Study Bot
1.0.0
Study-Bot es un proyecto de código abierto desarrollado por Edumakers del Tecnológico de Monterrey . Está diseñado para ayudar a los estudiantes con discapacidad visual a revisar el material de su curso académico. Es un compañero de estudio impulsado por inteligencia artificial que incorpora varias tecnologías, incluidas Whisper, GPT-3.5-turbo-16k, texto a voz de Elevenlabs y OpenCV. Para fines de prueba, se generó material del curso de muestra utilizando ChatGPT.
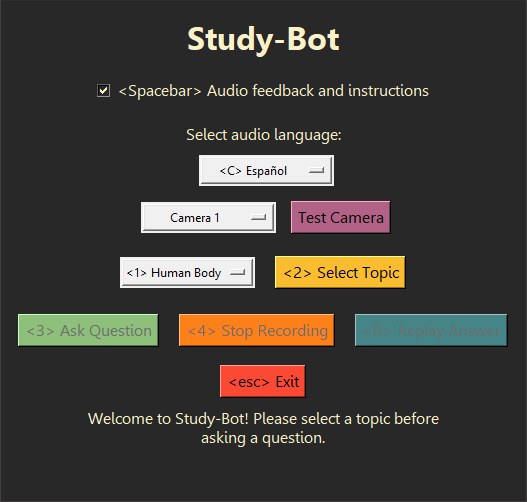
Study-Bot puede: escuchar la pregunta del usuario, analizar el material fuente del tema que desea estudiar, detectar el material educativo físico que tiene en sus manos por su color o marcador ArUco, generar una respuesta y leerlo en voz alta al usuario como una aplicación ejecutable accesible. Para fines de desarrollo y prueba, se puede ejecutar a través del intérprete de Python como un programa CLI o con una GUI .
Algunos buenos próximos pasos podrían ser integrar este sistema en una interfaz de usuario más avanzada para distribuirlo como una aplicación de escritorio, crear un modelo de visión por computadora que pueda detectar el material educativo físico sin depender del color o los marcadores ArUco, así como algunas mejoras de rendimiento y nuevas funciones interactivas.
Se recomienda utilizar Python 3.9.9 para que la biblioteca whisper se pueda utilizar sin problemas. Para evitar tener que eliminar su instalación actual de Python , es posible que desee utilizar un entorno virtual para utilizar esta versión específica de Python . Para instalar las dependencias requeridas, ejecute el siguiente comando:
pip install -r requirements.txt Hay algunos pasos adicionales que se deben seguir antes de poder ejecutar el proyecto, como la adquisición de sus propias claves API para los servicios de IA utilizados aquí. Para obtener más información, consulte la carpeta Documentation para obtener una guía completa sobre cómo utilizar este proyecto.
Study-Bot se basa en los siguientes servicios y tecnologías existentes:
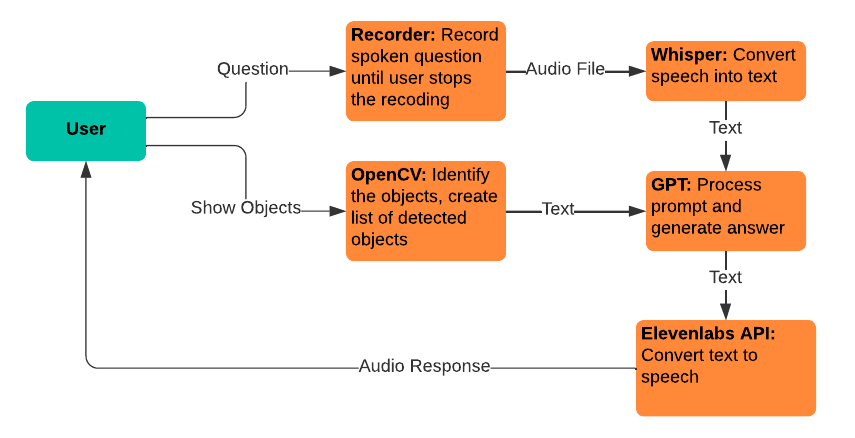
Whisper: se utiliza para la conversión de voz a texto, lo que permite a los usuarios expresar sus preguntas para introducirlas en el modelo GPT.
gpt-3.5-turbo-16k: Se utiliza para procesar preguntas y generar respuestas. Se eligió la versión de 16k del modelo por su tamaño de ventana de contexto de 16.385 tokens, que es necesario para procesar una gran cantidad de material fuente.
Texto a voz de Elevenlabs: se utiliza para la conversión de texto a voz, lo que permite a los usuarios escuchar las respuestas generadas por el modelo GPT.
OpenCV: se utiliza para la identificación de objetos físicos, para ayudar al modelo GPT-3.5-16k a responder preguntas con el contexto adicional de lo que sostiene el usuario.
Utilice este proyecto como referencia para el suyo o bifurquelo para hacer sus propias contribuciones. Los problemas de GitHub relacionados con solicitudes de funciones e informes de errores son bienvenidos y especialmente valorados si incluyen comentarios de usuarios con discapacidad visual.


