tabled
1.0.0
Tabled es una pequeña biblioteca para detectar y extraer tablas. Utiliza surya para buscar todas las tablas en un PDF, identifica las filas/columnas y formatea las celdas en Markdown, CSV o HTML.
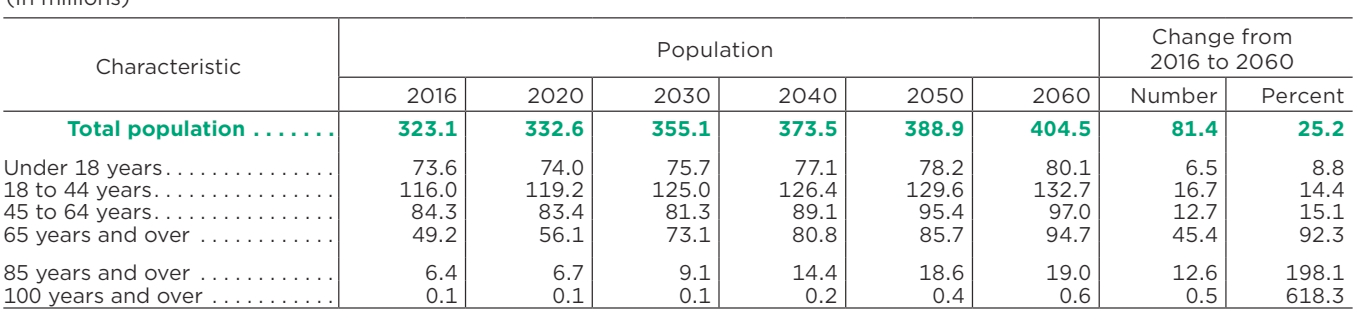
| Característica | Población | Cambio de 2016 a 2060 | ||||||
|---|---|---|---|---|---|---|---|---|
| 2016 | 2020 | 2030 | 2040 | 2050 | 2060 | Número | Por ciento | |
| Población total | 323.1 | 332,6 | 355.1 | 373,5 | 388,9 | 404.5 | 81,4 | 25.2 |
| Menores de 18 años | 73,6 | 74.0 | 75,7 | 77.1 | 78.2 | 80.1 | 6.5 | 8.8 |
| 18 a 44 años | 116.0 | 119.2 | 125.0 | 126,4 | 129,6 | 132,7 | 16.7 | 14.4 |
| 45 a 64 años | 84,3 | 83,4 | 81.3 | 89.1 | 95,4 | 97.0 | 12.7 | 15.1 |
| 65 años y más | 49.2 | 56.1 | 73.1 | 80,8 | 85,7 | 94,7 | 45,4 | 92.3 |
| 85 años y más | 6.4 | 6.7 | 9.1 | 14.4 | 18.6 | 19.0 | 12.6 | 198.1 |
| 100 años y más | 0.1 | 0.1 | 0.1 | 0.2 | 0,4 | 0,6 | 0,5 | 618.3 |
Discord es donde discutimos el desarrollo futuro.
Hay una API alojada para presentaciones disponibles aquí:
Funciona con PDF, imágenes, documentos de Word y PowerPoint
Velocidad constante, sin picos de latencia
Alta confiabilidad y tiempo de actividad
Quiero que la presentación sea lo más accesible posible y al mismo tiempo financie mis costos de desarrollo/capacitación. La investigación y el uso personal siempre están bien, pero existen algunas restricciones sobre el uso comercial.
Los pesos de los modelos tienen licencia cc-by-nc-sa-4.0 , pero lo renunciaré a cualquier organización con menos de $5 millones de dólares en ingresos brutos en el período de 12 meses más reciente Y menos de $5 millones en financiación de capital de riesgo/ángel de por vida. aumentó. Tampoco debes ser competitivo con la API de Datalab. Si desea eliminar los requisitos de la licencia GPL (licencia dual) y/o utilizar los pesos comercialmente por encima del límite de ingresos, consulte las opciones aquí.
Necesitará Python 3.10+ y PyTorch. Es posible que primero necesites instalar la versión CPU de torch si no estás usando una Mac o una máquina con GPU. Consulte aquí para obtener más detalles.
Instalar con:
instalación de pip tabulado-pdf
Postinstalación:
Inspeccione la configuración en tabled/settings.py . Puede anular cualquier configuración con variables de entorno.
Su dispositivo de antorcha se detectará automáticamente, pero puede anularlo. Por ejemplo, TORCH_DEVICE=cuda .
Los pesos del modelo se descargarán automáticamente la primera vez que ejecute tabled.
DATA_PATH presentado
DATA_PATH puede ser una imagen, un pdf o una carpeta de imágenes/pdf
--format especifica el formato de salida para cada tabla ( markdown , html o csv )
--save_json guarda información adicional de filas y columnas en un archivo json
--save_debug_images guarda imágenes que muestran las filas y columnas detectadas
--skip_detection significa que las imágenes que pasa son todas tablas recortadas y no necesitan ninguna detección de tabla.
--detect_cell_boxes de forma predeterminada, tabulado intentará extraer información de la celda del pdf. Si, en cambio, desea que un modelo de detección detecte las celdas, especifique esto (normalmente solo lo necesita con archivos PDF que tienen texto incrustado incorrecto).
--save_images especifica que se deben guardar las imágenes de las filas/columnas y celdas detectadas.
Después de ejecutar el script, el directorio de salida contendrá carpetas con los mismos nombres base que los nombres de los archivos de entrada. Dentro de esas carpetas estarán los archivos de rebajas para cada tabla en los documentos fuente. Opcionalmente también habrá imágenes de las tablas.
También habrá un archivo results.json en la raíz del directorio de salida. El archivo contendrá un diccionario json donde las claves son los nombres de archivos de entrada sin extensiones. Cada valor será una lista de diccionarios, uno por tabla en el documento. Cada diccionario de tabla contiene:
cells : el texto detectado y los cuadros delimitadores para cada celda de la tabla.
bbox - bbox de la celda dentro de la tabla bbox
text - el texto de la celda
row_ids : identificadores de filas a las que pertenece la celda
col_ids : identificadores de las columnas a las que pertenece la celda
order : orden de esta celda dentro de su celda de fila/columna asignada. (ordenar por fila, luego columna, luego ordenar)
rows - bboxes de las filas detectadas
bbox - bbox de la fila en formato (x1, x2, y1, y2)
row_id - identificación única de la fila
cols - bboxes de columnas detectadas
bbox - bbox de la columna en formato (x1, x2, y1, y2)
col_id - identificación única de la columna
image_bbox : el bbox de la imagen en formato (x1, y1, x2, y2). (x1, y1) es la esquina superior izquierda y (x2, y2) es la esquina inferior derecha. La tabla bbox es relativa a esto.
bbox : el cuadro delimitador de la tabla dentro del bbox de la imagen.
pnum : número de página dentro del documento
tnum - índice de tabla en la página
He incluido una aplicación optimizada que te permite probar interactivamente imágenes o archivos PDF. Ejecútelo con:
instalación de pip optimizada tabled_gui
de tabled.extract importar extract_tablesde tabled.fileinput importar load_pdfs_imagesde tabled.inference.models importar load_detection_models, load_recognition_modelsdet_models, rec_models = load_detection_models(), load_recognition_models()images, highres_images, nombres, text_lines = load_pdfs_images(IN_PATH)page_results = extraer_tables(imágenes, imágenes_de_alta resolución, líneas_de_texto, modelos_det, modelos_rec)
| Puntuación media | Tiempo por mesa | Tablas totales |
|---|---|---|
| 0,847 | 0,029 | 688 |
Obtener buenos datos reales para las tablas es difícil, ya que o está limitado a diseños simples que pueden analizarse y representarse heurísticamente, o necesita usar LLM, que cometen errores. Elegí utilizar las predicciones de la tabla GPT-4 como una pseudoverdad fundamental.
Tabled obtiene una puntuación de alineación .847 en comparación con GPT-4, que indica la alineación entre el texto en las filas/celdas de la tabla. Algunas de las desalineaciones se deben a errores de GPT-4 o pequeñas inconsistencias en lo que GPT-4 consideraba los límites de la tabla. En general, la calidad de la extracción es bastante alta.
Al ejecutarse en un A10G con 10 GB de uso de VRAM y un tamaño de lote 64 , la presentación en tabla demora .029 segundos por tabla.
Ejecute el punto de referencia con:
puntos de referencia de Python/benchmark.py out.json
Gracias a Peter Jansen por el conjunto de datos de evaluación comparativa y por la discusión sobre el análisis de tablas.
Huggingface para código de inferencia y alojamiento de modelos
PyTorch para entrenamiento/inferencia


