AdaBoost_Seg
1.0.0
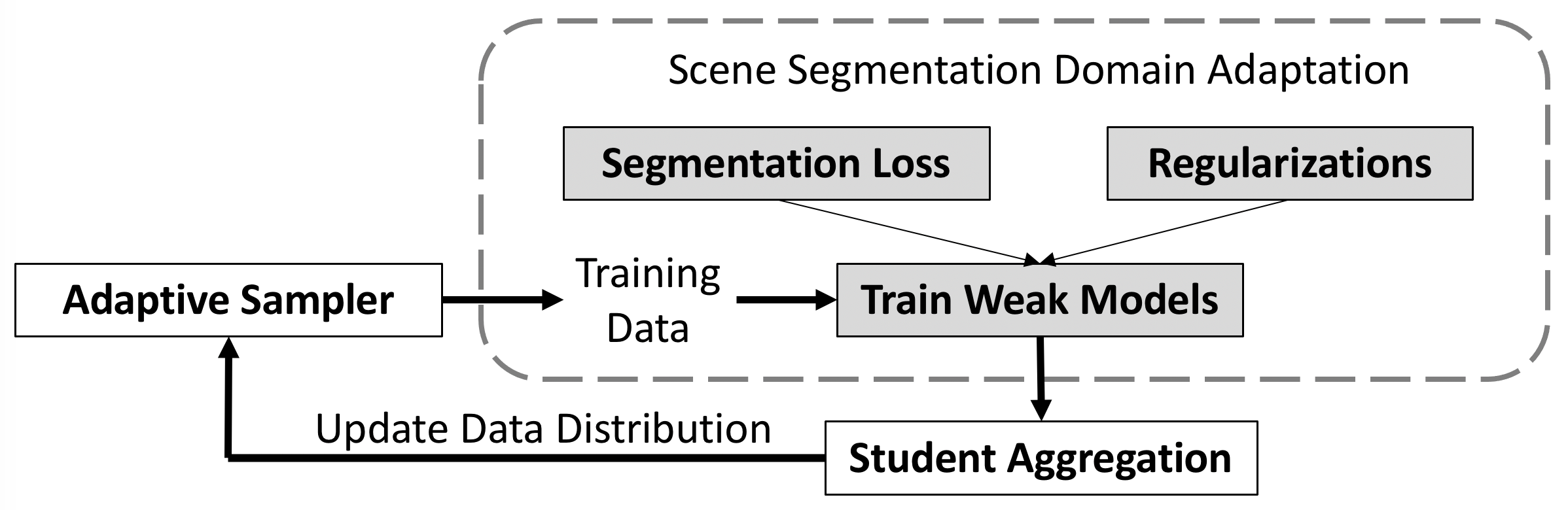 En este repositorio, proporcionamos el código del artículo Impulso adaptativo para la adaptación del dominio: hacia predicciones sólidas en la segmentación de escenas.
En este repositorio, proporcionamos el código del artículo Impulso adaptativo para la adaptación del dominio: hacia predicciones sólidas en la segmentación de escenas.
[Papel] [中文解读]
El enlace original de DeepLab de ucmerced falló. Utilice el siguiente enlace.
[Google Drive] https://drive.google.com/file/d/1BMTTMCNkV98pjZh_rU0Pp47zeVqF3MEc/view?usp=share_link
[Una unidad] https://1drv.ms/u/s!Avx-MJllNj5b3SqR7yurCxTgIUOK?e=A1dq3m
o usar
pip install gdown
pip install --upgrade gdown
gdown 1BMTTMCNkV98pjZh_rU0Pp47zeVqF3MEc
Al adoptar este método en otros campos, sugerimos ajustar el peso del muestreo con la temperatura para adaptarlo a su tarea y conjunto de datos. En este documento, no lo cambiamos y lo mantenemos como 1.
En nuestro experimento reciente, podemos lograr un rendimiento del 49,72% (MRNet+Ours) mejor que el número informado en el documento. Creemos que cuando el modelo agregado converge, el muestreador adboost se actualiza lentamente, lo que también compromete el rendimiento. Si damos más peso a las instantáneas recientes para actualizar la muestra, funciona mejor.
python train_ms.py --snapshot-dir ./snapshots/ReRUN_Adaboost_SWA_SE_GN_batchsize2_1024x512_pp_ms_me0_classbalance7_kl0.1_lr2_drop0.1_seg0.5_swa0_recent --drop 0.1 --warm-up 5000 --batch-size 2 --learning-rate 2e-4 --crop-size 1024,512 --lambda-seg 0.5 --lambda-adv-target1 0.0002 --lambda-adv-target2 0.001 --lambda-me-target 0 --lambda-kl-target 0.1 --norm-style gn --class-balance --only-hard-label 80 --max-value 7 --gpu-ids 0 --often-balance --use-se --swa --swa_start 0 --adaboost --recentDescarga [GTA5] y [Cityscapes] para ejecutar el código básico. Alternativamente, puede descargar dos conjuntos de datos adicionales de [SYNTHIA] y [OxfordRobotCar].
Descargue el conjunto de datos de GTA5
Descargue el conjunto de datos SYNTHIA SYNTHIA-RAND-CITYSCAPES (CVPR16)
Descargar el conjunto de datos de paisajes urbanos
Descargue el conjunto de datos de Oxford RobotCar
La carpeta de datos se estructura de la siguiente manera:
├── data/
│ ├── Cityscapes/
| | ├── data/
| | ├── gtFine/
| | ├── leftImg8bit/
│ ├── GTA5/
| | ├── images/
| | ├── labels/
| | ├── ...
│ ├── synthia/
| | ├── RGB/
| | ├── GT/
| | ├── Depth/
| | ├── ...
│ └── Oxford_Robot_ICCV19
| | ├── train/
| | ├── ...
Etapa I: (alrededor del 49,0%)
python train_ms.py --snapshot-dir ./snapshots/ReRUN_Adaboost_SWA_SE_GN_batchsize2_1024x512_pp_ms_me0_classbalance7_kl0.1_lr2_drop0.1_seg0.5_swa0 --drop 0.1 --warm-up 5000 --batch-size 2 --learning-rate 2e-4 --crop-size 1024,512 --lambda-seg 0.5 --lambda-adv-target1 0.0002 --lambda-adv-target2 0.001 --lambda-me-target 0 --lambda-kl-target 0.1 --norm-style gn --class-balance --only-hard-label 80 --max-value 7 --gpu-ids 0 --often-balance --use-se --swa --swa_start 0 --adaboostGenerar pseudoetiqueta:
python generate_plabel_cityscapes.py --restore ./snapshots/ReRUN_Adaboost_SWA_SE_GN_batchsize2_1024x512_pp_ms_me0_classbalance7_kl0.1_lr2_drop0.1_seg0.5_swa0/GTA5_40000_average.pthEtapa II (con pseudoetiqueta de recitación): (alrededor del 50,9%)
python train_ft.py --snapshot-dir ./snapshots/Adaboost_1280x640_restore_ft48_GN_batchsize2_960x480_pp_ms_me0_classbalance7_kl0_lr4_drop0.2_seg0.5_BN_80_255_0.8_Noaug_swa2.5W_t97 --restore-from ./snapshots/ReRUN_Adaboost_SWA_SE_GN_batchsize2_1024x512_pp_ms_me0_classbalance7_kl0.1_lr2_drop0.1_seg0.5_swa0/GTA5_40000_average.pth --drop 0.2 --warm-up 5000 --batch-size 2 --learning-rate 4e-4 --crop-size 960,480 --lambda-seg 0.5 --lambda-adv-target1 0 --lambda-adv-target2 0 --lambda-me-target 0 --lambda-kl-target 0 --norm-style gn --class-balance --only-hard-label 80 --max-value 7 --gpu-ids 0 --often-balance --use-se --input-size 1280,640 --train_bn --autoaug False --swa --adaboost --swa_start 25000 --threshold 97Etapa I:
python train_ms_synthia.py --snapshot-dir ./snapshots/AdaBoost_SWA_SY_SE_GN_batchsize2_1024x512_pp_ms_me0_classbalance7_kl0.1_lr2_drop0.1_seg0.5_power0.5 --drop 0.1 --warm-up 5000 --batch-size 2 --learning-rate 2e-4 --crop-size 1024,512 --lambda-seg 0.5 --lambda-adv-target1 0.0002 --lambda-adv-target2 0.001 --lambda-me-target 0 --lambda-kl-target 0.1 --norm-style gn --class-balance --only-hard-label 80 --max-value 7 --gpu-ids 0 --often-balance --use-se --swa --swa_start 0 --adaboost Generar pseudoetiqueta:
python generate_plabel_cityscapes_SYNTHIA.py --restore ./snapshots/AdaBoost_SWA_SY_SE_GN_batchsize2_1024x512_pp_ms_me0_classbalance7_kl0.1_lr2_drop0.1_seg0.5_power0.5/GTA5_50000_average.pthEtapa II:
python train_ft_synthia.py --snapshot-dir ./snapshots/Cosine_Adaboost_SY_1280x640_restore_ft_GN_batchsize8_512x256_pp_ms_me0_classbalance7_kl0.1_lr8_drop0.1_seg0.5_BN_255_Noaug_t777_swa2.5W --restore ./snapshots/AdaBoost_SWA_SY_SE_GN_batchsize2_1024x512_pp_ms_me0_classbalance7_kl0.1_lr2_drop0.1_seg0.5_power0.5/GTA5_50000_average.pth --drop 0.1 --warm-up 5000 --batch-size 8 --learning-rate 8e-4 --crop-size 512,256 --lambda-seg 0.5 --lambda-adv-target1 0 --lambda-adv-target2 0 --lambda-me-target 0 --lambda-kl-target 0 --norm-style gn --class-balance --only-hard-label 50 --max-value 7 --gpu-ids 0 --often-balance --use-se --input-size 1280,640 --autoaug False --swa --swa_start 25000 --threshold 777 --adaboost --train_bn --cosineEtapa I: (alrededor de 73,80%) superior al papel.
python train_ms_robot.py --snapshot-dir ./snapshots/Adaboost_SWA3W_Robot_SE_GN_batchsize6_adapative_kl0.1_sam_lr6 --drop 0.1 --warm-up 5000 --batch-size 6 --learning-rate 6e-4 --crop-size 800,400 --lambda-seg 0.5 --lambda-adv-target1 0.0002 --lambda-adv-target2 0.001 --lambda-me-target 0 --lambda-kl-target 0.1 --norm-style gn --class-balance --only-hard-label 80 --max-value 7 --gpu-ids 0,1,2 --often-balance --use-se --swa --swa_start 30000 --adaboost --samGenerar pseudoetiqueta:
python generate_plabel_robot.py --restore ./snapshots/Adaboost_SWA3W_Robot_SE_GN_batchsize6_adapative_kl0.1_sam_lr6/GTA5_70000_average.pthEtapa II: (alrededor del 75,62%)
python train_ft_robot.py --snapshot-dir ./snapshots/Adaboost_0.9RB_b3_lr3_800x432_97_swa0W_T80 --restore-from ./snapshots/Adaboost_SWA3W_Robot_SE_GN_batchsize6_adapative_kl0.1_sam_lr6/GTA5_70000_average.pth --drop 0.1 --warm-up 5000 --batch-size 3 --learning-rate 3e-4 --crop-size 800,432 --lambda-seg 0.5 --lambda-adv-target1 0 --lambda-adv-target2 0 --lambda-me-target 0 --lambda-kl-target 0 --norm-style gn --class-balance --only-hard-label 50 --max-value 7 --gpu-ids 0,1,2 --often-balance --use-se --input-size 1280,960 --train_bn --adaboost --swa --swa_start 0 --threshold 0.8 --autoaug FalseEtapa I: (alrededor del 39,5%)
python train_ms.py --snapshot-dir ./snapshots/255VGGBN_Adaboost_SWA_SE_GN_batchsize3_1024x512_pp_ms_me0_classbalance7_kl0.1_lr3_drop0.1_seg0.5_swa0_auto --drop 0.1 --warm-up 5000 --batch-size 3 --learning-rate 3e-4 --crop-size 1024,512 --lambda-seg 0.5 --lambda-adv-target1 0.0002 --lambda-adv-target2 0.001 --lambda-me-target 0 --lambda-kl-target 0.1 --norm-style gn --class-balance --only-hard-label 80 --max-value 7 --gpu-ids 0,1,2 --often-balance --use-se --swa --swa_start 0 --adaboost --model DeepVGG --autoaug python evaluate_cityscapes.py --restore-from ./snapshots/ReRUN_Adaboost_SWA_SE_GN_batchsize2_1024x512_pp_ms_me0_classbalance7_kl0.1_lr2_drop0.1_seg0.5_swa0/GTA5_40000_average.pthEl modelo entrenado está disponible en [Esperar]
SY en el nombre es para SYNTHIA-to-CityscapesRB en el nombre es para Cityscapes-to-Robot CarEl código central es relativamente simple y podría aplicarse directamente a otros trabajos.
Muestra de datos adaptable: https://github.com/layumi/AdaBoost_Seg/blob/master/train_ms.py#L429-L436
Agregación de estudiantes: https://github.com/layumi/AdaBoost_Seg/blob/master/train_ms.py#L415-L427
También nos gustaría agradecer los grandes trabajos de la siguiente manera:
@article { zheng2021adaboost ,
title = { Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation } ,
author = { Zheng, Zhedong and Yang, Yi } ,
journal = { IEEE Transactions on Image Processing } ,
doi = { 10.1109/TIP.2022.3195642 } ,
note = { mbox{doi}:url{10.1109/TIP.2022.3195642} } ,
year = { 2021 }
}

