obfuscated gradients
v1.0.0
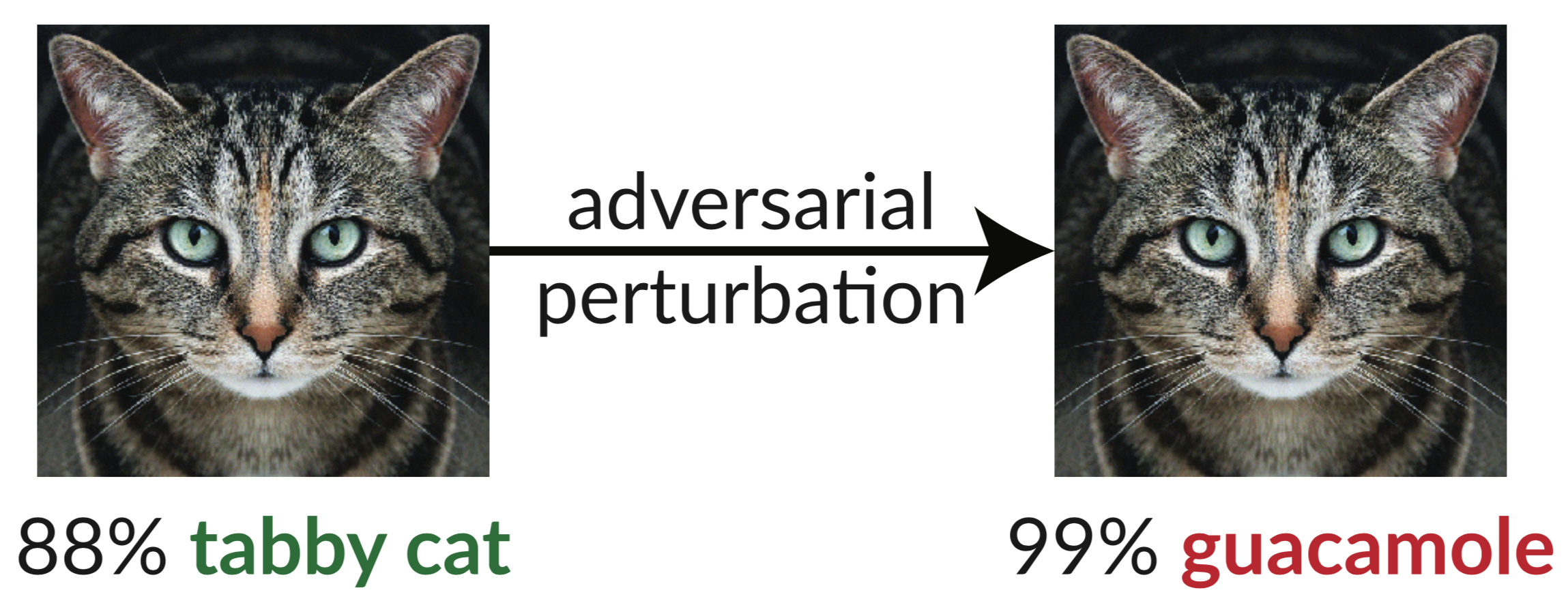
Arriba hay un ejemplo contradictorio: la imagen ligeramente perturbada del gato engaña a un clasificador de InceptionV3 para que lo clasifique como "guacamole". Estas "imágenes engañosas" son fáciles de sintetizar mediante el descenso de gradientes (Szegedy et al. 2013).
En nuestro artículo reciente, evaluamos la solidez de nueve artículos aceptados en ICLR 2018 como defensas seguras de caja blanca no certificadas contra ejemplos contradictorios. Encontramos que siete de las nueve defensas proporcionan un aumento limitado en robustez y pueden romperse mediante técnicas de ataque mejoradas que desarrollemos.
A continuación se muestra la Tabla 1 de nuestro artículo, donde mostramos la solidez de cada defensa aceptada frente a los ejemplos contradictorios que podemos construir:
| Defensa | Conjunto de datos | Distancia | Exactitud |
|---|---|---|---|
| Buckman et al. (2018) | CIFAR | 0,031 (linf) | 0%* |
| Ma et al. (2018) | CIFAR | 0,031 (linf) | 5% |
| Guo et al. (2018) | ImagenNet | 0,05 (l2) | 0%* |
| Dhillon y cols. (2018) | CIFAR | 0,031 (linf) | 0% |
| Xie et al. (2018) | ImagenNet | 0,031 (linf) | 0%* |
| Canción y col. (2018) | CIFAR | 0,031 (linf) | 9%* |
| Samangouei et al. (2018) | MNIST | 0,005 (l2) | 55%** |
| Madry et al. (2018) | CIFAR | 0,031 (linf) | 47% |
| Na et al. (2018) | CIFAR | 0,015 (linf) | 15% |
(Las defensas marcadas con * también proponen combinar entrenamiento adversario; aquí informamos solo la defensa. Consulte nuestro artículo, Sección 5 para obtener los números completos. El principio fundamental detrás de la defensa marcada con ** tiene 0% de precisión; en la práctica, las imperfecciones de la defensa causan teóricamente ataque óptimo para fallar, consulte la Sección 5.4.2 para obtener más detalles).
La única defensa que observamos que aumenta significativamente la solidez ante ejemplos adversarios dentro del modelo de amenaza propuesto es "Hacia modelos de aprendizaje profundo resistentes a ataques adversarios" (Madry et al. 2018), y no pudimos derrotar esta defensa sin salirnos del modelo de amenaza. . Incluso entonces, se ha demostrado que esta técnica es difícil de escalar a la escala ImageNet (Kurakin et al. 2016). El resto de los artículos (además del artículo de Na et al., que proporciona solidez limitada) se basan, ya sea inadvertida o intencionalmente, en lo que llamamos gradientes ofuscados . Los ataques estándar aplican un descenso de gradiente para maximizar la pérdida de la red en una imagen determinada para generar un ejemplo adversario en una red neuronal. Estos métodos de optimización requieren una señal de gradiente útil para tener éxito. Cuando una defensa ofusca los gradientes, rompe esta señal de gradiente y hace que fallen los métodos basados en la optimización.
Identificamos tres formas en que las defensas causan gradientes ofuscados y construimos ataques para evitar cada uno de estos casos. Nuestros ataques son generalmente aplicables a cualquier defensa que incluya, ya sea intencionalmente o no, una operación no diferenciable o que impida de otro modo que la señal de gradiente fluya a través de la red. Esperamos que el trabajo futuro pueda utilizar nuestros enfoques para realizar una evaluación de seguridad más exhaustiva.
Abstracto:
Identificamos los gradientes ofuscados, una especie de enmascaramiento de gradientes, como un fenómeno que conduce a una falsa sensación de seguridad en las defensas contra ejemplos adversarios. Si bien las defensas que causan gradientes ofuscados parecen derrotar los ataques iterativos basados en optimización, encontramos que las defensas que se basan en este efecto pueden eludirse. Describimos comportamientos característicos de las defensas que exhiben el efecto, y para cada uno de los tres tipos de gradientes ofuscados que descubrimos, desarrollamos técnicas de ataque para superarlo. En un estudio de caso, que examina defensas seguras de caja blanca no certificadas en ICLR 2018, encontramos que los gradientes ofuscados son una ocurrencia común, con 7 de 9 defensas que dependen de gradientes ofuscados. Nuestros nuevos ataques eluden con éxito 6 completamente y 1 parcialmente, en el modelo de amenaza original que considera cada artículo.
Para más detalles, lea nuestro artículo.
Este repositorio contiene nuestras instancias de las técnicas de ataque generales descritas en nuestro artículo, rompiendo 7 de las defensas de ICLR 2018. Algunas de las defensas no publicaron el código fuente (en el momento en que hicimos este trabajo), por lo que tuvimos que volver a implementarlas.
@inproceedings{gradientes-ofuscados, autor = {Anish Athalye y Nicholas Carlini y David Wagner}, título = {Gradientes ofuscados dan una falsa sensación de seguridad: eludiendo las defensas ante ejemplos contradictorios}, booktitle = {Actas de la 35ª Conferencia Internacional sobre Máquinas Aprendizaje, {ICML} 2018}, año = {2018}, mes = julio, url = {https://arxiv.org/abs/1802.00420},
} 

