Cronología de ChatGPT, GenerativeAI y LLM
Este repositorio organiza una cronología de eventos clave (productos, servicios, artículos, GitHub, publicaciones de blogs y noticias) que ocurrieron antes y después del anuncio de ChatGPT.
Está seleccionando una variedad de información en esta línea de tiempo, con un enfoque particular en LLM y IA generativa.
Tal vez sea una escena de la historia más candente, así que pensé que sería importante conservar bien esos recuerdos, así que los organicé.
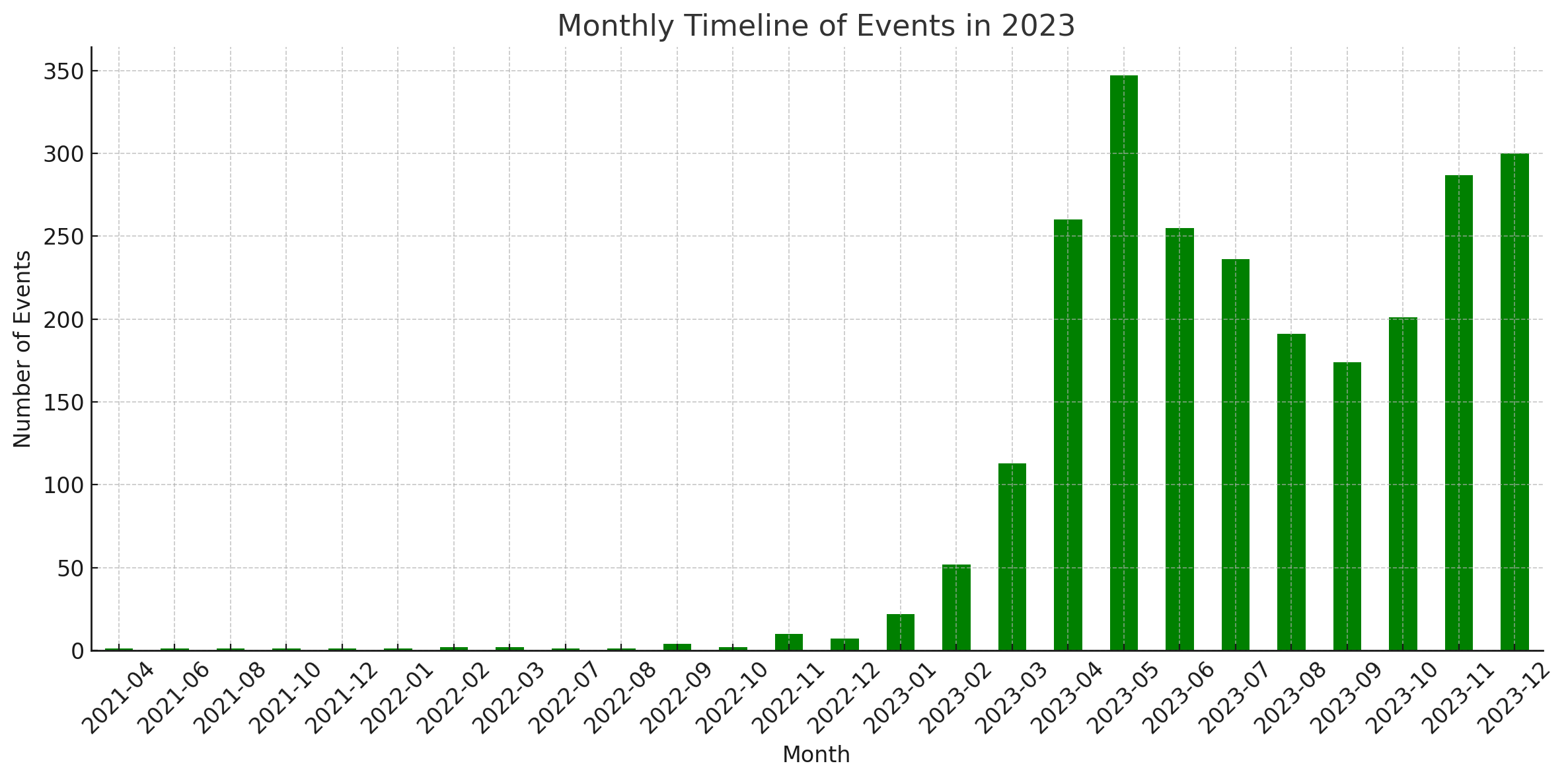
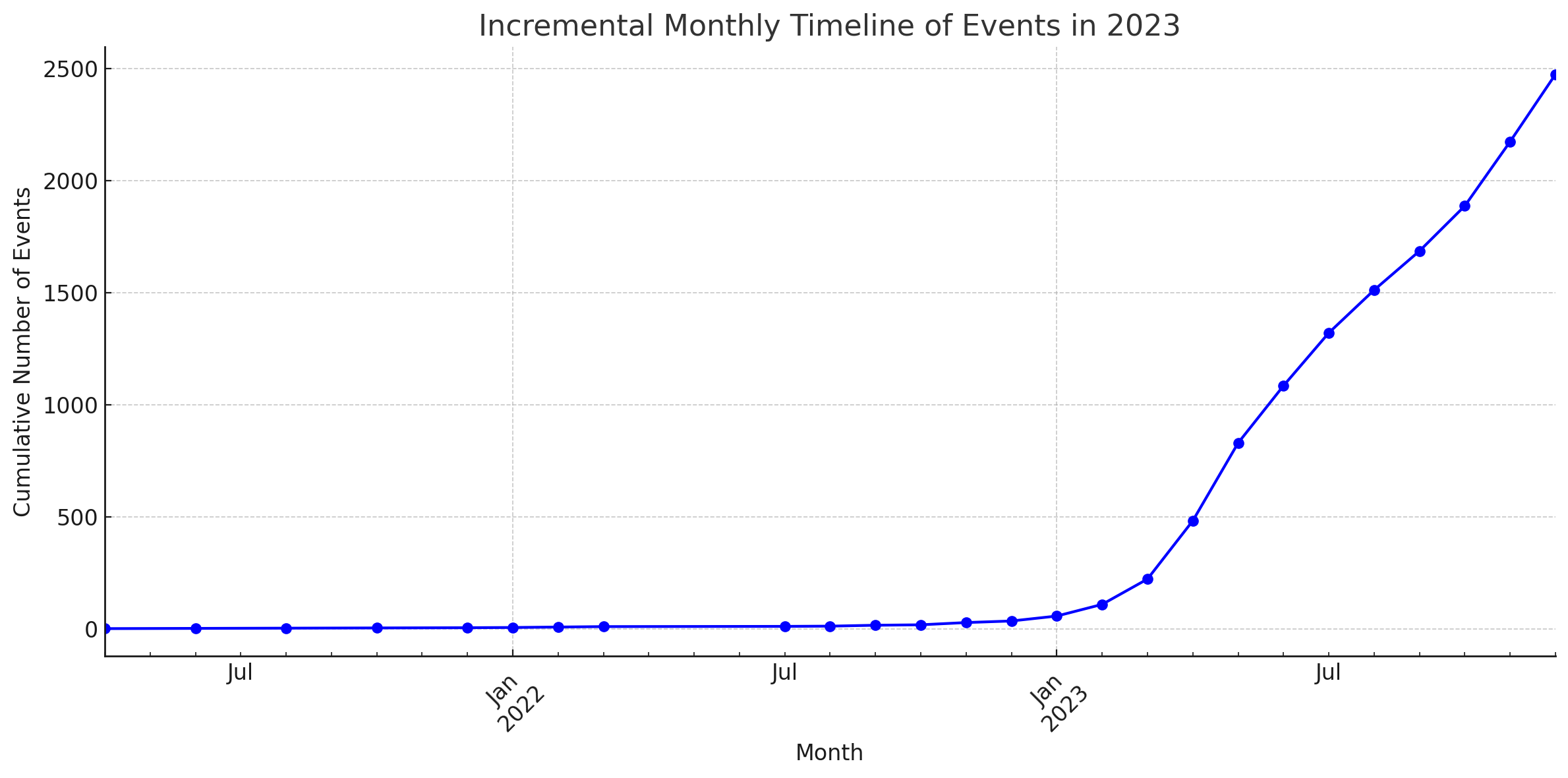
Estadística
Estos diagramas fueron generados por el intérprete de código de ChatGPT.
Contribuyendo
Se agradecen mucho los problemas y las solicitudes de extracción. Si nunca antes ha contribuido a un proyecto de código abierto, estaré más que feliz de explicarle cómo crear una solicitud de extracción.
Puede comenzar abriendo un problema que describa el problema que desea resolver y continuaremos desde allí.
emojis
arXiv, PDF?, arxiv-vanity?, página en papel?, artículos con código ✳️, Github
Licencia
Este documento está bajo la licencia MIT © Jonghong Jeon (전종홍)
Línea de tiempo V2
2024
- 17/05: OpenAI llega a un acuerdo con Reddit para entrenar su IA en sus publicaciones
(Noticias), - 17/05: OpenAI disuelve el equipo centrado en los riesgos de la IA a largo plazo, menos de un año después de anunciarlo
(Noticias), - 17/05 - Informe científico internacional sobre la seguridad de la IA avanzada
(Blog), - 16/05 - TRANSIC: Transferencia de políticas de Sim a Real mediante el aprendizaje de la corrección en línea
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Toon3D: Ver dibujos animados desde una nueva perspectiva
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Probando la confiabilidad de un modelo de lenguaje grande basado en IA para extraer información ecológica de la literatura científica
(Noticias), - 16/05 - Aprendizaje en contexto de muchas tomas en modelos de base multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Cómo hacer una pausa en la IA antes de que sea demasiado tarde
(Noticias), - 16/05 - Puesta a tierra DINO 1.5: avance el "borde" de la detección de objetos abiertos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Minería y análisis de la tienda GPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Dual3D: Generación de texto a 3D eficiente y consistente con difusión latente multivista de modo dual
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Chameleon: Modelos básicos de fusión temprana de modos mixtos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - CAT3D: cree cualquier cosa en 3D con modelos de difusión multivista
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - Xmodel-VLM: una base simple para el modelo de lenguaje de visión multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - LoRA aprende menos y olvida menos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05: la marca de agua invisible de IA de Google ayudará a identificar texto y video generativos
(Noticias), - 15/05 - Google I/O 2024: todo anunciado
(Blog), - 15/05 - BEHAVIOR Vision Suite: Generación de conjuntos de datos personalizables mediante simulación
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - ALPINE: Revelando la capacidad de planificación del aprendizaje autorregresivo en modelos lingüísticos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05: Comprender la brecha de rendimiento entre los algoritmos de alineación en línea y fuera de línea
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - SpeechVerse: un modelo de lenguaje de audio generalizable a gran escala
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - SpeechGuard: Explorando la solidez adversa de los modelos de lenguajes grandes multimodales
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05: No hay tiempo que perder: aproveche el tiempo en el canal para comprender los vídeos móviles
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Hunyuan-DiT: un potente transformador de difusión de resolución múltiple con un conocimiento chino detallado
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Generación compositiva de texto a imagen con representaciones de manchas densas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Más allá de las leyes de escala: comprensión del rendimiento del transformador con memoria asociativa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - SambaNova SN40L: Escalando el muro de la memoria de la IA con flujo de datos y composición de expertos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - Flujo de trabajo de RLHF: del modelado de recompensas al RLHF en línea
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - Plot2Code: un punto de referencia integral para evaluar modelos de lenguajes grandes multimodales en la generación de código a partir de gráficos científicos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05: OpenAI presenta el modelo de IA más nuevo, GPT-4o
(Noticias), - 13/05 - Búsqueda web de MS MARCO: un conjunto de datos web rico en información a gran escala con millones de etiquetas de clics reales
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - ¿Cuánta investigación se está escribiendo mediante modelos de lenguaje grandes?
(Blog), - 13/05 - Hola GPT-4o
(Blog), - 13/05 - Coin3D: Generación de activos 3D controlables e interactivos con acondicionamiento guiado por proxy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 11/05 - Piccolo2: Incrustación de texto general con entrenamiento de pérdida híbrida multitarea
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 11/05 - LogoMotion: Generación de código visualmente fundamentado para animación basada en contenido
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 10/05 - INSPECT - Un marco de código abierto para evaluaciones de modelos de lenguaje grandes
(Blog), - 10/05: AI Safety Institute lanza una nueva plataforma de evaluaciones de seguridad de IA
(Noticias), - 07/05 - SUTRA: Arquitectura de modelo de lenguaje multilingüe escalable
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 07/05 - Meta lanza Llama 3 LLM de código abierto
(Noticias), - 03/05 - ¿Qué importa a la hora de construir modelos visión-lenguaje?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - WildChat: 1 millón de registros de interacción de ChatGPT en la naturaleza
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - StoryDiffusion: Autoatención constante para la generación de imágenes y vídeos de largo alcance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - Prometheus 2: Un modelo de lenguaje de código abierto especializado en evaluar otros modelos de lenguaje
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - NeMo-Aligner: kit de herramientas escalable para una alineación eficiente de modelos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - LLM-AD: Sistema de descripción de audio basado en modelos de lenguaje grande
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - FLAME: Alineación basada en hechos para modelos de lenguaje grandes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05: Personalización de modelos de texto a imagen con un único par de imágenes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - Campos gaussianos podados espectralmente con compensación neuronal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - Optimización de preferencias de reproducción automática para la alineación del modelo de lenguaje
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - ¿Es siempre mejor un tamaño de lote de edición más grande? -- Un estudio empírico sobre la edición de modelos con Llama-3
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - Clover: Decodificación especulativa ligera regresiva con conocimiento secuencial
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05: Un examen cuidadoso del rendimiento del modelo de lenguaje grande en la aritmética de la escuela primaria
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Visual Fact Checker: Habilitación de la generación de subtítulos detallados de alta fidelidad
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - STT: Seguimiento de estado con transformadores para conducción autónoma
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - SemantiCodec: un códec de audio semántico con tasa de bits ultrabaja para sonido general
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Octopus v4: Gráfica de modelos de lenguaje
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - MotionLCM: Generación de movimiento controlable en tiempo real mediante un modelo de consistencia latente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - MicroDreamer: Generación 3D de disparo cero en sim20 segundos mediante reconstrucción iterativa basada en puntuaciones
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Lightplane: Componentes altamente escalables para campos neuronales 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - KAN: Redes Kolmogorov-Arnold
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Optimización de preferencias de razonamiento iterativo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Puntada invisible: generación de escenas 3D suaves con profundidad en la pintura
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - InstantFamily: Atención enmascarada para la generación de imágenes de identificación múltiple sin disparo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - GS-LRM: Modelo de reconstrucción grande para salpicaduras gaussianas 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Ampliando el contexto de Llama-3 diez veces de la noche a la mañana
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - DOCCI: Descripciones de imágenes conectadas y contrastantes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04: Modelos de lenguaje grande mejores y más rápidos mediante predicción de tokens múltiples
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Stylus: Selección automática de adaptadores para modelos de difusión
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - SAGS: Salpicadura gaussiana 3D con reconocimiento de estructura
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Reemplazo de jueces por jurados: evaluación de generaciones LLM con un panel de modelos diversos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Perfil de IA generativa NIST AI RMF
(Noticias), - 29/04 - LoRA Land: 310 LLM perfeccionados que rivalizan con GPT-4, un informe técnico
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Canguro: Decodificación autoespeculativa sin pérdidas mediante salida anticipada doble
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Capacidades de los modelos Géminis en medicina
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28/04 - Paint by Inpaint: aprender a agregar objetos de imagen eliminándolos primero
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28/04 - LEGENT: Plataforma abierta para agentes incorporados
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 27/04 - Ag2Manip: Aprendiendo nuevas habilidades de manipulación con representaciones visuales y de acción independientes del agente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26/04 - MaPa: Pintura de materiales fotorrealista basada en texto para formas 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26/04 - BlenderAlchemy: Edición de gráficos 3D con modelos Vision-Language
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Informe Técnico Tele-FLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - SEED-Bench-2-Plus: Evaluación comparativa de modelos de lenguaje grande multimodal con comprensión visual rica en texto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Revisando la evaluación de texto a imagen con Gecko: sobre métricas, indicaciones y calificaciones humanas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - PLLaVA: Extensión LLaVA sin parámetros de imágenes a videos para subtítulos densos de videos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Haga que su LLM aproveche al máximo el contexto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Enumere elementos uno por uno: una nueva fuente de datos y paradigma de aprendizaje para LLM multimodales
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Salto de capa: habilitación de la inferencia de salida temprana y la decodificación autoespeculativa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Interactive3D: Crea lo que quieras mediante la generación 3D interactiva
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - ¿Qué tan lejos estamos de GPT-4V? Cerrando la brecha con los modelos multimodales comerciales con suites de código abierto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - ConsistentID: Generación de retratos con preservación de identidad detallada multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - XC-Cache: Atención cruzada al contexto almacenado en caché para una inferencia LLM eficiente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - La ética de los asistentes avanzados de IA
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - PuLID: Personalización de ID pura y Lightning mediante alineación contrastiva
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - NeRF-XL: Escalado de NeRF con múltiples GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MotionMaster: Transferencia de movimiento de cámara sin entrenamiento para generación de video
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - Modo: CLIP Data Experts a través de clustering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MMT-Bench: un punto de referencia multimodal integral para evaluar modelos de visión y lenguaje de gran tamaño hacia una AGI multitarea
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MaGGIe: Estera de instancia humana gradual guiada enmascarada
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - ID-Aligner: Mejora de la generación de texto a imagen para preservar la identidad con aprendizaje de retroalimentación de recompensa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - Elementos de imagen editables para síntesis controlable
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - CatLIP: Precisión de reconocimiento visual a nivel de CLIP con un entrenamiento previo 2,7 veces más rápido en datos de imagen y texto a escala web
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - BASS: muestreo especulativo por lotes optimizado para la atención
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Los transformadores pueden representar modelos de lenguaje n-gram
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Informe técnico de Pegasus-v1
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Mezcla de expertos de múltiples jefes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - FlashSpeech: Síntesis de voz eficiente Zero-Shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - SnapKV: LLM sabe lo que busca antes de la generación
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - SEED-X: Modelos multimodales con comprensión y generación unificadas de multigranularidad
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Reconstrucción de coordenadas de escena: planteamiento de colecciones de imágenes mediante el aprendizaje incremental de un relocalizador
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Informe técnico de Phi-3: un modelo de lenguaje altamente capaz localmente en su teléfono
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - OpenELM: una familia de modelos de lenguaje eficiente con marco de inferencia y capacitación de código abierto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - MultiBooth: Hacia generar todos tus conceptos en una imagen a partir de texto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Aprendizaje del control de locomoción H-Infinity
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - ¿Qué tan buenos son los modelos LLaMA3 cuantificados de bits bajos? Un estudio empírico
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Alinee sus pasos: optimización de programas de muestreo en modelos de difusión
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Un agente de interpretabilidad automatizado multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21/04 - Hyper-SD: Modelo de consistencia segmentada de trayectoria para una síntesis de imágenes eficiente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21/04 - AdvPrompter: indicaciones adversas adaptativas rápidas para LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 20/04 - Modelos de consistencia musical
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - La jerarquía de instrucción: capacitación de LLM para priorizar instrucciones privilegiadas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - TextSquare: Ampliación del ajuste de instrucciones visuales centradas en texto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - PhysDreamer: Interacción basada en la física con objetos 3D mediante generación de vídeo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - LLM-R2: un sistema de reescritura basado en reglas mejorado con modelo de lenguaje grande para aumentar la eficiencia de las consultas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - ¿Qué tan real es lo real? Un marco de evaluación humana para ejemplos contradictorios sin restricciones
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - ¿Hasta dónde podemos llegar con la reparación práctica de programas a nivel de función?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - Groma: Tokenización visual localizada para conectar modelos de lenguajes grandes multimodales
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - ¿La dispersión gaussiana necesita inicialización SFM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - AutoCrawler: un agente web de comprensión progresiva para la generación de rastreadores web
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - TriForce: Aceleración sin pérdidas de generación de secuencia larga con decodificación especulativa jerárquica
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Hacia la superación personal de los LLM a través de la imaginación, la búsqueda y la crítica
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Reutilice sus recompensas: transferencia de modelo de recompensa para la alineación interlingual Zero-Shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Reka Core, Flash y Edge: una serie de potentes modelos de lenguaje multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - OpenBezoar: Modelos pequeños, rentables y abiertos entrenados en combinaciones de datos de instrucción
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - MeshLRM: Modelo de reconstrucción grande para malla de alta calidad
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04: Presentamos la versión 0.5 del AI Safety Benchmark de MLCommons
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Presentamos Meta Llama 3: el LLM disponible abiertamente más capaz hasta la fecha
(Blog), - 18/04 - EdgeFusion: Generación de texto a imagen en el dispositivo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - BLINK: Los modelos multimodales de lenguaje grande pueden ver pero no percibir
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - AniClipart: Animación de imágenes prediseñadas con antecedentes de texto a vídeo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - MoA: combinación de atención para desenredar sujeto-contexto en la generación de imágenes personalizadas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - FlowMind: Generación automática de flujos de trabajo con LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - Tipografía dinámica: dando vida a las palabras
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04: La API de Difusión Estable 3 ya está disponible
(twitter), (Blog), (Demostración), - 16/04 - VASA-1: Caras parlantes realistas impulsadas por audio generadas en tiempo real
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 16/04 - La Secretaria de Comercio de EE. UU., Gina Raimondo, anuncia la expansión del equipo de liderazgo del Instituto de Seguridad de IA de EE. UU.
(Noticias), - 16/04 - Generación de música de larga duración con difusión latente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/04 - Evaluadores de LLM reconocen y favorecen a sus propias generaciones
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/04 - Video2Game: Entorno en tiempo real, interactivo, realista y compatible con navegador a partir de un único vídeo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Tango 2: Alineación de generaciones de texto a audio basadas en difusión mediante la optimización directa de preferencias
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 15/04 - Domar el modelo de difusión latente para la pintura del campo de radiación neuronal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 – Opus puede funcionar como una máquina de Turing
(gorjeo), - 15/04 - MathGPT: Aprovechando Llama 2 para crear una plataforma para un aprendizaje altamente personalizado
- 15/04 - HQ-Edit: un conjunto de datos de alta calidad para la edición de imágenes basada en instrucciones
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Ctrl-Adapter: Un marco eficiente y versátil para adaptar diversos controles a cualquier modelo de difusión
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - La compresión representa la inteligencia linealmente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - CompGS: Representación eficiente de escenas 3D mediante salpicaduras gaussianas comprimidas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 14/04 - TextHawk: Explorando la percepción eficiente y detallada de modelos de lenguajes grandes multimodales
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 13/04: Cathie Wood entra en el auge de ChatGPT con una nueva participación en OpenAI
(Noticias), - 12/04 - CLIP de reducción de escala: un análisis integral de datos, arquitectura y estrategias de capacitación
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - Sondeando la conciencia 3D de los modelos de base visual
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12/04: Entrenamiento previo de LM de base pequeña con menos tokens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12/04 - Sobre la solidez de la orientación lingüística para tareas de visión de bajo nivel: hallazgos de la estimación de profundidad
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12/04 - MonoPatchNeRF: Mejora de los campos de radiación neuronal con guía monocular basada en parches
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - Megalodon: preentrenamiento e inferencia eficientes de LLM con longitud de contexto ilimitada
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12/04 - ¿ChatGPT está transformando el estilo de escritura de los académicos?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - COCONut: Modernizando la segmentación de COCO
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04: El chip de IA reduce el presupuesto de energía en más del 99 por ciento
(Noticias), - 12/04 - AdapterSwap: Formación continua de LLM con garantías de eliminación de datos y control de acceso
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - Vista previa de Grok-1.5 Vision
(Manifestación), - 12/04 - Lo bueno, lo malo y lo Humano Pin
(Noticias), - 12/04: Los usuarios pagos de ChatGPT ahora pueden acceder a GPT-4 Turbo
(twitter), (Noticias), , () - 11/04 - La necesidad de juntas de normas de auditoría de IA
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 11/04 - Recordando a Transformer para un aprendizaje continuo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 – Amazon incorpora a Andrew Ng, una voz líder en inteligencia artificial, a su junta directiva
(Noticias), - 11/04: Adobe está comprando videos por $3 por minuto para construir un modelo de IA
(Noticias), - 11/04 - UltraEval: una plataforma liviana para una evaluación flexible y completa para LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 11/04 - Eficiencia transferible y basada en principios para la segmentación de vocabulario abierto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - Agente SWE
(twitter), (Demostración), , () - 11/04 - Formador de carriles dispersos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Rho-1: No todas las fichas son lo que necesitas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 11/04 - ResearchAgent: Generación iterativa de ideas de investigación sobre literatura científica con modelos de lenguaje grandes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - RecurrentGemma: Superando a los transformadores para lograr modelos de lenguaje abierto eficientes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - OSWorld: Evaluación comparativa de agentes multimodales para tareas abiertas en entornos informáticos reales
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - LLoCO: Aprender contextos largos sin conexión
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04: Aprovechamiento de modelos de lenguaje grandes (LLM) para respaldar la anotación colaborativa de datos de riesgo en línea entre humanos e IA
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - JetMoE: Alcanzando el rendimiento de Llama2 con 0,1M de dólares
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (Proyecto), (twitter), , (✳️), () - 11/04 - HGRN2: RNN lineales cerrados con expansión estatal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 11/04 - De las palabras a los números: su modelo de lenguaje grande es secretamente un regresor capaz cuando se le dan ejemplos en contexto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Ferret-v2: una línea de base mejorada para referencias y conexión a tierra con modelos de lenguaje grandes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - ControlNet++: Mejora de los controles condicionales con retroalimentación de coherencia eficiente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04: Detección de anomalías de vídeo contextual en conjuntos de datos a largo plazo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - ChatGPT-3.5, Claude 3 patea traseros pixelados en el torneo Street Fighter III para LLM
(Noticias), - 11/04 - ChatGPT puede predecir el futuro cuando cuenta historias ambientadas en el futuro sobre el pasado
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Mejores prácticas y lecciones aprendidas sobre datos sintéticos para modelos de lenguaje
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Compara LLM peleando en Street Fighter 3
(Demostración), , () - 11/04 - Diálogos de audio: conjunto de datos de diálogos para la comprensión del audio y la música
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - La aplicación de orientación en un intervalo limitado mejora la calidad de la muestra y la distribución en los modelos de difusión
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - AmpleGCG: Aprendizaje de un modelo generativo universal y transferible de sufijos adversarios para jailbreak en LLM abiertos y cerrados
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 10/04 - LM Transparency Tool: Herramienta interactiva para analizar modelos de lenguaje de transformadores
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Gemini 1.5 Pro ahora entiende audio
(gorjeo), - 10/04 - Exploración de la profundidad del concepto: ¿Cómo los modelos de lenguaje grandes adquieren conocimiento en diferentes capas?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 10/04 - Arquitecto urbano: Generación de escena urbana orientable en 3D con diseño previo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - RealmDreamer: Generación de escenas 3D basadas en texto con pintura interna y difusión de profundidad
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04: OpenAI y Meta están a punto de lanzar modelos de IA capaces de razonar como humanos, según un informe
(Noticias), - 10/04 - MetaCheckGPT: un detector de alucinaciones multitarea que utiliza incertidumbre LLM y metamodelos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Meta confirma que su LLM de código abierto Llama 3 llegará el próximo mes
(Noticias), - 10/04 - No deje ningún contexto atrás: Transformadores eficientes de contexto infinito con atención infinita
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - XAI incremental: comprensión memorable de la IA con explicaciones incrementales
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - DreamScene360: Generación de escenas de texto a 3D sin restricciones con salpicaduras panorámicas gaussianas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – ¿El Mapo Tofu Contiene Café? Investigación de LLM sobre conocimientos culturales relacionados con la alimentación
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - BRAVE: Ampliando la codificación visual de modelos visión-lenguaje
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04: La startup de IA Mistral lanza un modelo de IA de 281 GB para rivalizar con OpenAI, Meta y Google
(Noticias), - 04/10 - Comunicación semántica generativa impulsada por agentes para vigilancia remota
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Adaptación del Decodificador LLaMA al Transformador de Visión
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Una encuesta sobre la integración de la IA generativa para el pensamiento crítico en las redes móviles
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - ¡Échale un vistazo! Repensar cómo evaluar el jailbreak del modelo de lenguaje
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - RULER: ¿Cuál es el tamaño de contexto real de sus modelos de lenguaje de contexto largo?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - Revisión de la densificación en el splatting gaussiano
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - Reconstrucción de objetos portátiles en 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - RAR-b: Razonamiento como punto de referencia de recuperación
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - Ingeniería rápida para preservar la privacidad: una encuesta
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - Sobre la evaluación de la eficiencia del código fuente generado por LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 09/04 - Informe técnico de OmniFusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - MuPT: Un transformador preentrenado de música generativa simbólica
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - MiniCPM: Revelando el potencial de los modelos de lenguajes pequeños con estrategias de capacitación escalables
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - Magic-Boost: Impulsa la generación 3D con difusión condicionada Mutli-View
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - LLM2Vec: Los modelos de lenguaje grandes son codificadores de texto secretamente poderosos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - InternLM-XComposer2-4KHD: Un modelo pionero de lenguaje de visión grande que maneja resoluciones desde 336 píxeles hasta 4K HD
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - Hash3D: Aceleración sin entrenamiento para generación 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - Google presenta proyectos de código abierto para IA generativa
(Noticias), - 09/04 - Los elefantes nunca olvidan: memorización y aprendizaje de datos tabulares en modelos de lenguaje grandes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04: Apple acaba de presentar el nuevo Ferret-UI LLM: esta IA puede leer la pantalla de su iPhone
(Noticias), - 09/04 - AEGIS: Moderación de seguridad de contenido de IA adaptable en línea con un conjunto de expertos en LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - YaART: Otra tecnología más de renderizado de ARTE
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - WILBUR: Aprendizaje adaptativo en contexto para agentes web robustos y precisos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - UniFL: Mejore la difusión estable mediante el aprendizaje por retroalimentación unificada
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - Ícaro desenfrenado: un estudio de los peligros potenciales de las entradas de imágenes en la seguridad del modelo de lenguaje grande multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - Tabla de clasificación de alucinaciones: un esfuerzo abierto para medir las alucinaciones en modelos de lenguaje grandes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - El problema de selección de hechos en la reparación de programas basados en LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/08 - Swapanything: habilitando el intercambio de objetos arbitrarios en edición visual personalizada
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Sambalingo: enseñando modelos de idiomas grandes nuevos idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Optimización de preferencias negativas: desde un colapso catastrófico hasta un desaprendizaje efectivo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Naver debuta HyperClova X LLM multilingüe Se utilizará para construir IA soberana para Asia
(Noticias), - 04/08 - MOMA: adaptador multimodal LLM para generación de imágenes personalizada rápida
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 08/08 - MedEXPQA: evaluación comparativa multilingüe de modelos de idiomas grandes para respuesta a preguntas médicas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08- MA-LMM: Modelo multimodal grande augalizado para la memoria para la comprensión de video a largo plazo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Layoutllm: ajuste de instrucciones de diseño con modelos de lenguaje grandes para la comprensión de documentos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 - Ferret -UI: comprensión móvil de la interfaz de usuario con LLM multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Evaluación de capacidades de razonamiento intervencionista de modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Eagle and Finch: RWKV con estados con valor de matriz y recurrencia dinámica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 - CodeCLM: Alineando modelos de lenguaje con datos sintéticos a medida
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - AutoCoderover: Mejora del programa autónomo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 - TIMEGPT en pronóstico de carga: una gran perspectiva del modelo de series temporales
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/07 - OpenAi transcribió más de un millón de horas de videos de YouTube para entrenar GPT -4
(Noticias), - 04/07 - Magictime: modelos de generación de videos de tiempo de tiempo como simuladores metamórficos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 - Byteedit: Boost, cumplir y acelerar la edición de imágenes generativas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - La mayoría de los médicos mejora la adecuación de la confianza en la patología de la IA
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/06- Diffusion-RWKV: Escala de arquitecturas similares a RWKV para modelos de difusión
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/06- Datenerf: edición basada en texto de Nerfs basada en la profundidad de NERFS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Beyondscene: Generación de escenas centradas en el humano de mayor resolución con difusión previa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - Alineando modelos de difusión optimizando la utilidad humana
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - El caso para desarrollar un modelo de base para tareas de planificación desde cero
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Aumento de las vulnerabilidades de LLM desde el ajuste y la cuantificación
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - SpatialTracker: Seguimiento de cualquier píxeles 2D en el espacio 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Entrenamiento de habilidades sociales con modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Sigma: Network Siamese Mamba para segmentación semántica multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/05 - Splatting gaussiano robusto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Physavatar: aprendiendo la física de los avatares 3D vestidos de las observaciones visuales
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05- Koala: Video Long Long acondicionado de marco clave
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Pista: una evaluación de comprensión de lenguaje clínico para LLMS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - chino Tiny LLM: previamente un modelo de idioma grande centrado en el chino
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Asistir a los humanos en comparaciones complejas: comparación de información automatizada a escala
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - IA incorporada con dos brazos: aprendizaje de disparo cero, seguridad y modularidad
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/04 - Evolución del modelo de idioma: una perspectiva de aprendizaje iterada
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- La visualización de pensamiento provoca un razonamiento espacial en modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) (twitter), - 04/04 - No hay "disparo cero" sin datos exponenciales: la frecuencia del concepto previa a la altura determina el rendimiento del modelo multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Evaluación de LLM en la detección de errores en las respuestas de LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Evaluación de modelos de lenguaje generativo en la extracción de información como corrección de preguntas subjetivas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Optimización directa de NASH: modelos de lenguaje de enseñanza a autoinforme con preferencias generales
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- CBR-RAG: razonamiento basado en casos para la generación aumentada de recuperación en LLMS para la respuesta de preguntas legales
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Capacidades de modelos de idiomas grandes en ingeniería de control: un estudio de referencia sobre GPT -4, Claude 3 Opus y Gemini 1.0 Ultra
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - CantTalkAboutThis: Alineando modelos de idiomas para permanecer en el tema en los diálogos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Autowebglm: Bootstrap y reforzan un agente de navegación web basado en modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Entrenamiento LLMS sobre texto neuralmente comprimido
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Reft: representación Finetuning para modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04- Red Teaming GPT-4V: ¿GPT-4V son seguros contra los ataques de jailbreak de uni/multimodal?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Rall-E: modelado de lenguaje de códec robusto con solicitante de la cadena de pensamiento para la síntesis de texto a voz
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - PointInfinity: modelos de difusión de puntos invariantes de resolución
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Minigpt4-Video: avance de LLM multimodales para la comprensión de video con tokens visuales-textuales intercalados
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- COMAT: alineando el modelo de difusión de texto a imagen con coincidencia de concepto de imagen a texto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Codeeditorbench: Evaluación de la capacidad de edición de código de modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Autowebglm: Bootstrap y reforzan un agente de navegación web basado en modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Modelado visual autorregresivo: generación de imágenes escalable a través de la predicción a próxima escala
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- Sobre la escalabilidad de la generación de texto a imagen basada en difusión
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Many -shot Jailbreaking
() - 03/04- LVLM-Intrepret: una herramienta de interpretabilidad para modelos de lenguaje de visión grande
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - Modelos de lenguaje como compiladores: simular la ejecución de los pseudocodos mejora el razonamiento algorítmico en los modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/04- Instantstyle: almuerzo gratis hacia la preservación del estilo en la generación de texto a imagen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/04 - Freditor: Fidelidad alta y edición de NERF transferible por descomposición de frecuencia
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- La atención cruzada hace que la inferencia sea engorrosa en los modelos de difusión de texto a imagen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/04- Chatglm-Math: Mejora de la resolución de problemas de matemáticas en modelos de idiomas grandes con una tubería autocrítica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 02/04 - Reino Unido y Estados Unidos Anuncia la Asociación sobre Ciencias de la Seguridad de AI
(Noticias), - 04/02 - Modelos de idiomas grandes como generadores de dominio de planificación
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/02 - poro 34b y la bendición de la multilingüe
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Octopus V2: modelo de lenguaje en el dispositivo para super agente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- Mezcla de Dephs: Asignación dinámica de cómputo en modelos de lenguaje basados en transformadores
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- LLMS de larga duración lucha con un largo aprendizaje en contexto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - LLM -ABR: Diseño de algoritmos adaptativos de tasa de bits a través de modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Los modelos de lenguaje grande podrían cambiar el futuro de la atención médica del comportamiento: una propuesta para el desarrollo y la evaluación responsables
() - 04/02 - Informe técnico de HyperClova X
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- CamerACTRL: habilitando el control de la cámara para la generación de texto a video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - Avanzando a los generalistas de razonamiento de LLM con árboles preferenciales
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Stream of Search (SOS): Aprender a buscar en el lenguaje
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - LLM como mente maestra: una encuesta de razonamiento estratégico con modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 01/04 - El aumento y el aumento de los modelos de lenguaje grande de IA (LLMS)
(Blog), - 01/04 - Siguiente subtitulación de video denso
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Medición de similitud de estilo en modelos de difusión
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01- Hacer lo correcto: Mejora de la consistencia espacial en los modelos de texto a imagen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Para las compañías de IA que logra de datos, Internet es demasiado pequeño
(Noticias), - 04/01- FlexIdreamer: una sola imagen a 3D Generación con Flexicubes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Evalverse: biblioteca unificada y accesible para la evaluación del modelo de idioma grande
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Optimización de preferencia directa de videos grandes modelos multimodales de la recompensa del modelo de lenguaje
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - DBRX, Pretratenamiento continuo, Banco de recompensa, inferencia más rápida y más
(Blog), - 04/04- Cosmicman: un modelo de base de texto a imagen para humanos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 01/04 - Red neuronal consciente de la condición para la generación de imágenes controladas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Más grande no siempre es mejor: propiedades de escala de los modelos de difusión latente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - ¿Son los modelos de idiomas grandes químicos sobrehumanos?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 31/31 - Wavllm: Hacia un modelo de lenguaje grande y robusto y adaptativo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/31 - ¿Cansado de complementos? Los modelos de idiomas grandes pueden ser recomendadores de extremo a extremo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 30/3/30 - Encuesta sobre gran modelo de aprendizaje de refuerzo mejorado con modelos de idiomas: concepto, taxonomía y métodos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 30/03 - ST -LLM: los modelos de idiomas grandes son estudiantes temporales efectivos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 30/03- Entrenamiento de ruido consciente de los modelos de lenguaje consciente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 30/03 - Magritte: Realización 3D manipuladora y generativa de la imagen, topview y texto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 30/03- Aurora-M: El primer modelo de lenguaje multilingüe de código abierto teñido de acuerdo con la Orden Ejecutiva de los Estados Unidos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03 - Detección de problemas insoluble: Evaluación de modelos de confianza de la confianza de la visión
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/29- Transformer-Lite: implementación de alta eficiencia de modelos de idiomas grandes en GPU de teléfonos móviles
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03- Snap-IT, TAP-IT, Splat-It: Splatting gaussiano 3D informado táctil para reconstruir superficies desafiantes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03 - Reino: resolución de referencia como modelado de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03 - NVIDIA H200 GPUS Crush Mlperf's LLM Inferencing Benchmark
(Noticias), - 29/03 - Mambamixer: modelos de espacio de estado selectivo eficientes con token dual y selección de canales
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/29 - Llava -Gemma: Acelerar modelos de cimientos multimodales con un modelo de lenguaje compacto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/29- Instantsplat: Spching gaussiano sin vergüenza sin vergüenza en 40 segundos en 40 segundos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03 - Gecko: insertos de texto versátiles destilados de modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03 - Dijiang: modelos de lenguaje grandes eficientes a través de la kernelización compacta
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 29/29- DeepMind se desarrolla Safe, una aplicación basada en IA que puede verificar los LLM
(Noticias), - 29/03 - CTRL -SIM: Agentes de conducción reactivos y controlables con aprendizaje de refuerzo fuera de línea
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03 - ¿Estamos de la manera correcta para evaluar grandes modelos en idioma de visión?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03 - SDPO: no use sus datos a la vez
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03 - MESH2NERF: Supervisión de malla directa para la representación y generación del campo de radiancia neuronal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03 - Memorización de párrafo localizando en modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03 - Jamba: un modelo de lenguaje híbrido transformador -mamba
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03 - Gaussiancube: estructuración de la estallido gaussiano utilizando el transporte óptimo para el modelado generativo 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03 - Claude 3 superar a GPT -4 en el duelo de los bots de AI. Aquí le mostramos cómo entrar en la acción
(Noticias), - 28/03 - anunciando a Grok -1.5
(Blog), (demo), - 27/03 - Un camino hacia la autonomía legal: un enfoque interoperable y explicable para extraer, transformar, cargar y calcular información legal utilizando modelos de idiomas grandes, sistemas expertos y redes bayesianas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03 - Vitar: Vision Transformer con cualquier resolución
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03- Hacia un modelo de idioma mundial-inglés para asistentes virtuales en el dispositivo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03 - TextCraftor: su codificador de texto puede ser controlador de calidad de imagen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03 - ObjectRrop: contrafactual de arranque para eliminación e inserción de objetos fotorrealistas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03- Mini-Gemini: minera el potencial de los modelos de lenguaje de visión multimodalidad
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 27/03 - Factualidad de forma larga en modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 27/03 - LITA: Asistente de localización temporal de lenguaje instruido
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 27/03 - Garment3DGen: estilización de prenda 3D y generación de texturas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03 - Gamba: se case con chispas gaussianas con mamba para una sola vista 3D Reconstrucción
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03- FlexEdit: edición de imágenes centrada en objetos flexible y controlable basada en la difusión
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03 - BIOMEDLM: un modelo de lenguaje de parámetros de 2.7B entrenado en texto biomédico
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/03- Magis: marco múltiple basado en LLM para la resolución de problemas de GitHub
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/03 - La ineficacia irrazonable de las capas más profundas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/03- TC4D: Generación de texto a 4D acondicionado para trayectoria
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/03- OCTree-GS: Hacia una representación constante en tiempo real con Gaussianos 3D estructurados con LOD
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 26/26- Presentación de DBRX: un nuevo LLM abierto de estado de arte
(Blog), - 26/03 - Informe técnico de Internlm2
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 26/26- Mejora de la consistencia de texto a imagen a través de la optimización automática de inmediato
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/26- Perceptrones múltiples de fusiones totalmente fusionadas en las GPU del centro de datos Intel
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 26/26 - Egolifter: segmentación 3D del mundo abierto para la percepción egocéntrica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/03 - Aniportraito: Síntesis de audio de animación de retratos fotorrealistas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 26/26 - 2D Splatting gaussiano para campos de radiancia geométricamente precisos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 15/03 - Hacia la evaluación automática para las capacidades clínicas de LLMS: métrica, datos y algoritmo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 25/03 - RepairAgent: un agente autónomo, basado en LLM para la reparación del programa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25- RL para modelos de consistencia: Generación de texto a imagen guiada de recompensa más rápida
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25- VP3D: desatar el pedido visual 2D para la generación de texto a 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 25/03- Viaje: aprendizaje residual temporal con ruido de imagen anterior para modelos de difusión de imagen a video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25- SDXS: modelos de difusión latente de un solo paso en tiempo real con condiciones de imagen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 25/03 - Sistema operativo de agente de LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 - Flashface: personalización de imágenes humanas con preservación de identidad de alta fidelidad
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 15/03- DreamPolisher: Hacia la generación de texto a 3D de alta calidad a través de la difusión geométrica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 25/03- Sé tú mismo: Atención limitada para la generación de texto a imagen de múltiples sujetos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 23/23 - Cuando la generación de código basada en LLM cumple con el proceso de desarrollo de software
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/22 - Temestation: Generación de activos 3D conscientes de temas de pocos ejemplos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/22 - SIMBA: arquitectura simplificada basada en mamba para visión y series de tiempo multivariadas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 22/22 - LLM2LLM: Boosting LLMS con una nueva mejora de datos iterativos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 22/22- Latte3d: Síntesis de texto a gran escala de texto a mejorado 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/22 - Internvideo2: Escalado de modelos de cimientos de video para la comprensión de video multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 22/22 - FIEGO: Evaluación y enseñanza de modelos de recuperación de información para seguir las instrucciones
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 22/22 - Dragapart: Aprender un movimiento a nivel parcial antes de los objetos articulados
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/22 - ¿Pueden los modelos de idiomas grandes explorar en contexto?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/22 - Allhands: Pregúntame cualquier cosa sobre comentarios literales a gran escala a través de modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 21/03 - Peergpt: sondeando los roles de los agentes pares con sede en LLM como moderadores y participantes del equipo en el aprendizaje colaborativo de los niños
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - STYLECINEGAN: Generación del cinemagraph del paisaje utilizando un Stylegan previamente capacitado
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/03 - StreamingT2V: Generación de videos largos consistentes, dinámicos y extensibles del texto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/03 - Renoise: inversión de imagen real a través de la noising iterativa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - Recurso para la recuperación: chatear con modelos de idiomas generativos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - Rakutenai -7b: extender modelos de idiomas grandes para japonés
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - MyVLM: personalización de VLMS para consultas específicas del usuario
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - Mathverse: ¿Su LLM multimodal realmente ve los diagramas en problemas de matemáticas visuales?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - GRM: modelo de reconstrucción gaussiano grande para reconstrucción y generación 3D eficientes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/21 - La Asamblea General adopta una resolución histórica sobre inteligencia artificial
(Noticias), - 21/03 - Gaussian glaseado: campos de radiancia complejos editables con representación en tiempo real
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/21 - Explorativo en el tiempo de tiempo y espacio
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/21- Modelos de difusión de video eficientes a través de la descomposición de lata de movimiento de contenido de contenido
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03- DreamReward: Generación de texto a 3D con preferencia humana
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - Cobra: extensor de mamba a un modelo de lenguaje grande multimodal para una inferencia eficiente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/03 - Campeón: animación de imagen humana controlable y consistente con guía paramétrica 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/21- Anyv2v: un marco plug-and-play para cualquier tarea de edición de video a video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Mapeo de paisajes de seguridad LLM: una propuesta integral de evaluación de riesgos de los interesados
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Zigma: modelo de difusión de zigzag mamba
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - VSTAR: Enfermería temporal generativa para una síntesis de video dinámico más larga
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Banco de recompensas: evaluación de modelos de recompensa para el modelado de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - Entrenamiento inverso para cuidar la maldición de la inversión
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20- Radsplat: Splatting gaussiano informado por el campo Radiance para una representación robusta en tiempo real con más de 900 FPS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Mora: habilitando la generación de videos generalistas a través de un marco de múltiples agentes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - LlamaFactory: ajuste fino eficiente unificado de más de 100 modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20- Idadapter: Aprendizaje de características mixtas para la personalización sin ajuste de modelos de texto a imagen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03 - Hyperllava: ajuste dinámico de expertos visuales y de lenguaje para modelos de lenguaje grande y multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - Evaluación de modelos fronterizos para capacidades peligrosas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Profundidad FM: Estimación de profundidad monocular rápida con coincidencia de flujo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Compress3D: un espacio latente comprimido para la generación 3D desde una sola imagen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20- Be-Your Extrapenter: Mastering Video superando a través de la adaptación específica de entrada
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 19/03 - ¿Cuándo no necesitamos modelos de visión más grandes?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 19/03- VID2ROBOT: aprendizaje de políticas de video de extremo a extremo con transformadores de atención cruzada
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Hacia un modelo de base de uso general para patología computacional
() - 03/19- TexDreamer: hacia la generación de textura humana 3D de alta fidelidad cero-disparo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Escena: Reconstruir escenas con un modelo de lenguaje estructurado autorregresivo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19- Mplug-Docowl 1.5: Aprendizaje de estructura unificada para comprensión de documentos sin OCR
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Magic Fixup: optimizar la edición de fotos viendo videos dinámicos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19- Llmlingua-2: Distilación de datos para compresión rápida de tareas eficientes y fieles.
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- GVGEN: Generación de texto a 3D con representación volumétrica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 19/03 - Gaussianflow: Splatting Gaussian Dynamics para la creación de contenido 4D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19- Fresco: correspondencia espacial-temporal para traducción de videos de disparo cero
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 19/03- Fouriscale: una perspectiva de frecuencia sobre la síntesis de imágenes de alta resolución sin entrenamiento
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Optimización evolutiva de recetas de fusión modelo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), ([: octocat:] (https : //github.com/ sakanaai/evolutionmary-model-merge)! [Github Repo Stars] (https://img.shields.io/github/stars/ sakanai/evolution-model-merge? style = social))) - 03/19 - Comboverse: creación de activos 3D compositivos utilizando guía de difusión espacialmente consciente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Razonamiento basado en gráficos: Capacidades de transferencia de LLM a VLMS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - MM1 de Apple: un modelo de lenguaje grande multimodal capaz de interpretar imágenes y datos de texto
(Noticias), - 19/03- Animatediff-Lightning: destilación de difusión de modelos cruzados
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Agente -flan: Diseño de datos y métodos de ajuste de agente efectivo para modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Un modelo de base visual para la patología computacional
(), (✳️) - 03/19 - Agentes de IA característicos a través de modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), (! [Github Repo Stars] ( https://img.shields.io/github/stars/nuaa-nlp/character100? style = social)) - 18/03 - ¿Hasta dónde estamos en la toma de decisiones de LLM? Evaluación de la capacidad de juego de LLMS en entornos de múltiples agentes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 18/03 - VideoAgent: un agente multimodal acuático para la comprensión de video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03 - Vfusion3d: Modelos generativos 3D escalables de aprendizaje de modelos de difusión de video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03 - TNT -LLM: minería de texto a escala con modelos de idiomas grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03 - SV3D: síntesis novedosa de visión múltiple y generación 3D a partir de una sola imagen usando difusión de video latente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03 - RouterBench: un punto de referencia para el sistema de enrutamiento multi -LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), (ss) - 18/03- Meta-Prompting para automatizar el reconocimiento visual de disparo cero con LLMS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 8/18 - LN3Diff: Difusión de campos neurales latentes escalables para una rápida generación 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 8/18- Llava-uhd: un LMM que percibe cualquier relación de aspecto e imágenes de alta resolución
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 18/03 - Larimar: modelos de idiomas grandes con control de memoria episódica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03- ID infinito: personalización conservada de identidad a través del paradigma de desacoplamiento de ID-Semantics
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03 - GPT -4 AS Evaluador: Evaluación de modelos de idiomas grandes sobre la gestión de plagas en la agricultura
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog), - 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Meet 'Liberated Qwen', an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (gorjeo,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️) - 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


