGPT2
https://github.com/asyml/texar-pytorch/tree/master/examples/gpt-2
https://github.com/graykode/gpt-2-Pytorch
https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
https://github.com/shbictai/narrativeKoGPT2
https://github.com/ssut/py-hanspell
https://github.com/likejazz/korean-sentence-splitter


