LaTeX OCR
1.0.0
El objetivo de este proyecto es crear un sistema basado en el aprendizaje que tome una imagen de una fórmula matemática y devuelva el código LaTeX correspondiente.
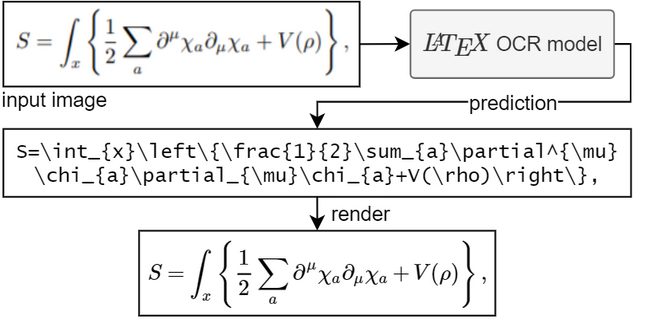
Para ejecutar el modelo necesitas Python 3.7+
Si no tiene PyTorch instalado. Sigue sus instrucciones aquí.
Instale el paquete pix2tex :
pip install "pix2tex[gui]"
Los puntos de control del modelo se descargarán automáticamente.
Hay tres formas de obtener una predicción a partir de una imagen.
Puede utilizar la herramienta de línea de comando llamando a pix2tex . Aquí puede analizar imágenes ya existentes del disco y las imágenes en su portapapeles.
Gracias a @katie-lim, puedes utilizar una interfaz de usuario agradable como una forma rápida de obtener la predicción del modelo. Simplemente llame a la GUI con latexocr . Desde aquí puede tomar una captura de pantalla y el código de látex predicho se procesa usando MathJax y se copia en su portapapeles.
En Linux, es posible utilizar la GUI con gnome-screenshot (que viene con soporte para múltiples monitores) si gnome-screenshot se instaló de antemano. Para Wayland, se utilizarán grim y slurp cuando ambos estén disponibles. Tenga en cuenta que gnome-screenshot no es compatible con los compositores Wayland basados en wlroots. Dado que se preferirá gnome-screenshot cuando esté disponible, es posible que deba configurar la variable de entorno SCREENSHOT_TOOL en grim en este caso (otros valores disponibles son gnome-screenshot y pil ).
Si el modelo no está seguro de lo que hay en la imagen, es posible que genere una predicción diferente cada vez que haga clic en "Reintentar". Con el parámetro temperature puedes controlar este comportamiento (una temperatura baja producirá el mismo resultado).
Puedes usar una API. Esto tiene dependencias adicionales. Instalar mediante pip install -U "pix2tex[api]" y ejecutar
Python -m pix2tex.api.run
para iniciar una demostración de Streamlit que se conecta a la API en el puerto 8502. También hay una imagen de Docker disponible para la API: https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
Para ejecutar también la demostración optimizada
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
y navegue hasta http://localhost:8501/
Usar desde dentro de Python
desde PIL importar imagen desde pix2tex.cli importar LatexOCRimg = Imagen.open('ruta/a/imagen.png')modelo = LatexOCR()imprimir(modelo(img))El modelo funciona mejor con imágenes de menor resolución. Por eso agregué un paso de preprocesamiento donde otra red neuronal predice la resolución óptima de la imagen de entrada. Este modelo cambiará automáticamente el tamaño de la imagen personalizada para que se parezca mejor a los datos de entrenamiento y así aumentar el rendimiento de las imágenes encontradas en la naturaleza. Aún así, no es perfecto y es posible que no pueda manejar imágenes grandes de manera óptima, así que no acerques completamente antes de tomar una fotografía.
Siempre verifique cuidadosamente el resultado. Puedes intentar rehacer la predicción con otra resolución si la respuesta fue incorrecta.
¿Quieres utilizar el paquete?
Estoy intentando compilar una documentación ahora mismo.
Visite aquí: https://pix2tex.readthedocs.io/
Instale un par de dependencias pip install "pix2tex[train]" .
Primero necesitamos combinar las imágenes con sus etiquetas de verdad fundamentales. Escribí una clase de conjunto de datos (que necesita mejoras adicionales) que guarda las rutas relativas a las imágenes con el código LaTeX con el que fueron renderizadas. Para generar el archivo pickle del conjunto de datos, ejecute
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
Para usar su propio tokenizador, páselo a través de --tokenizer (ver más abajo).
También puedes encontrar mis datos de entrenamiento generados en Google Drive (formulae.zip - imágenes, math.txt - etiquetas). Repita el paso para los datos de validación y prueba. Todos utilizan el mismo archivo de texto de etiqueta.
Edite la entrada de data (y valdata ) en el archivo de configuración en el archivo .pkl recién generado. Cambie otros hiperparámetros si lo desea. Consulte pix2tex/model/settings/config.yaml para obtener una plantilla.
Ahora para el entrenamiento real
python -m pix2tex.train --config path_to_config_file
Si desea utilizar sus propios datos, es posible que le interese crear su propio tokenizador con
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
No olvide actualizar la ruta al tokenizador en el archivo de configuración y configurar num_tokens según el tamaño de su vocabulario.
El modelo consta de un codificador ViT [1] con una red troncal ResNet y un decodificador Transformer [2].
| Puntuación BLEU | distancia de edición normalizada | precisión del token |
|---|---|---|
| 0,88 | 0,10 | 0,60 |
Necesitamos datos emparejados para que la red aprenda. Afortunadamente, hay mucho código LaTeX en Internet, por ejemplo, wikipedia, arXiv. También utilizamos las fórmulas del conjunto de datos im2latex-100k [3]. Todo esto se puede encontrar aquí.
Para representar las matemáticas en muchas fuentes diferentes, usamos XeLaTeX, generamos un PDF y finalmente lo convertimos a PNG. Para el último paso necesitamos utilizar algunas herramientas de terceros:
XeLaTeX
ImageMagick con Ghostscript. (para convertir pdf a png)
Node.js para ejecutar KaTeX (para normalizar el código Latex)
Python 3.7+ y dependencias (especificadas en setup.py )
Matemáticas modernas latinas, GFSNeohellenicMath.otf, Asana Math, XITS Math, Cambria Math
agregar más métricas de evaluación
crear una GUI
agregar búsqueda de haz
Admite fórmulas escritas a mano (un poco hecho, consulte el cuaderno de capacitación de colab)
reducir el tamaño del modelo (destilación)
encontrar hiperparámetros óptimos
modificar la estructura del modelo
arreglar el raspado de datos y raspar más datos
rastrear el modelo (#2)
Se aceptan contribuciones de cualquier tipo.
Código tomado y modificado de lucidrains, rwightman, im2markup, arxiv_leaks, pkra: Mathjax, harupy: herramienta de recorte
[1] Una imagen vale 16x16 palabras
[2] Atención es todo lo que necesitas
[3] Generación de imagen a marcado con atención de grueso a fino


