Proyecto de recuperación-generación aumentada (RAG)
If this project helps you, consider buying me a coffee ☕. Your support helps me keep contributing to the open-source community!
La plataforma oficial de bRAGAI se lanzará pronto. ¡Únase a la lista de espera para ser uno de los primeros en adoptar!
Este repositorio contiene una exploración exhaustiva de la generación aumentada de recuperación (RAG) para diversas aplicaciones. Cada cuaderno proporciona una guía práctica detallada para configurar y experimentar con RAG desde un nivel introductorio hasta implementaciones avanzadas, incluidas consultas múltiples y compilaciones RAG personalizadas.
Estructura del proyecto
Si desea acceder directamente a él, consulte el archivo full_basic_rag.ipynb -> este archivo le proporcionará un código inicial estándar de un chatbot RAG totalmente personalizable.
Asegúrese de ejecutar sus archivos en un entorno virtual (sección de pago Get Started )
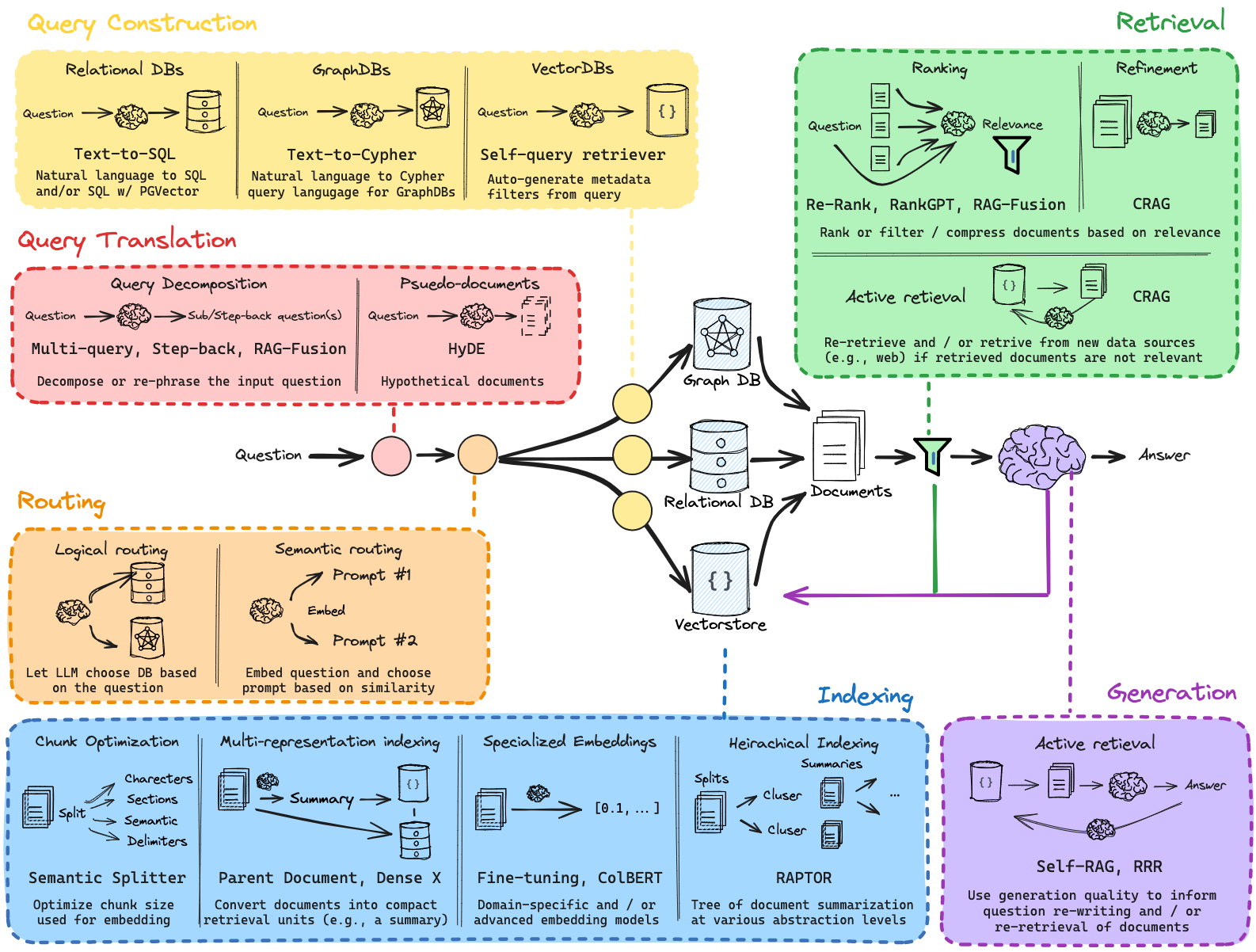
Los siguientes cuadernos se pueden encontrar en el directorio tutorial_notebooks/ .
[1]_rag_setup_overview.ipynb
Este cuaderno introductorio proporciona una descripción general de la arquitectura RAG y su configuración fundamental. El cuaderno recorre:
- Configuración del entorno : configuración del entorno, instalación de las bibliotecas necesarias y configuraciones de API.
- Carga de datos inicial : cargadores de documentos básicos y métodos de preprocesamiento de datos.
- Generación de incrustaciones : generación de incrustaciones utilizando varios modelos, incluidas las incrustaciones de OpenAI.
- Tienda de vectores : configuración de una tienda de vectores (ChromaDB/Pinecone) para una búsqueda eficiente de similitudes.
- Canalización RAG básica : creación de una canalización de recuperación y generación simple que sirva como línea de base.
[2]_rag_with_multi_query.ipynb
Partiendo de los conceptos básicos, este cuaderno presenta técnicas de consultas múltiples en el proceso RAG y explora:
- Configuración de consultas múltiples : configuración de múltiples consultas para diversificar la recuperación.
- Técnicas de incrustación avanzadas : utilización de múltiples modelos de incrustación para refinar la recuperación.
- Canalización con consultas múltiples : implementación del manejo de consultas múltiples para mejorar la relevancia en la generación de respuestas.
- Comparación y análisis : comparación de resultados con canalizaciones de consulta única y análisis de mejoras de rendimiento.
[3]_rag_routing_and_query_construction.ipynb
Este cuaderno profundiza en la personalización de un pipeline RAG. Cubre:
- Enrutamiento lógico: implementa enrutamiento basado en funciones para clasificar las consultas de los usuarios en fuentes de datos apropiadas basadas en lenguajes de programación.
- Enrutamiento semántico: utiliza incrustaciones y similitudes de cosenos para dirigir preguntas a una pregunta de matemáticas o física, optimizando la precisión de la respuesta.
- Estructuración de consultas para filtros de metadatos: define un esquema de búsqueda estructurado para los metadatos del tutorial de YouTube, lo que permite el filtrado avanzado (por ejemplo, por recuento de vistas, fecha de publicación).
- Solicitud de búsqueda estructurada: aprovecha las indicaciones de LLM para generar consultas de bases de datos para recuperar contenido relevante según la entrada del usuario.
- Integración con Vector Stores: vincula consultas estructuradas a almacenes de vectores para una recuperación de datos eficiente.
[4]_rag_indexing_and_advanced_retrieval.ipynb
Continuando con la personalización anterior, este cuaderno explora:
- Prefacio sobre fragmentación de documentos: señala recursos externos para técnicas de fragmentación de documentos.
- Indexación de representaciones múltiples: configura una estructura de indexación de múltiples vectores para manejar documentos con diferentes incrustaciones y representaciones.
- Almacenamiento en memoria para resúmenes: utiliza InMemoryByteStore para almacenar resúmenes de documentos junto con los documentos principales, lo que permite una recuperación eficiente.
- Configuración de MultiVectorRetriever: integra múltiples representaciones vectoriales para recuperar documentos relevantes según las consultas de los usuarios.
- Implementación de RAPTOR: explora RAPTOR, un modelo avanzado de indexación y recuperación, que vincula a recursos detallados.
- Integración ColBERT: demuestra la indexación y recuperación de vectores a nivel de token basada en ColBERT, que captura el significado contextual en un nivel detallado.
- Ejemplo de Wikipedia con ColBERT: recupera información sobre Hayao Miyazaki utilizando el modelo de recuperación ColBERT para demostración.
[5]_rag_retrieval_and_reranking.ipynb
Este cuaderno final reúne los componentes del sistema RAG, con un enfoque en la escalabilidad y la optimización:
- Carga y división de documentos: carga y fragmenta documentos para indexarlos, preparándolos para el almacenamiento vectorial.
- Generación de consultas múltiples con RAG-Fusion: utiliza un enfoque basado en indicaciones para generar múltiples consultas de búsqueda a partir de una única pregunta de entrada.
- Fusión de clasificación recíproca (RRF): implementa RRF para reclasificar múltiples listas de recuperación, fusionando resultados para mejorar la relevancia.
- Configuración de cadena RAG y recuperador: construye una cadena de recuperación para responder consultas, utilizando clasificaciones fusionadas y cadenas RAG para extraer información contextualmente relevante.
- Reclasificación de Cohere: demuestra la reclasificación con el modelo de Cohere para una compresión y refinamiento contextual adicional.
- Recuperación de CRAG y Self-RAG: explora enfoques de recuperación avanzados como CRAG y Self-RAG, con enlaces a ejemplos.
- Exploración del impacto de contexto largo: enlaces a recursos que explican el impacto de la recuperación de contexto largo en modelos RAG.
Empezando
Requisitos previos: Python 3.11.7 (preferido)
Clonar el repositorio :
git clone https://github.com/bRAGAI/bRAG-langchain.git
cd bRAG-langchain
Crear un entorno virtual
python -m venv venv
source venv/bin/activate
Instalar dependencias : asegúrese de instalar los paquetes requeridos enumerados en requirements.txt .
pip install -r requirements.txt
Ejecute los cuadernos : comience con [1]_rag_setup_overview.ipynb para familiarizarse con el proceso de configuración. Continúe secuencialmente con los otros cuadernos para desarrollar y experimentar con conceptos RAG más avanzados.
Configurar variables de entorno :
Orden del cuaderno : Para seguir el proyecto de forma estructurada:
Comience con [1]_rag_setup_overview.ipynb
Continúe con [2]_rag_with_multi_query.ipynb
Luego vaya a [3]_rag_routing_and_query_construction.ipynb
Continúe con [4]_rag_indexing_and_advanced_retrieval.ipynb
Terminar con [5]_rag_retrieval_and_reranking.ipynb
Uso
Después de configurar el entorno y ejecutar los cuadernos en secuencia, puede:
Experimente con la generación aumentada de recuperación : utilice la configuración básica en [1]_rag_setup_overview.ipynb para comprender los conceptos básicos de RAG.
Implementar consultas múltiples : aprenda cómo mejorar la relevancia de la respuesta mediante la introducción de técnicas de consultas múltiples en [2]_rag_with_multi_query.ipynb .
Cuadernos entrantes (trabajo en progreso)
- Precisión del contexto con RAGAS + LangSmith
- Guía sobre el uso de RAGAS y LangSmith para evaluar la precisión del contexto, la relevancia y la precisión de la respuesta en RAG.
- Implementación de la aplicación RAG
- Guía sobre cómo implementar su aplicación RAG
The notebooks and visual diagrams were inspired by Lance Martin's LangChain Tutorial.


