segment anything
1.0.0
Consulte nuestra nueva versión sobre Segment Anything Model 2 (SAM 2) .
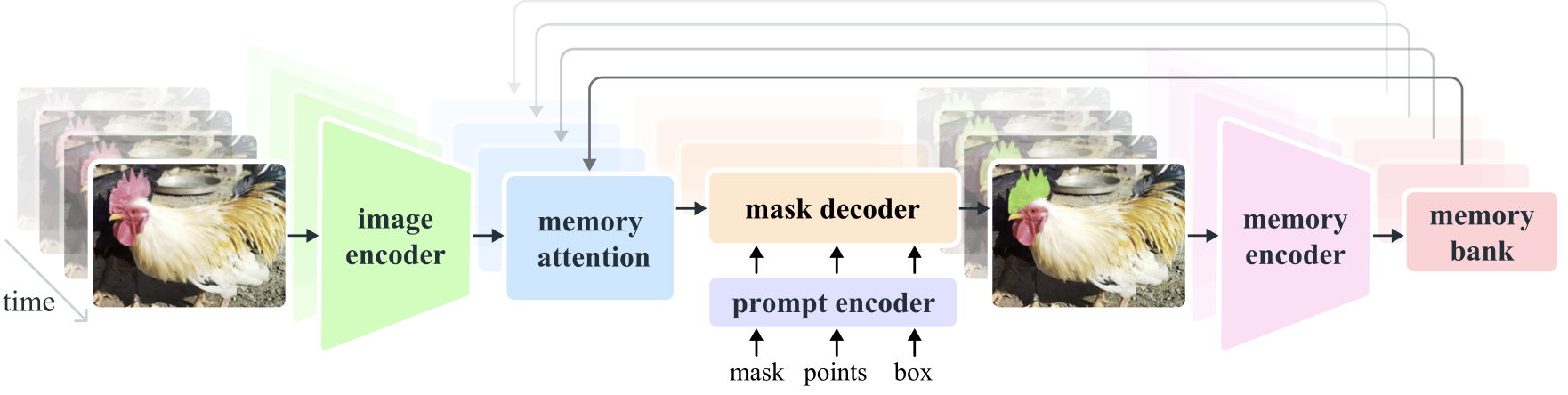
Segment Anything Model 2 (SAM 2) es un modelo básico para resolver la segmentación visual rápida en imágenes y videos. Extendemos SAM al video considerando las imágenes como un video con un solo cuadro. El diseño del modelo es una arquitectura de transformador simple con memoria de transmisión para procesamiento de video en tiempo real. Creamos un motor de datos de modelo en bucle, que mejora el modelo y los datos a través de la interacción del usuario, para recopilar nuestro conjunto de datos SA-V , el conjunto de datos de segmentación de video más grande hasta la fecha. SAM 2 entrenado con nuestros datos proporciona un rendimiento sólido en una amplia gama de tareas y dominios visuales.
Investigación de Meta AI, FAIR
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
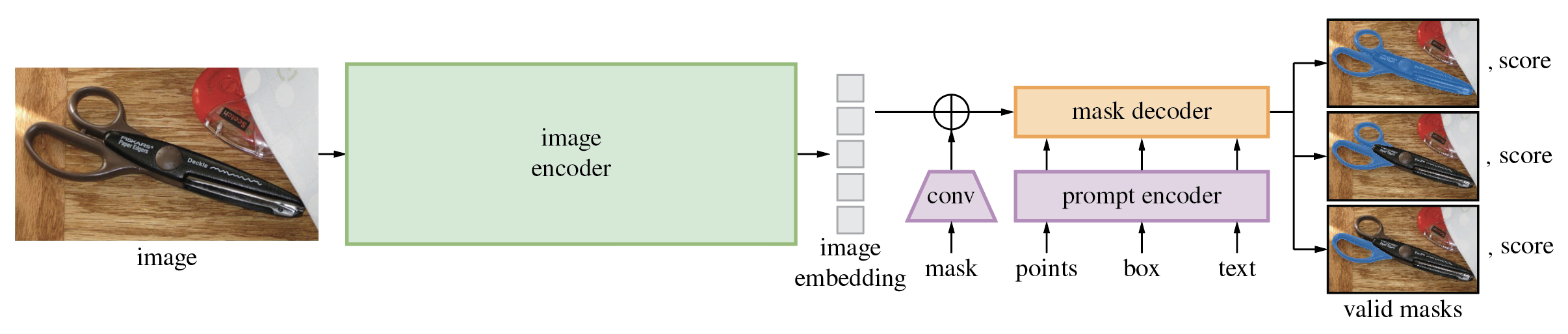
El Segment Anything Model (SAM) produce máscaras de objetos de alta calidad a partir de mensajes de entrada como puntos o cuadros, y se puede utilizar para generar máscaras para todos los objetos de una imagen. Ha sido entrenado en un conjunto de datos de 11 millones de imágenes y 1,1 mil millones de máscaras, y tiene un sólido rendimiento de disparo cero en una variedad de tareas de segmentación.


El código requiere python>=3.8 , así como pytorch>=1.7 y torchvision>=0.8 . Siga las instrucciones aquí para instalar las dependencias de PyTorch y TorchVision. Se recomienda encarecidamente instalar PyTorch y TorchVision con soporte CUDA.
Instalar Segmentar cualquier cosa:
pip install git+https://github.com/facebookresearch/segment-anything.git
o clonar el repositorio localmente e instalarlo con
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
Las siguientes dependencias opcionales son necesarias para el posprocesamiento de máscaras, guardar máscaras en formato COCO, los cuadernos de ejemplo y exportar el modelo en formato ONNX. También se requiere jupyter para ejecutar los cuadernos de ejemplo.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
Primero descargue un punto de control modelo. Luego, el modelo se puede utilizar en unas pocas líneas para obtener máscaras a partir de un mensaje determinado:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
o generar máscaras para una imagen completa:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
Además, se pueden generar máscaras para imágenes desde la línea de comando:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
Consulte los cuadernos de ejemplos sobre el uso de SAM con indicaciones y la generación automática de máscaras para obtener más detalles.


El decodificador de máscara liviano de SAM se puede exportar al formato ONNX para que pueda ejecutarse en cualquier entorno que admita el tiempo de ejecución de ONNX, como en el navegador, como se muestra en la demostración. Exportar el modelo con
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
Consulte el cuaderno de ejemplo para obtener detalles sobre cómo combinar el preprocesamiento de imágenes a través de la columna vertebral de SAM con la predicción de máscara utilizando el modelo ONNX. Se recomienda utilizar la última versión estable de PyTorch para la exportación ONNX.
La carpeta demo/ tiene una aplicación React simple de una página que muestra cómo ejecutar la predicción de máscara con el modelo ONNX exportado en un navegador web con subprocesos múltiples. Consulte demo/README.md para obtener más detalles.
Hay tres versiones del modelo disponibles con diferentes tamaños de columna vertebral. Se pueden crear instancias de estos modelos ejecutando
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
Haga clic en los enlaces a continuación para descargar el punto de control para el tipo de modelo correspondiente.
default o vit_h : modelo ViT-H SAM.vit_l : modelo ViT-L SAM.vit_b : modelo ViT-B SAM. Consulte aquí para obtener una descripción general del conjunto de datos. El conjunto de datos se puede descargar aquí. Al descargar los conjuntos de datos, usted acepta haber leído y aceptado los términos de la Licencia de investigación de conjuntos de datos SA-1B.
Guardamos máscaras por imagen como un archivo json. Se puede cargar como un diccionario en Python en el siguiente formato.
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}Los identificadores de imágenes se pueden encontrar en sa_images_ids.txt, que también se puede descargar utilizando el enlace anterior.
Para decodificar una máscara en formato COCO RLE en binario:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
Consulte aquí para obtener más instrucciones para manipular máscaras almacenadas en formato RLE.
El modelo tiene la licencia Apache 2.0.
Ver contribución y código de conducta.
El proyecto Segment Anything fue posible gracias a la ayuda de muchos contribuyentes (en orden alfabético):
Aaron Adcock, Vaibhav Aggarwal, Morteza Behrooz, Cheng-Yang Fu, Ashley Gabriel, Ahuva Goldstand, Allen Goodman, Sumanth Gurram, Jiabo Hu, Somya Jain, Devansh Kukreja, Robert Kuo, Joshua Lane, Yanghao Li, Lilian Luong, Jitendra Malik, Mallika Malhotra, William Ngan, Omkar Parkhi, Nikhil Raina, Dirk Rowe, Neil Señor, Vanessa Stark, Bala Varadarajan, Bram Wasti, Zachary Winstrom
Si utiliza SAM o SA-1B en su investigación, utilice la siguiente entrada BibTeX.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


