Megatron LM
NVIDIA Megatron Core 0.9.0
Este repositorio comprende dos componentes esenciales: Megatron-LM y Megatron-Core . Megatron-LM sirve como un marco orientado a la investigación que aprovecha Megatron-Core para la capacitación en modelos de lenguajes grandes (LLM). Megatron-Core, por otro lado, es una biblioteca de técnicas de entrenamiento optimizadas para GPU que viene con soporte formal de producto que incluye API versionadas y lanzamientos regulares. Puede utilizar Megatron-Core junto con Megatron-LM o Nvidia NeMo Framework para obtener una solución nativa de la nube de un extremo a otro. Alternativamente, puede integrar los componentes básicos de Megatron-Core en su marco de capacitación preferido.
Introducido por primera vez en 2019, Megatron (1, 2 y 3) provocó una ola de innovación en la comunidad de IA, lo que permitió a investigadores y desarrolladores utilizar los fundamentos de esta biblioteca para promover avances en LLM. Hoy en día, muchos de los marcos de desarrollo de LLM más populares se han inspirado y construido directamente aprovechando la biblioteca de código abierto Megatron-LM, lo que ha estimulado una ola de modelos básicos y nuevas empresas de IA. Algunos de los marcos LLM más populares creados sobre Megatron-LM incluyen Colossal-AI, HuggingFace Accelerate y NVIDIA NeMo Framework. Puede encontrar una lista de proyectos que han utilizado directamente Megatron aquí.
Megatron-Core es una biblioteca de código abierto basada en PyTorch que contiene técnicas optimizadas para GPU y optimizaciones de vanguardia a nivel de sistema. Los abstrae en API modulares y componibles, lo que permite una flexibilidad total para que los desarrolladores e investigadores de modelos entrenen transformadores personalizados a escala en la infraestructura informática acelerada de NVIDIA. Esta biblioteca es compatible con todas las GPU NVIDIA Tensor Core, incluida la compatibilidad con la aceleración FP8 para las arquitecturas NVIDIA Hopper.
Megatron-Core ofrece componentes básicos como mecanismos de atención, bloques y capas de transformadores, capas de normalización y técnicas de incrustación. Funciones adicionales como el recálculo de activación y los puntos de control distribuidos también están integradas de forma nativa en la biblioteca. Todos los componentes básicos y la funcionalidad están optimizados para GPU y se pueden crear con estrategias de paralelización avanzadas para una velocidad de entrenamiento y estabilidad óptimas en la infraestructura de computación acelerada de NVIDIA. Otro componente clave de la biblioteca Megatron-Core incluye técnicas avanzadas de paralelismo de modelos (tensor, secuencia, canalización, contexto y paralelismo experto de MoE).
Megatron-Core se puede utilizar con NVIDIA NeMo, una plataforma de inteligencia artificial de nivel empresarial. Alternativamente, puedes explorar Megatron-Core con el bucle de entrenamiento nativo de PyTorch aquí. Visite la documentación de Megatron-Core para obtener más información.
Nuestra base de código es capaz de entrenar de manera eficiente grandes modelos de lenguaje (es decir, modelos con cientos de miles de millones de parámetros) con paralelismo tanto de modelo como de datos. Para demostrar cómo nuestro software se escala con múltiples GPU y tamaños de modelos, consideramos modelos GPT que van desde 2 mil millones de parámetros hasta 462 mil millones de parámetros. Todos los modelos utilizan un tamaño de vocabulario de 131,072 y una longitud de secuencia de 4096. Variamos el tamaño oculto, la cantidad de cabezas de atención y la cantidad de capas para llegar a un tamaño de modelo específico. A medida que aumenta el tamaño del modelo, también aumentamos modestamente el tamaño del lote. Nuestros experimentos utilizan hasta 6144 GPU H100. Realizamos una superposición detallada de comunicación de datos paralelos ( --overlap-grad-reduce --overlap-param-gather ), tensor-paralelo ( --tp-comm-overlap ) y de canalización paralela (habilitada de forma predeterminada) con Computación para mejorar la escalabilidad. Los rendimientos informados se miden para la capacitación de un extremo a otro e incluyen todas las operaciones, incluida la carga de datos, los pasos del optimizador, la comunicación e incluso el registro. Tenga en cuenta que no entrenamos estos modelos para que converjan.
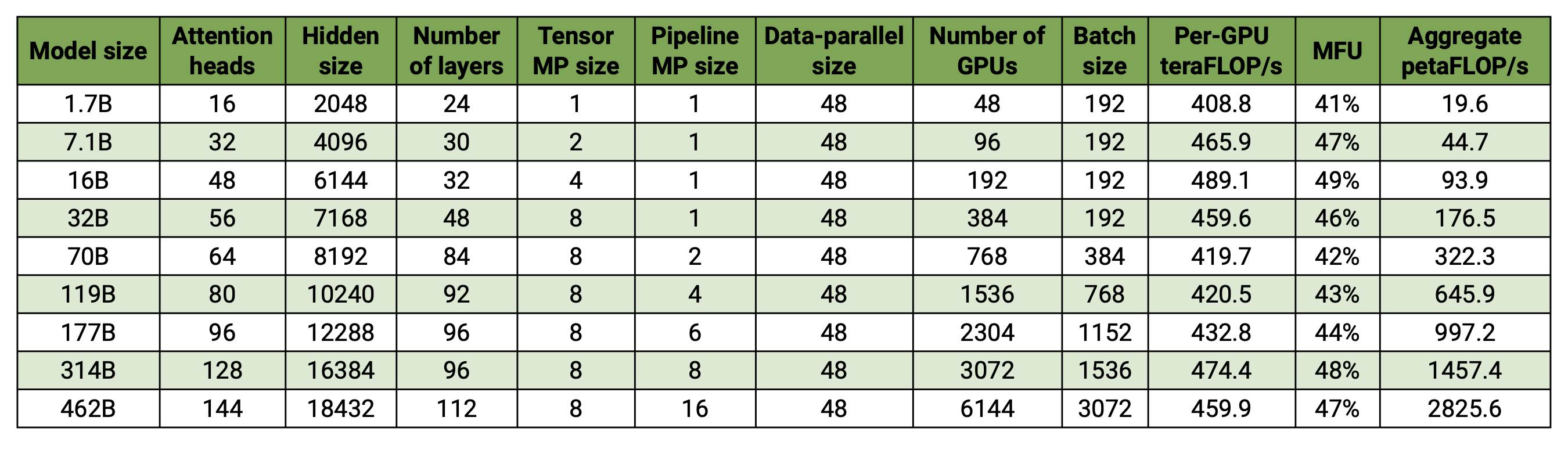
Nuestros resultados escalados débiles muestran una escala superlineal (MFU aumenta del 41% para el modelo más pequeño considerado al 47-48% para los modelos más grandes); esto se debe a que los GEMM más grandes tienen mayor intensidad aritmética y, en consecuencia, son más eficientes de ejecutar.
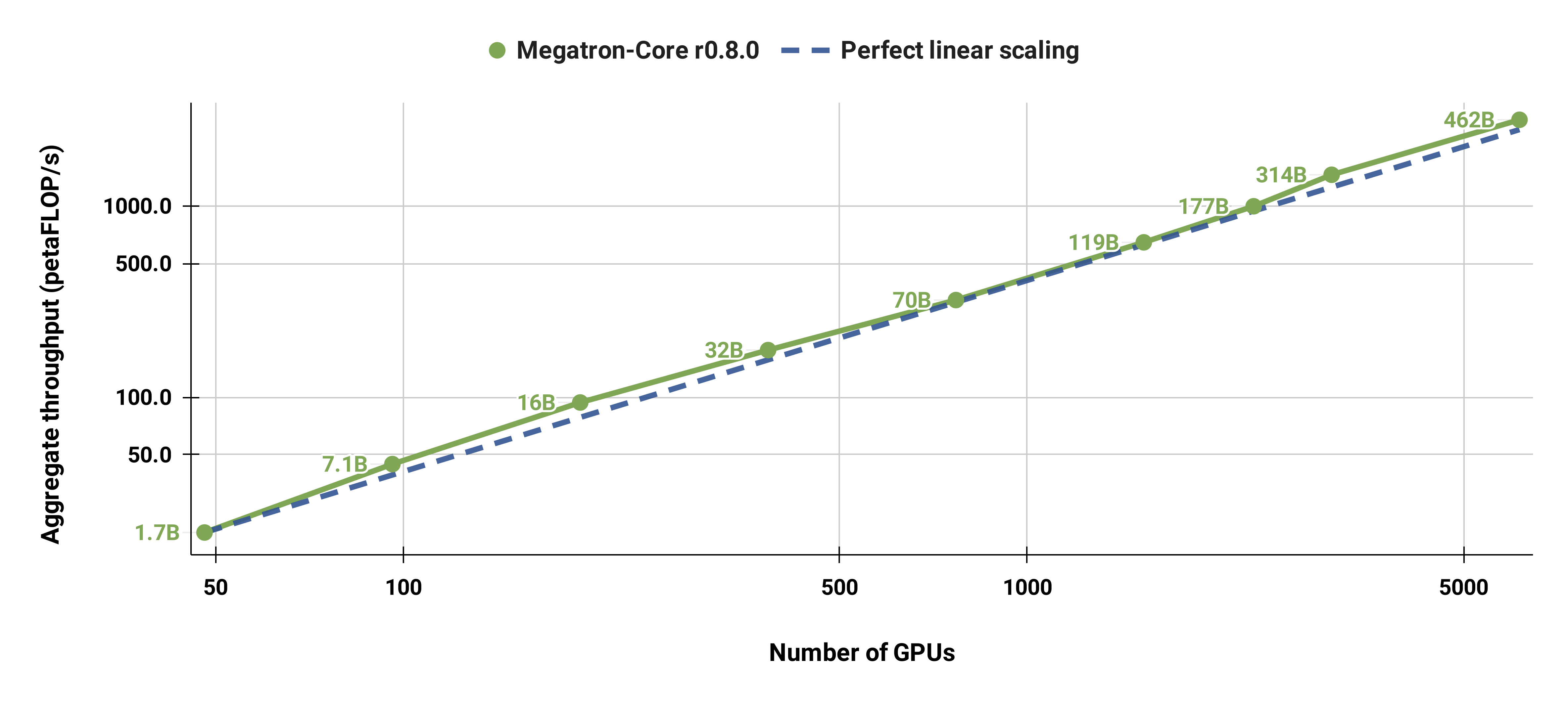
También escalamos con fuerza el modelo GPT-3 estándar (nuestra versión tiene un poco más de 175 mil millones de parámetros debido al mayor tamaño del vocabulario) de 96 GPU H100 a 4608 GPU, utilizando el mismo tamaño de lote de 1152 secuencias en todo momento. La comunicación se vuelve más expuesta a mayor escala, lo que lleva a una reducción en MFU del 47% al 42%.
Recomendamos encarecidamente utilizar la última versión del contenedor PyTorch de NGC con nodos DGX. Si no puede utilizar esto por algún motivo, utilice las últimas versiones de pytorch, cuda, nccl y NVIDIA APEX. El preprocesamiento de datos requiere NLTK, aunque no es necesario para la capacitación, la evaluación o las tareas posteriores.
Puede iniciar una instancia del contenedor PyTorch y montar Megatron, su conjunto de datos y puntos de control con los siguientes comandos de Docker:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
Hemos proporcionado puntos de control BERT-345M y GPT-345M previamente capacitados para evaluar o ajustar tareas posteriores. Para acceder a estos puntos de control, primero regístrese y configure la CLI de registro de NVIDIA GPU Cloud (NGC). Puede encontrar más documentación para descargar modelos en la documentación de NGC.
Alternativamente, puedes descargar directamente los puntos de control usando:
BERT-345M-uncased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
Los modelos requieren archivos de vocabulario para ejecutarse. El archivo de vocabulario BERT Wordpiece se puede extraer de los modelos BERT previamente entrenados por Google: sin caja, con caja. El archivo de vocabulario GPT y la tabla de combinación se pueden descargar directamente.
Después de la instalación, existen varios flujos de trabajo posibles. El más completo es:
Sin embargo, los pasos 1 y 2 se pueden reemplazar utilizando uno de los modelos previamente entrenados mencionados anteriormente.
Hemos proporcionado varios scripts para el entrenamiento previo de BERT y GPT en el directorio examples , así como scripts para tareas posteriores de ajuste cero y de ajuste fino, incluidas las evaluaciones MNLI, RACE, WikiText103 y LAMBADA. También hay un script para la generación de texto interactivo GPT.
Los datos de entrenamiento requieren preprocesamiento. Primero, coloque sus datos de entrenamiento en un formato json flexible, con un json que contenga una muestra de texto por línea. Por ejemplo:
{"src": "www.nvidia.com", "text": "El veloz zorro marrón", "type": "Eng", "id": "0", "title": "Primera parte"}
{"src": "Internet", "text": "salta sobre el perro perezoso", "type": "Eng", "id": "42", "title": "Segunda Parte"}
El nombre del campo text del json se puede cambiar usando el indicador --json-key en preprocess_data.py Los demás metadatos son opcionales y no se utilizan en el entrenamiento.
Luego, el json suelto se procesa en un formato binario para el entrenamiento. Para convertir el json al formato mmap, utilice preprocess_data.py . Un script de ejemplo para preparar datos para el entrenamiento BERT es:
herramientas de Python/preprocess_data.py
--entrada mi-corpus.json
--prefijo-salida mi-bert
--vocab-file bert-vocab.txt
--BertWordPiezaLowerCase tipo tokenizador
--oraciones divididas
El resultado serán dos archivos llamados, en este caso, my-bert_text_sentence.bin y my-bert_text_sentence.idx . La --data-path especificada en una capacitación posterior de BERT es la ruta completa y el nuevo nombre de archivo, pero sin la extensión del archivo.
Para T5, utilice el mismo preprocesamiento que BERT, quizás cambiándole el nombre a:
--prefijo-salida mi-t5
Se requieren algunas modificaciones menores para el preprocesamiento de datos GPT, a saber, agregar una tabla de combinación, un token de fin de documento, eliminar la división de oraciones y un cambio en el tipo de tokenizador:
herramientas de Python/preprocess_data.py
--entrada mi-corpus.json
--prefijo-salida mi-gpt2
--vocab-file gpt2-vocab.json
--GPT2BPETokenizer tipo tokenizador
--merge-file gpt2-merges.txt
--append-eod
Aquí los archivos de salida se denominan my-gpt2_text_document.bin y my-gpt2_text_document.idx . Como antes, en el entrenamiento de GPT, use el nombre más largo sin la extensión como --data-path .
Se describen más argumentos de la línea de comando en el archivo fuente preprocess_data.py .
El script examples/bert/train_bert_340m_distributed.sh ejecuta un preentrenamiento BERT con un solo parámetro GPU 345M. La depuración es el uso principal del entrenamiento de GPU única, ya que la base del código y los argumentos de la línea de comandos están optimizados para un entrenamiento altamente distribuido. La mayoría de los argumentos se explican por sí solos. De forma predeterminada, la tasa de aprendizaje decae linealmente a lo largo de las iteraciones de entrenamiento que comienzan en --lr hasta un mínimo establecido por --min-lr sobre las iteraciones --lr-decay-iters . La fracción de iteraciones de entrenamiento utilizadas para el calentamiento se establece mediante --lr-warmup-fraction . Si bien se trata de un entrenamiento de GPU única, el tamaño de lote especificado por --micro-batch-size es un tamaño de lote de ruta única de avance hacia atrás y el código realizará pasos de acumulación de gradiente hasta alcanzar el global-batch-size que es el tamaño de lote. por iteración. Los datos se dividen en una proporción de 949:50:1 para conjuntos de entrenamiento/validación/prueba (el valor predeterminado es 969:30:1). Esta partición ocurre sobre la marcha, pero es consistente en todas las ejecuciones con la misma semilla aleatoria (1234 de forma predeterminada o especificada manualmente con --seed ). Utilizamos train-iters según las iteraciones de entrenamiento solicitadas. Alternativamente, se puede proporcionar --train-samples , que es el número total de muestras sobre las que entrenar. Si esta opción está presente, en lugar de proporcionar --lr-decay-iters , será necesario proporcionar --lr-decay-samples .
Se especifican las opciones de registro, guardado de puntos de control e intervalo de evaluación. Tenga en cuenta que --data-path ahora incluye el sufijo _text_sentence adicional agregado en el preprocesamiento, pero no incluye las extensiones de archivo.
Se describen más argumentos de la línea de comando en el archivo fuente arguments.py .
Para ejecutar train_bert_340m_distributed.sh , realice las modificaciones que desee, incluida la configuración de las variables de entorno para CHECKPOINT_PATH , VOCAB_FILE y DATA_PATH . Asegúrese de configurar estas variables en sus rutas en el contenedor. Luego inicie el contenedor con Megatron y las rutas necesarias montadas (como se explica en Configuración) y ejecute el script de ejemplo.
El script examples/gpt3/train_gpt3_175b_distributed.sh ejecuta un preentrenamiento GPT con un solo parámetro GPU 345M. Como se mencionó anteriormente, el entrenamiento con una sola GPU está destinado principalmente a fines de depuración, ya que el código está optimizado para el entrenamiento distribuido.
Sigue en gran medida el mismo formato que el script BERT anterior con algunas diferencias notables: el esquema de tokenización utilizado es BPE (que requiere una tabla de combinación y un archivo de vocabulario json ) en lugar de WordPiece, la arquitectura del modelo permite secuencias más largas (tenga en cuenta que el La incrustación de la posición máxima debe ser mayor o igual que la longitud máxima de la secuencia), y el --lr-decay-style se ha configurado en decaimiento del coseno. Tenga en cuenta que --data-path ahora incluye el sufijo _text_document adicional agregado en el preprocesamiento, pero no incluye las extensiones de archivo.
Se describen más argumentos de la línea de comando en el archivo fuente arguments.py .
train_gpt3_175b_distributed.sh se puede iniciar de la misma manera que se describe para BERT. Configure las variables de entorno y realice otras modificaciones, inicie el contenedor con los montajes adecuados y ejecute el script. Más detalles en examples/gpt3/README.md
Muy similar a BERT y GPT, el script examples/t5/train_t5_220m_distributed.sh ejecuta un preentrenamiento T5 de "base" de GPU única (parámetro ~ 220M). La principal diferencia con BERT y GPT es la adición de los siguientes argumentos para adaptarse a la arquitectura T5:
--kv-channels establece la dimensión interna de las matrices de "clave" y "valor" de todos los mecanismos de atención en el modelo. Para BERT y GPT, el valor predeterminado es el tamaño oculto dividido por la cantidad de cabezas de atención, pero se puede configurar para T5.
--ffn-hidden-size establece el tamaño oculto en las redes de alimentación directa dentro de una capa de transformador. Para BERT y GPT, el valor predeterminado es 4 veces el tamaño oculto del transformador, pero se puede configurar para T5.
--encoder-seq-length y --decoder-seq-length establecen la longitud de la secuencia para el codificador y el decodificador por separado.
Todos los demás argumentos permanecen como estaban a favor del preentrenamiento de BERT y GPT. Ejecute este ejemplo con los mismos pasos descritos anteriormente para los otros scripts.
Más detalles en examples/t5/README.md
Los scripts pretrain_{bert,gpt,t5}_distributed.sh utilizan el iniciador distribuido PyTorch para el entrenamiento distribuido. Como tal, el entrenamiento de múltiples nodos se puede lograr configurando adecuadamente las variables de entorno. Consulte la documentación oficial de PyTorch para obtener una descripción más detallada de estas variables de entorno. De forma predeterminada, el entrenamiento de múltiples nodos utiliza el backend distribuido nccl. Un conjunto simple de argumentos adicionales y el uso del módulo distribuido PyTorch con el lanzador elástico torchrun (equivalente a python -m torch.distributed.run ) son los únicos requisitos adicionales para adoptar la capacitación distribuida. Consulte cualquiera de pretrain_{bert,gpt,t5}_distributed.sh para obtener más detalles.
Utilizamos dos tipos de paralelismo: datos y paralelismo de modelos. Nuestra implementación de paralelismo de datos está en megatron/core/distributed y admite la superposición de la reducción de gradiente con el paso hacia atrás cuando se usa la opción de línea de comando --overlap-grad-reduce .
En segundo lugar, desarrollamos un enfoque de modelo paralelo bidimensional simple y eficiente. Para usar la primera dimensión, el paralelismo del modelo tensor (dividir la ejecución de un único módulo transformador en múltiples GPU, consulte la Sección 3 de nuestro artículo), agregue el indicador --tensor-model-parallel-size para especificar la cantidad de GPU entre las cuales divida el modelo, junto con los argumentos pasados al lanzador distribuido como se mencionó anteriormente. Para usar la segunda dimensión, el paralelismo de secuencia, especifique --sequence-parallel , que también requiere que se habilite el paralelismo del modelo tensorial porque se divide en las mismas GPU (más detalles en la Sección 4.2.2 de nuestro artículo).
Para utilizar el paralelismo del modelo de canalización (dividir los módulos transformadores en etapas con un número igual de módulos transformadores en cada etapa y luego canalizar la ejecución dividiendo el lote en microlotes más pequeños, consulte la Sección 2.2 de nuestro artículo), utilice el --pipeline-model-parallel-size -marca --pipeline-model-parallel-size para especificar el número de etapas en las que dividir el modelo (por ejemplo, dividir un modelo con 24 capas de transformador en 4 etapas significaría que cada etapa tendría 6 capas de transformador cada una).
Tenemos ejemplos de cómo utilizar estas dos formas diferentes de paralelismo de modelos: los scripts de ejemplo que terminan en distributed_with_mp.sh .
Aparte de estos cambios menores, el entrenamiento distribuido es idéntico al entrenamiento en una sola GPU.
El cronograma de canalización entrelazada (más detalles en la Sección 2.2.2 de nuestro artículo) se puede habilitar usando el argumento --num-layers-per-virtual-pipeline-stage , que controla el número de capas de transformador en una etapa virtual (por defecto con el cronograma no intercalado, cada GPU ejecutará una única etapa virtual con NUM_LAYERS / PIPELINE_MP_SIZE capas de transformador). El número total de capas en el modelo del transformador debe ser divisible por el valor de este argumento. Además, la cantidad de microlotes en la tubería (calculada como GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) ) debe ser divisible por PIPELINE_MP_SIZE cuando se usa esta programación (esta condición se verifica en una aserción en el código). El cronograma entrelazado no es compatible con canalizaciones con 2 etapas ( PIPELINE_MP_SIZE=2 ).
Para reducir el uso de memoria de la GPU al entrenar un modelo grande, admitimos varias formas de puntos de control de activación y recálculo. En lugar de que todas las activaciones se almacenen en la memoria para usarse durante la backprop, como era tradicionalmente el caso en los modelos de aprendizaje profundo, solo las activaciones en ciertos "puntos de control" en el modelo se retienen (o almacenan) en la memoria, y las otras activaciones se recalculan en -the-fly cuando sea necesario para backprop. Tenga en cuenta que este tipo de punto de control, el punto de control de activación , es muy diferente del punto de control de los parámetros del modelo y el estado del optimizador, que se menciona en otra parte.
Admitimos dos niveles de granularidad de recálculo: selective y full . El recálculo selectivo es el predeterminado y se recomienda en casi todos los casos. Este modo retiene en la memoria las activaciones que ocupan menos espacio de almacenamiento en la memoria y son más caras de recalcular y vuelve a calcular las activaciones que ocupan más espacio de almacenamiento en la memoria pero que son relativamente económicas de recalcular. Consulte nuestro documento para obtener más detalles. Debería descubrir que este modo maximiza el rendimiento y minimiza la memoria necesaria para almacenar las activaciones. Para habilitar el recálculo de activación selectiva, simplemente use --recompute-activations .
Para los casos en los que la memoria es muy limitada, el recálculo full guarda solo las entradas a una capa de transformador, o un grupo o bloque de capas de transformador, y vuelve a calcular todo lo demás. Para habilitar el recálculo de activación completa, utilice --recompute-granularity full . Cuando se utiliza el recálculo de activación full , hay dos métodos: uniform y block , elegidos mediante el argumento --recompute-method .
El método uniform divide uniformemente las capas del transformador en grupos de capas (cada grupo de tamaño --recompute-num-layers ) y almacena las activaciones de entrada de cada grupo en la memoria. El tamaño del grupo de referencia es 1 y, en este caso, se almacena la activación de entrada de cada capa del transformador. Cuando la memoria de la GPU es insuficiente, aumentar el número de capas por grupo reduce el uso de memoria, lo que permite entrenar un modelo más grande. Por ejemplo, cuando --recompute-num-layers se establece en 4, solo se almacena la activación de entrada de cada grupo de 4 capas de transformador.
El método block vuelve a calcular las activaciones de entrada de un número específico (dado por --recompute-num-layers ) de capas de transformadores individuales por etapa de la tubería y almacena las activaciones de entrada de las capas restantes en la etapa de la tubería. La reducción de --recompute-num-layers da como resultado el almacenamiento de las activaciones de entrada en más capas de transformador, lo que reduce el recálculo de activación requerido en el backprop, mejorando así el rendimiento del entrenamiento y aumentando el uso de la memoria. Por ejemplo, cuando especificamos 5 capas para recalcular de 8 capas por etapa de canalización, las activaciones de entrada de solo las primeras 5 capas del transformador se recalculan en el paso de backprop mientras que las activaciones de entrada para las 3 capas finales se almacenan. --recompute-num-layers se puede aumentar gradualmente hasta que la cantidad de espacio de almacenamiento de memoria requerida sea lo suficientemente pequeña como para caber en la memoria disponible, utilizando así la memoria al máximo y maximizando el rendimiento.
Uso: --use-distributed-optimizer . Compatible con todos los modelos y tipos de datos.
El optimizador distribuido es una técnica de ahorro de memoria, mediante la cual el estado del optimizador se distribuye uniformemente entre rangos paralelos de datos (a diferencia del método tradicional de replicar el estado del optimizador entre rangos paralelos de datos). Como se describe en ZeRO: Optimizaciones de memoria para entrenar billones de modelos de parámetros, nuestra implementación distribuye todo el estado del optimizador que no se superpone con el estado del modelo. Por ejemplo, cuando se utilizan los parámetros del modelo fp16, el optimizador distribuido mantiene su propia copia separada de los parámetros y grados principales de fp32, que se distribuyen entre los rangos DP. Sin embargo, cuando se utilizan los parámetros del modelo bf16, los grados principales de fp32 del optimizador distribuido son los mismos que los del modelo fp32, por lo que en este caso los grados no se distribuyen (aunque los parámetros principales de fp32 todavía están distribuidos, ya que están separados del bf16). parámetros del modelo).
Los ahorros de memoria teóricos varían según la combinación del tipo de parámetro y el tipo de graduación del modelo. En nuestra implementación, el número teórico de bytes por parámetro es (donde 'd' es el tamaño paralelo de los datos):
| Optim no distribuido | Optimidad distribuida | |
|---|---|---|
| parámetros fp16, graduados fp16 | 20 | 4 + 16/día |
| parámetro bf16, graduados fp32 | 18 | 6 + 12/día |
| parámetros fp32, graduados fp32 | 16 | 8 + 8/día |
Al igual que con el paralelismo de datos normal, la superposición de la reducción de gradiente (en este caso, una reducción-dispersión) con el paso hacia atrás se puede facilitar utilizando el indicador --overlap-grad-reduce . Además, la superposición del parámetro all-gather se puede superponer con el pase hacia adelante usando --overlap-param-gather .
Uso: --use-flash-attn . Dimensiones del cabezal de atención de soporte como máximo 128.
FlashAttention es un algoritmo rápido y eficiente en memoria para calcular la atención exacta. Acelera el entrenamiento de modelos y reduce la necesidad de memoria.
Para instalar FlashAttention:
pip install flash-attn En examples/gpt3/train_gpt3_175b_distributed.sh proporcionamos un ejemplo de cómo configurar Megatron para entrenar GPT-3 con 175 mil millones de parámetros en 1024 GPU. El script está diseñado para slurm con el complemento pyxis, pero puede adoptarse fácilmente en cualquier otro programador. Utiliza paralelismo tensorial de 8 vías y paralelismo de canalización de 16 vías. Con las opciones global-batch-size 1536 y rampup-batch-size 16 16 5859375 , el entrenamiento comenzará con el tamaño de lote global 16 y aumentará linealmente el tamaño del lote global a 1536 en 5,859,375 muestras con pasos incrementales 16. El conjunto de datos de entrenamiento puede ser un único conjunto o varios conjuntos de datos combinados con un conjunto de ponderaciones.
Con un tamaño de lote global completo de 1536 en 1024 GPU A100, cada iteración dura alrededor de 32 segundos, lo que da como resultado 138 teraFLOP por GPU, que es el 44 % de los FLOP máximos teóricos.
Retro (Borgeaud et al., 2022) es un modelo de lenguaje autorregresivo solo decodificador (LM) preentrenado con recuperación-aumento. Retro presenta una escalabilidad práctica para respaldar el entrenamiento previo a gran escala desde cero mediante la recuperación de billones de tokens. El entrenamiento previo con recuperación proporciona un mecanismo de almacenamiento de conocimiento factual más eficiente, en comparación con el almacenamiento de conocimiento factual implícitamente dentro de los parámetros de la red, lo que reduce en gran medida los parámetros del modelo y logra una menor perplejidad que el GPT estándar. Retro también brinda la flexibilidad de actualizar el conocimiento almacenado en los LM (Wang et al., 2023a) actualizando la base de datos de recuperación sin volver a entrenar los LM.
InstructRetro (Wang et al., 2023b) amplía aún más el tamaño de Retro a 48B, presentando el LLM más grande preentrenado con recuperación (a diciembre de 2023). El modelo base obtenido, Retro 48B, supera ampliamente a su homólogo GPT en términos de perplejidad. Con el ajuste de instrucciones en Retro, InstructRetro demuestra una mejora significativa con respecto al GPT con instrucciones ajustadas en tareas posteriores en la configuración de disparo cero. Específicamente, la mejora promedio de InstructRetro es del 7 % con respecto a su contraparte GPT en 8 tareas de control de calidad de formato corto y del 10 % con respecto a GPT en 4 tareas desafiantes de control de calidad de formato largo. También encontramos que se puede eliminar el codificador de la arquitectura InstructRetro y usar directamente la columna vertebral del decodificador InstructRetro como GPT, mientras se logran resultados comparables.
En este repositorio, proporcionamos una guía de reproducción de un extremo a otro para implementar Retro e InstructRetro, que cubre
Consulte tools/retro/README.md para obtener una descripción detallada.
Ver ejemplos/mamba para más detalles.
Proporcionamos varios argumentos de línea de comando, detallados en los scripts que se enumeran a continuación, para manejar varias tareas posteriores de ajuste fino y de disparo cero. Sin embargo, también puede ajustar su modelo desde un punto de control previamente entrenado en otros corpus según lo desee. Para hacerlo, simplemente agregue el indicador --finetune y ajuste los archivos de entrada y los parámetros de entrenamiento dentro del script de entrenamiento original. El recuento de iteraciones se restablecerá a cero y el optimizador y el estado interno se reinicializarán. Si el ajuste se interrumpe por algún motivo, asegúrese de eliminar el indicador --finetune antes de continuar; de lo contrario, el entrenamiento comenzará nuevamente desde el principio.
Debido a que la evaluación requiere sustancialmente menos memoria que el entrenamiento, puede resultar ventajoso fusionar un modelo entrenado en paralelo para usarlo en menos GPU en tareas posteriores. El siguiente script logra esto. Este ejemplo lee un modelo GPT con tensor de 4 vías y paralelismo del modelo de canalización de 4 vías y escribe un modelo con tensor de 2 vías y paralelismo del modelo de canalización de 2 vías.
herramientas de Python/checkpoint/convert.py
--tipo de modelo GPT
--load-dir puntos de control/gpt3_tp4_pp4
--save-dir puntos de control/gpt3_tp2_pp2
--objetivo-tensor-paralelo-tamaño 2
--objetivo-tubería-paralela-tamaño 2
A continuación se describen varias tareas posteriores para los modelos GPT y BERT. Se pueden ejecutar en modos distribuidos y modelo paralelo con los mismos cambios utilizados en los scripts de entrenamiento.
Hemos incluido un servidor REST simple para usar en la generación de texto en tools/run_text_generation_server.py . Lo ejecuta de manera muy similar a como iniciaría un trabajo de preentrenamiento, especificando un punto de control preentrenado apropiado. También hay algunos parámetros opcionales: temperature , top-k y top-p . Consulte --help o el archivo fuente para obtener más información. Consulte ejemplos/inference/run_text_generation_server_345M.sh para ver un ejemplo de cómo ejecutar el servidor.
Una vez que el servidor se está ejecutando, puede usar tools/text_generation_cli.py para consultarlo, se necesita un argumento que sea el host en el que se está ejecutando el servidor.
herramientas/text_generación_cli.py localhost:5000
También puedes usar CURL o cualquier otra herramienta para consultar el servidor directamente:
curl 'http://localhost:5000/api' -X 'PUT' -H 'Tipo de contenido: aplicación/json; charset=UTF-8' -d '{"prompts":["Hola mundo"], "tokens_to_generate":1}'
Consulte megatron/inference/text_generation_server.py para obtener más opciones de API.
Incluimos un ejemplo en examples/academic_paper_scripts/detxoify_lm/ para desintoxicar los modelos de lenguaje aprovechando el poder generativo de los modelos de lenguaje.
Consulte ejemplos/academic_paper_scripts/detxoify_lm/README.md para obtener tutoriales paso a paso sobre cómo realizar entrenamiento adaptativo de dominio y desintoxicar LM utilizando corpus autogenerado.
Incluimos scripts de ejemplo para la evaluación GPT en la evaluación de perplejidad de WikiText y la precisión de LAMBADA Cloze.
Para una comparación uniforme con trabajos anteriores, evaluamos la perplejidad en el conjunto de datos de prueba WikiText-103 a nivel de palabra y calculamos adecuadamente la perplejidad dado el cambio en los tokens cuando usamos nuestro tokenizador de subpalabras.
Usamos el siguiente comando para ejecutar la evaluación WikiText-103 en un modelo de parámetros de 345M.
TAREA="WIKITEXT103"
VALID_DATA=<ruta del wikitexto>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=puntos de control/gpt2_345m
COMMON_TASK_ARGS="--núm-capas 24
--tamaño oculto 1024
--num-atención-cabezas 16
--longitud secuencial 1024
--max-position-incrustaciones 1024
--fp16
--archivo-vocab $VOCAB_FILE"
tareas de Python/main.py
--tarea $TASA
$COMMON_TASK_ARGS
--datos válidos $VALID_DATA
--GPT2BPETokenizer tipo tokenizador
--merge-file $MERGE_FILE
--cargar $CHECKPOINT_PATH
--micro-lote-tamaño 8
--intervalo-log 10
--sin-carga-optim
--sin-carga-rng
Para calcular la precisión del cierre de LAMBADA (la precisión de predecir el último token dados los tokens anteriores) utilizamos una versión procesada y detokenizada del conjunto de datos de LAMBADA.
Usamos el siguiente comando para ejecutar la evaluación LAMBADA en un modelo de parámetros 345M. Tenga en cuenta que se debe utilizar la opción --strict-lambada para exigir la coincidencia de palabras completas. Asegúrese de que lambada sea parte de la ruta del archivo.
TAREA="LAMBADA"
VALID_DATA=<ruta lambada>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=puntos de control/gpt2_345m
COMMON_TASK_ARGS=<igual que los de la Evaluación de Perplejidad de WikiText arriba>
tareas de Python/main.py
--tarea $TASA
$COMMON_TASK_ARGS
--datos válidos $VALID_DATA
--GPT2BPETokenizer tipo tokenizador
--estricta-lambada
--merge-file $MERGE_FILE
--cargar $CHECKPOINT_PATH
--micro-lote-tamaño 8
--intervalo-log 10
--sin-carga-optim
--sin-carga-rng
Se describen más argumentos de la línea de comando en el archivo fuente main.py
El siguiente script ajusta el modelo BERT para su evaluación en el conjunto de datos RACE. Los directorios TRAIN_DATA y VALID_DATA contienen el conjunto de datos RACE como archivos .txt separados. Tenga en cuenta que para RACE, el tamaño del lote es la cantidad de consultas RACE a evaluar. Dado que cada consulta RACE tiene cuatro muestras, el tamaño de lote efectivo pasado a través del modelo será cuatro veces el tamaño de lote especificado en la línea de comando.
TRAIN_DATA="datos/RACE/tren/medio"
VALID_DATA="datos/RACE/dev/middle
datos/RACE/dev/alta"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=puntos de control/bert_345m
CHECKPOINT_PATH=puntos de control/bert_345m_race
COMMON_TASK_ARGS="--núm-capas 24
--tamaño oculto 1024
--num-atención-cabezas 16
--longitud de secuencia 512
--incrustaciones-de-posición-max 512
--fp16
--archivo-vocab $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--datos-del-tren $TRAIN_DATA
--datos válidos $VALID_DATA
--punto de control previamente entrenado $PRETRAINED_CHECKPOINT
--intervalo de guardado 10000
--guardar $CHECKPOINT_PATH
--intervalo-log 100
--intervalo-eval 1000
--eval-iters 10
--decaimiento de peso 1.0e-1"
tareas de Python/main.py
--tarea CARRERA
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--BertWordPiezaLowerCase tipo tokenizador
--épocas 3
--micro-lote-tamaño 4
--lr 1.0e-5
--lr-fracción-de-calentamiento 0.06
El siguiente script afina el modelo BERT para la evaluación con el corpus de pares de oraciones MultiNLI. Debido a que las tareas de comparación son bastante similares, el script se puede modificar rápidamente para que funcione también con el conjunto de datos de pares de preguntas de Quora (QQP).
Train_data = "Data/Glue_Data/Mnli/Train.tsv"
Válido_data = "data/glue_data/mnli/dev_matched.tsv
data/glue_data/mnli/dev_mismatched.tsv "
Preturse_checkpoint = checkpoints/bert_345m
VOCAB_FILE = bert-vocab.txt
Checkpoint_path = checkpoints/bert_345m_mnli
Common_task_args = <Igual que los de la evaluación de la carrera arriba>
Common_task_args_ext = <Igual que los de la evaluación de la carrera arriba>
Tareas de Python/main.py
-A-Task Mnli
$ Common_Task_args
$ Common_Task_args_ext
-BertwordPiecElowastcase de tipo bourkenizer
--epochs 5
--micro-batch-size 8
-LR 5.0E-5
--LR-Warmup-Fraction 0.065
La familia de modelos LLAMA-2 es un conjunto de código abierto de modelos previos a la aparición y mínimo (para el chat) que han logrado fuertes resultados en un amplio conjunto de puntos de referencia. En el momento del lanzamiento, los modelos LLAMA-2 lograron entre los mejores resultados para los modelos de código abierto, y fueron competitivos con el modelo GPT-3.5 de código cerrado (ver https://arxiv.org/pdf/2307.09288.pdf).
Los puntos de control LLAMA-2 se pueden cargar en Megatron para inferencia y ficha. Vea la documentación aquí.
La familia Megatron-Core (MCORE) GPTModel apoya los algoritmos de cuantificación avanzados e inferencia de alto rendimiento a través de Tensorrt-LLM.
Vea la optimización e implementación del modelo Megatron para ejemplos de llama2 y nemotron3 .
No organizamos ningún conjunto de datos para la capacitación GPT o BERT, sin embargo, detallamos su colección para que nuestros resultados puedan reproducirse.
Recomendamos seguir el proceso de extracción de datos de Wikipedia especificado por Google Research: "El preprocesamiento recomendado es descargar el último volcado, extraer el texto con wikiextractor.py y luego aplicar cualquier limpieza necesaria para convertirlo en texto plano".
Recomendamos usar el argumento --json cuando se usa Wikiextractor, que arrojará los datos de Wikipedia en formato JSON suelto (un objeto JSON por línea), lo que lo hace más manejable en el sistema de archivos y también fácilmente consumible por nuestra base de código. Recomendamos un preprocesamiento adicional de este conjunto de datos JSON con la estandarización de puntuación NLTK. Para el entrenamiento de Bert, use el indicador --split-sentences a preprocess_data.py como se describió anteriormente para incluir saltos de oraciones en el índice producido. Si desea utilizar los datos de Wikipedia para el entrenamiento GPT, aún debe limpiarlos con NLTK/Spacy/FTFY, pero no use el indicador --split-sentences .
Utilizamos la biblioteca OpenWebText disponible públicamente desde el trabajo de JCPeterson y Eukaryote31 para descargar URL. Luego filtramos, limpiamos y dedicamos todo el contenido descargado de acuerdo con el procedimiento descrito en nuestro directorio OpenWebText. Para las URL Reddit correspondientes al contenido hasta octubre de 2018 llegamos a aproximadamente 37 GB de contenido.
El entrenamiento megatron puede ser reproducible a bit a bit; Para habilitar este modo, use --deterministic-mode . Esto significa que la misma configuración de entrenamiento se ejecuta dos veces en el mismo entorno HW y SW debería producir puntos de control de modelo idénticos, pérdidas y valores de métricos de precisión (las métricas de tiempo de iteración pueden variar).
Actualmente hay tres optimizaciones de megatron conocidas que rompen la reproducibilidad, mientras que aún producen carreras de entrenamiento casi idénticas:
NCCL_ALGO ) es importante. Hemos probado lo siguiente: ^NVLS , Tree , Ring , CollnetDirect , CollnetChain . El código admite el uso de ^NVLS , que permite a NCCL la elección de algoritmos no NVLS; Su elección parece ser estable.--use-flash-attn .NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 .Además, el determinisim solo se ha verificado en contenedores NGC Pytorch hasta 23.12. Si observa el no determinismo en la capacitación megatron en otras circunstancias, abra un problema.
A continuación se presentan algunos de los proyectos donde hemos usado directamente Megatron:


