Por Buqian Zheng (buqianz) y Yongkang Huang (yongkan1)
Póster
Implementamos Corgy, un marco de aprendizaje profundo en Swift y Metal. Corgy puede integrarse en aplicaciones macOS e iOS y usarse para construir redes neuronales entrenadas y evaluarlas con facilidad. Logramos una aceleración de más de 60 veces en diferentes dispositivos con diferentes GPU.

Metal 2 framework es una interfaz proporcionada por Apple que proporciona acceso casi directo a la unidad de procesamiento de gráficos (GPU) en iPhone/iPad y Mac. Además de los gráficos, Metal 2 incorporó una serie de bibliotecas que brindan un excelente soporte de paralelización para las operaciones de álgebra lineal necesarias y funciones de procesamiento de señales que pueden ejecutarse en varios tipos de dispositivos Apple. Estas bibliotecas nos permitieron crear modelos de aprendizaje profundo acelerados por GPU bien implementados en dispositivos iOS basados en el modelo entrenado proporcionado por otros marcos. 1
En términos generales, la etapa de inferencia de una red neuronal entrenada requiere mucha computación, especialmente para aquellos modelos que tienen una cantidad considerablemente grande de capas o se aplican en los escenarios que son necesarios para procesar imágenes de alta resolución. Vale la pena señalar que existe una enorme cantidad de cálculo matricial (por ejemplo, capa convolucional) que es apropiado aplicar operaciones en paralelo para optimizar el rendimiento.
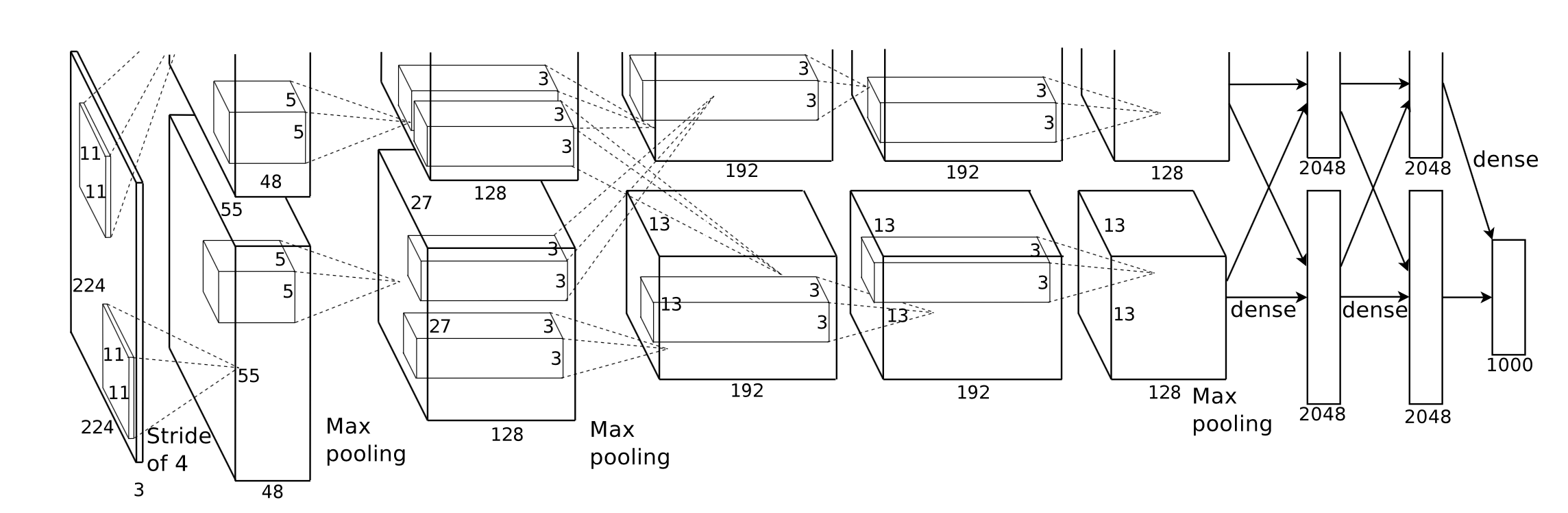
El primer desafío que enfrentamos es diseñar una buena abstracción de la interfaz de programación de aplicaciones que sea expresiva, fácil de usar con una curva de aprendizaje baja y fácil de usar para nuestros usuarios.
Durante todo el proceso de desarrollo, hicimos todo lo posible para mantener la API pública lo más simple posible, con todas las propiedades necesarias para crear todos los componentes requeridos aprovechando el mecanismo de programación funcional proporcionado por Swift. También ocultamos deliberadamente la abstracción de hardware innecesaria proporcionada por Metal para suavizar la curva de aprendizaje.
Aunque el modelo entrenado de las distintas redes es fácil de obtener en Internet, la heterogeneidad entre ellos causada por las diferentes implementaciones que aplican varios tipos de herramientas facilitó el trabajo para crear un importador de modelos universal.
Parte del cálculo es fácil de entender por su concepción, pero requiere una reflexión atenta cuando se desea crear una implementación efectiva abstrayéndolo. La convolución es un ejemplo representativo.
La propiedad intrínseca de la operación de convolución no tiene una buena localidad, la implementación básica es difícil de entender e ineficaz con bucles for complicados. Además, debemos considerar la abstracción proporcionada por Metal 2 y crear una manera conveniente de compartir la información y las estructuras de datos necesarias entre el host y el dispositivo con una cuidadosa consideración de la representación de los datos y el diseño de la memoria.
Durante la fase de desarrollo, somos conscientes de que nuestro código se ejecuta normalmente en macOS e iOS sin comprometer el rendimiento en ambas plataformas. Hicimos todo lo posible para mantener la biblioteca de códigos que sea capaz de compilar y ejecutar en ambas plataformas. Tenemos la precaución de maximizar el código compartido entre los diferentes objetivos y reutilizar el código tanto como sea posible.
Dado que un componente completamente implementado de la capa de red neuronal debe brindar soporte con una cantidad razonable de parámetros que hagan que el componente sea lo suficientemente utilizable, la complejidad de los componentes es realmente bastante impresionante. Por ejemplo, la capa convolucional debe admitir los parámetros que incorporan relleno, zancada de dilatación, etc. y todos ellos deben considerarse con cautela al realizar la paralelización que logra un rendimiento razonable. Construimos algunas redes simples para hacer la prueba de regresión. Los casos de prueba se crean en otros marcos (principalmente PyTorch y Keras) para garantizar que toda la implementación funcione correctamente.
Swift se desarrolló por primera vez en julio de 2010 y se publicó y fue de código abierto en 2014. Aunque han pasado casi 4 años desde su publicación, la falta de una biblioteca impactante sigue siendo un problema que no se puede ignorar. Alguna razón causó esta situación, el papel dominante de Apple y la rápida iteración natural de Swift podrían ser la razón de este fenómeno. Algunas bibliotecas que son cruciales para nosotros no son lo suficientemente potentes o funcionales para nuestras necesidades, o no están bien mantenidas por el desarrollador individual que las inventó. Dedicamos bastante tiempo a implementar una Variable de clase tensorial que funcione bien para nuestras demandas.
Además, esta es otra razón para obstaculizar el desarrollo de un analizador de modelos universal porque la función de manejo de archivos y cadenas tiene una capacidad muy limitada.
Además, las herramientas de desarrollo y depuración están básicamente restringidas a Xcode, aunque hay otras opciones que, de manera más general, para nosotros, Xcode sigue siendo la herramienta estándar de facto para nuestro desarrollo.
Para el ajuste del rendimiento de los dispositivos móviles, Apple no proporciona especificaciones de hardware detalladas para su SoC, el nombre comercial es ampliamente utilizado por los medios y es difícil deducir cuál es el impacto exacto de una característica de hardware específica y ajustar el rendimiento de la implementación. .
Estamos utilizando el lenguaje de programación Swift, específicamente Swift 4.2, que es el último hasta ahora; Marco Metal 2 y algunas funciones de biblioteca proporcionadas por Metal Performance Shader (Funciones de álgebra básicamente lineal). Aunque Apple lanzó CoreML SDK en la primavera de 2017 que incorporó cierto soporte para redes neuronales convolucionales, no los estamos usando en Corgy para obtener una experiencia invaluable en el desarrollo de la implementación paralelizada de las capas de red y proporcionar API concisas e intuitivas con buena usabilidad y una curva de aprendizaje fluida. para que los usuarios migren un modelo desde otros marcos sin esfuerzo.
Nuestras máquinas de destino son todos los dispositivos que ejecutan macOS e iOS, como iMac, MacBook, iPhone y iPad. Específicamente, el dispositivo con una plataforma que admite la biblioteca de álgebra lineal MPS (es decir, después de iOS 10.0 y macOS 10.13), lo que significa que el iPhone se lanzó después del iPhone 5, el iPad se lanzó después del iPad (cuarta generación) y el iPod Touch (sexta generación). son compatibles con la plataforma iOS. La línea de productos Mac obtiene una cobertura aún más amplia, incluidos los iMac producidos después de finales de 2009 o más recientes, todas las series de MacBook lanzadas después de mediados de 2010 y el iMac Pro.
La abstracción paralela de Metal 2 es muy parecida a CUDA: al enviar el pase de la computadora a la GPU, los programadores primero escribirán funciones del kernel que serán ejecutadas por cada subproceso, luego especificarán el número de grupo de subprocesos (también conocido como bloque en CUDA) en la cuadrícula y cantidad de subprocesos en cada grupo de subprocesos, Metal ejecutará núcleos sobre esta cuadrícula, el núcleo se implementa en un dialecto C++ 14 llamado lenguaje de sombreado Metal. Dentro de cada grupo de subprocesos, existe una unidad más pequeña llamada grupo SIMD, es decir, un conjunto de subprocesos que comparten las mismas instrucciones SIMD. Pero según nuestra implementación, no es necesario considerar esto.
Metal proporciona una API llamada MTLCommandBuffer que almacena comandos codificados que la GPU confirma y ejecuta. Cada vez que queremos iniciar una tarea para que la realice la GPU, las funciones del kernel precompiladas se codificarán en instrucciones de la GPU, se integrarán en la canalización de sombreado de Metal y se enviarán a MTLCommandBuffer. En esta etapa también se configura el búfer metálico utilizado para almacenar el parámetro de cálculo que debe pasarse al dispositivo. Luego, con un número específico de grupos de subprocesos y subprocesos por grupo, el comando manejado por el búfer de comandos estaría completamente codificado y listo para enviarse al dispositivo. La GPU programará la tarea y notificará al subproceso de la CPU que envía el trabajo una vez finalizada la ejecución.
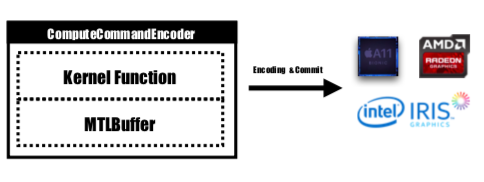
La función del kernel estará codificada por MTLComputeCommandEncoder y la tarea se creará para todas las plataformas compatibles.
En nuestra implementación, utilizamos ampliamente una forma intuitiva de asignar el elemento a subprocesos de GPU: asignar cada elemento en el tensor de salida de la capa actual a un subproceso de GPU: cada subproceso calcula y actualiza exactamente un elemento de la salida, y la entrada será es de solo lectura, por lo que no necesitamos preocuparnos por la sincronización entre subprocesos. Según este mapeo, los subprocesos con identificadores continuos pueden leer datos de entrada desde diferentes ubicaciones de memoria, pero siempre escribirán en ubicaciones de memoria continua. Por lo tanto, no habrá operaciones de dispersión cuando un grupo SIMD esté escribiendo en la memoria.
Diseñamos una Variable de clase tensorial como base de toda la implementación, utilizamos y encapsulamos la operación de álgebra lineal en la clase Variable en lugar de escribir un núcleo adicional para profundizar en la operación que no es nuestro enfoque principal para reducir la complejidad de la implementación. y ahorrarnos tiempo para centrarnos en acelerar las capas de la red.
1. Cambie la convolución a la multiplicación de matrices gigantes
Recopilamos los datos de la entrada de forma paralelizada para formar una matriz gigante tanto de la variable de entrada como del peso. Guardamos en caché el peso de cada capa convolucional para evitar volver a calcularlo. El relleno de la capa convolucional se generaría durante la transformación de paralelización durante el cálculo, luego invocamos MPSMatrixMultiply a la matriz gigante y transformamos los datos de la matriz gigante nuevamente a la clase de tensor normal que creamos. El método se describe en las diapositivas de clase.
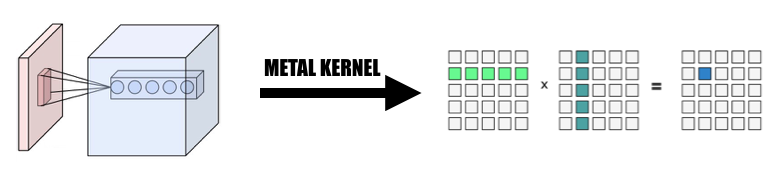
2. El diseño e implementación de la clase Variable.
La clase variable es la base de nuestra implementación como representación tensorial. Encapsulamos MPSMatrixMultiplication para la variable (definimos el signo de multiplicación Unicode (×) como un operador infijo para representarlo elegantemente :-)).
La estructura de datos subyacente de la variable es un UnsafemutableBufferPointer que apunta al tipo de datos; elegimos el flotante de 32 bits por simplicidad. La clase Variable mantuvo dos tamaños de datos, el count contenía el número de elemento que realmente se almacenó, el actualCount es el tamaño de todos los elementos redondeados al tamaño de página de la plataforma obtenido usando getpagesize() .
Mantenemos estos dos valores para asegurarnos de que makeBuffer(bytesNoCopy:) cree el búfer directamente en la región de VM especificada y evite la reasignación redundante que reduce la sobrecarga. Si la memoria que se pasará a Metal no está alineada con la página, Metal no podrá usar esta memoria como búfer de entrada o salida. Tendremos que usar el método makeBuffer(bytes:) , que creará un nuevo búfer y copiará datos desde la ubicación de la memoria de entrada. Por lo tanto, siempre debemos asignar más memoria de la necesaria para asegurarnos de que todas las memorias en Variable estén alineadas con las páginas. Por lo tanto, necesitamos dos valores para realizar un seguimiento de qué tan grande es exactamente esta porción de memoria y qué tan grande debemos usar.
3. Número de elementos procesados por un solo hilo.
Intentamos asignar un hilo a varios elementos, de 2 a 16 elementos por hilo, el rendimiento es casi el mismo pero se agrega mucha complejidad a nuestro proyecto, por lo que descartamos este enfoque.
Todas las versiones de CPU que se mencionan a continuación son códigos de CPU ingenuos de un solo subproceso sin optimización SIMD. Se aplica la optimización del compilador en el nivel -Ofast .
El rendimiento de nuestra implementación es bueno, pero no lo suficientemente bueno.
Aplicamos el iPhone 6s y una MacBook Pro de 15 pulgadas como plataforma de referencia. El hardware se especifica a continuación:
MacBook Pro (Retina de 15 pulgadas, mediados de 2015)
iPhone 6S
En comparación con la implementación ingenua de la versión de CPU sin paralelismo, nuestra versión de GPU es más de 60 veces más rápida .
Debido a que el modelo MNIST es demasiado pequeño, es posible que su resultado no refleje la aceleración precisa. Y no tenemos una versión de un solo subproceso bien implementada, no podemos dar un número de aceleración preciso. Debido a que la versión de la CPU es demasiado lenta, la aceleración en Tiny YOLO es demasiado grande para creerla.
Atributo de la red del experimento:
MNIST:
YOLO:
Resultado de la medición:
| iPhone 6s | MNIST | pequeño yolo |
|---|---|---|
| UPC | 1500ms | 753 |
| GPU | 0,025s | 0,5 s |
| acelerar | ~60x | ~1500x |
| macbook pro | MNIST | pequeño yolo |
|---|---|---|
| UPC | 650 ms | 729 |
| GPU | 10 ms | 0,028s |
| acelerar | ~65x | ~26000x |
Según el punto de referencia anterior, podemos ver que a medida que aumenta el tamaño del problema,
¿Por qué decimos que nuestra aceleración no es lo suficientemente buena? Porque en comparación con la implementación oficial de Apple de MPSCNNConvolution , somos solo un tercio más rápidos, lo que significa que todavía hay mucho espacio de optimización. Esta comparación se basa en una implementación de código abierto de YOLO en iPhone que utiliza MPSCNNConvolution oficial que puede reconocer ~5 imágenes por segundo, mientras que nuestra implementación solo puede lograr ~2 imágenes por segundo.
Y debido a un tiempo limitado, no pudimos crear una mejor versión de referencia y una versión paralela de CPU para realizar la prueba comparativa, lo que hace que el número de aceleración sea demasiado grande.
También vale la pena informar la ganancia de rendimiento en diferentes tamaños de problemas. Como podemos ver, MNIST tiene solo 0,1 millones de pesos mientras que Tiny YOLO tiene 17 millones. Tiny YOLO es mucho más complejo que MNIST, pero el tiempo de ejecución de la versión GPU no aumentó tanto. Esto se debe nuevamente a la ley de Amdahl. Cada vez que se inicia una tarea de GPU, los comandos de GPU correspondientes deben codificarse en el búfer de comandos. Este proceso es inherentemente serial. Cuando el tamaño del problema es pequeño, este proceso contribuye en gran medida al tiempo total de ejecución, por lo que al paralelizar la etapa de inferencia de la red neuronal en MINST puede no obtener la misma velocidad que en Tiny YOLO, donde la sobrecarga del tiempo de ejecución es insignificante.
¿Qué limitó tu aceleración?
if y for que pueden causar divergencias, lo que lleva a una mala utilización de SIMD.Análisis más profundo: desglose del tiempo de ejecución de las diferentes fases.
Tome Tiny YOLO como ejemplo, en una ejecución de muestra con un tiempo de ejecución total de 227 ms en Macbook, las capas convolucionales usaron 207 ms, el 92% del tiempo de ejecución total. Las capas de Pooling usaron 14 ms (6%) y ReLU usó 6 ms (2%). Según la ley de Amdahl, si queremos mejorar aún más el rendimiento, definitivamente debemos seguir trabajando en la capa convolucional.
En general, creemos que nuestra elección del marco metálico para realizar la aceleración de la red neuronal en dispositivos iOS y macOS es acertada, especialmente para dispositivos iOS. Dado que tiene menos núcleos, incluso con instrucciones SIMD, es menos probable que una versión de CPU bien ajustada obtenga un rendimiento similar al de la versión de GPU.
Ambos miembros del equipo realizan el mismo trabajo.
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


