Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript ?Browser sin cabezaWeb scraping de la mayoría de los sitios web puede ser comparativamente fácil. Este tema ya se trata en detalle en este tutorial. Sin embargo, hay muchos sitios que no se pueden eliminar con el mismo método. La razón es que estos sitios cargan el contenido dinámicamente usando JavaScript.
Esta técnica también se conoce como AJAX (JavaScript y XML asincrónicos). Históricamente, este estándar se incluía creando un objeto XMLHttpRequest para recuperar XML de un servidor web sin recargar toda la página. Hoy en día, este objeto rara vez se utiliza directamente. Por lo general, se utiliza un contenedor como jQuery para recuperar contenido como JSON, HTML parcial o incluso imágenes.
Para extraer una página web normal, se requieren al menos dos bibliotecas. La biblioteca requests descarga la página. Una vez que esta página esté disponible como una cadena HTML, el siguiente paso es analizarla como un objeto BeautifulSoup. Este objeto BeautifulSoup se puede utilizar para buscar datos específicos.
Aquí hay un script de ejemplo simple que imprime el texto dentro del elemento h1 con id establecida en firstHeading .
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert EinsteinTenga en cuenta que estamos trabajando con la versión 4 de la biblioteca Beautiful Soup. Las versiones anteriores están descontinuadas. Es posible que veas hermosa sopa 4 escrita simplemente como Beautiful Soup, BeautifulSoup o incluso bs4. Todos se refieren a la misma hermosa biblioteca de sopa 4.
El mismo código no funcionará si el sitio es dinámico. Por ejemplo, el mismo sitio tiene una versión dinámica en https://quotes.toscrape.com/js/ (tenga en cuenta js al final de esta URL).
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output La razón es que el segundo sitio es dinámico y los datos se generan utilizando JavaScript .
Hay dos formas de manejar sitios como este.
Estos dos enfoques se tratan detalladamente en este tutorial.
Sin embargo, primero debemos entender cómo determinar si un sitio es dinámico.
Esta es la forma más sencilla de determinar si un sitio web es dinámico usando Chrome o Edge. (Ambos navegadores usan Chromium internamente).
Abra Herramientas de desarrollador presionando la tecla F12 . Asegúrese de que el foco esté en las herramientas del desarrollador y presione la combinación de teclas CTRL+SHIFT+P para abrir el menú Comando.
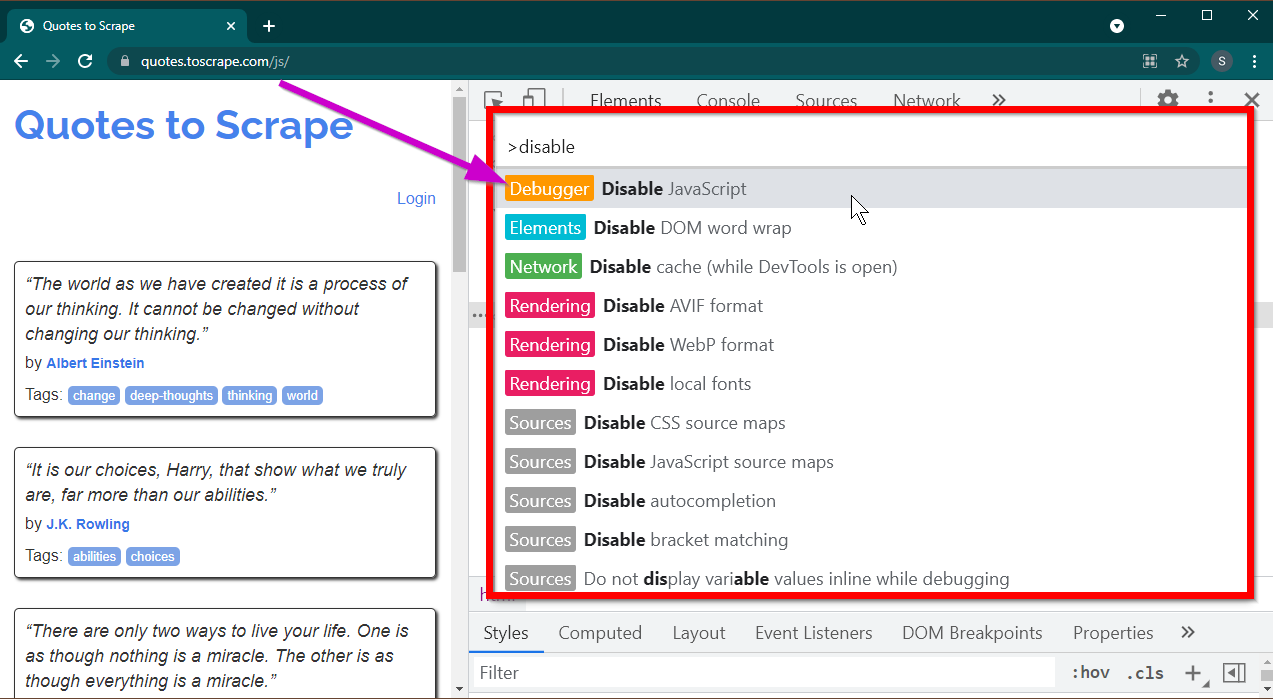
Mostrará muchos comandos. Comience a escribir disable y los comandos se filtrarán para mostrar Disable JavaScript . Seleccione esta opción para desactivar JavaScript .
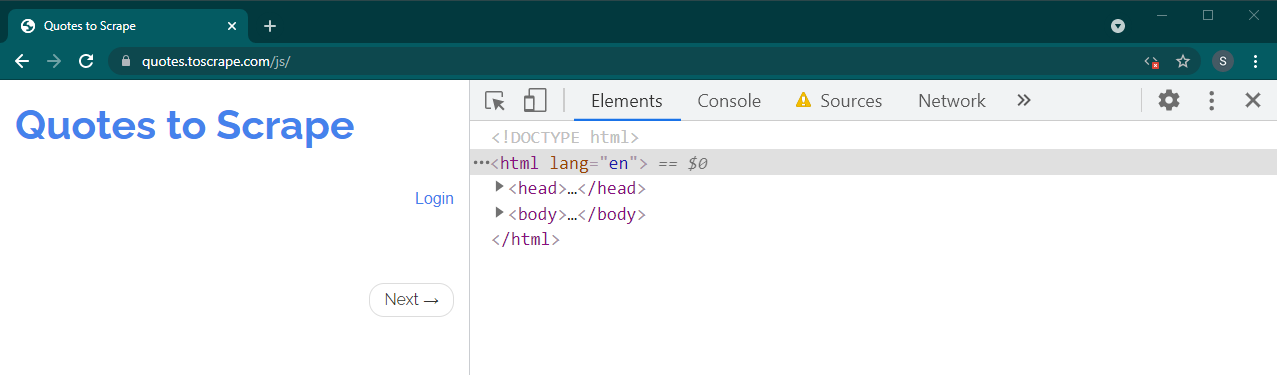
Ahora recarga esta página presionando Ctrl+R o F5 . La página se recargará.
Si se trata de un sitio dinámico, gran parte del contenido desaparecerá:
En algunos casos, los sitios seguirán mostrando los datos pero volverán a la funcionalidad básica. Por ejemplo, este sitio tiene un desplazamiento infinito. Si JavaScript está deshabilitado, muestra paginación normal.
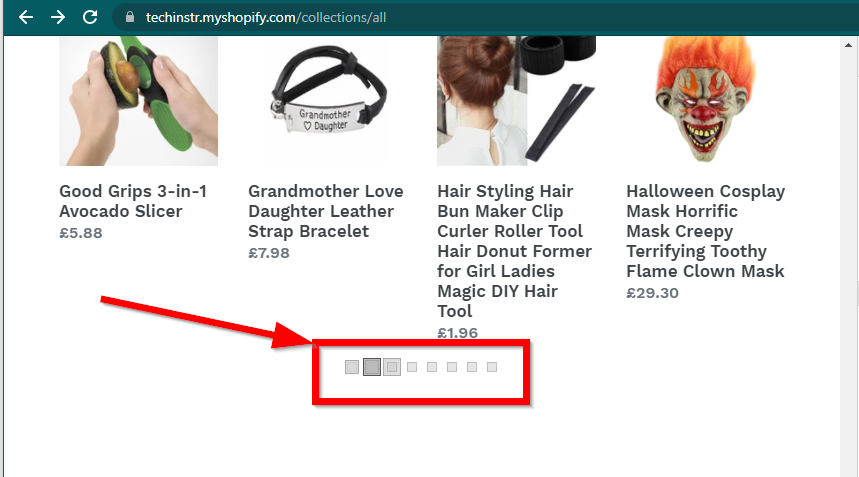 | 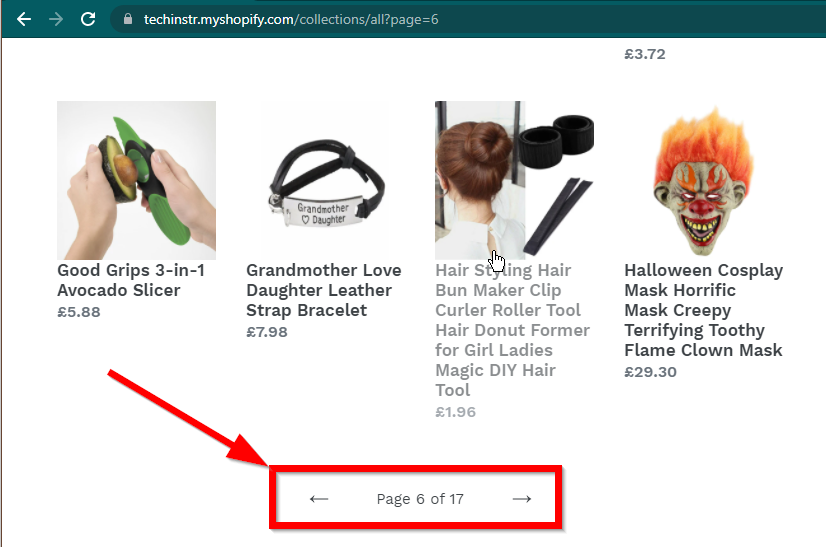 |
|---|---|
| JavaScript habilitado | JavaScript deshabilitado |
La siguiente pregunta que debe responderse son las capacidades de BeautifulSoup.
JavaScript ?La respuesta corta es no.
Es importante comprender palabras como análisis y representación. El análisis consiste simplemente en convertir una representación de cadena de un objeto de Python en un objeto real.
Entonces, ¿qué es el renderizado? El renderizado consiste esencialmente en interpretar HTML, JavaScript, CSS e imágenes en algo que vemos en el navegador.
Beautiful Soup es una biblioteca de Python para extraer datos de archivos HTML. Esto implica analizar una cadena HTML en el objeto BeautifulSoup. Para el análisis, primero necesitamos el HTML como cadena. Los sitios web dinámicos no tienen los datos directamente en HTML. Significa que BeautifulSoup no puede funcionar con sitios web dinámicos.
La biblioteca Selenium puede automatizar la carga y representación de sitios web en un navegador como Chrome o Firefox. Aunque Selenium admite la extracción de datos de HTML, es posible extraer HTML completo y utilizar Beautiful Soup para extraer los datos.
Comencemos primero con el web scraping dinámico con Python usando Selenium.
Instalar Selenium implica instalar tres cosas:
El navegador de tu elección (que ya tienes):
El controlador para su navegador:
Paquete de selenio de Python:
pip install seleniumconda-forge . conda install -c conda-forge selenium El esqueleto básico del script Python para iniciar un navegador, cargar la página y luego cerrar el navegador es simple:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()Ahora que podemos cargar la página en el navegador, veamos cómo extraer elementos específicos. Hay dos formas de extraer elementos: selenio y Beautiful Soup.
Nuestro objetivo en este ejemplo es encontrar el elemento de autor.
Cargue el sitio https://quotes.toscrape.com/js/ en Chrome, haga clic derecho en el nombre del autor y haga clic en Inspeccionar. Esto debería cargar Developer Tools con el elemento de autor resaltado de la siguiente manera:
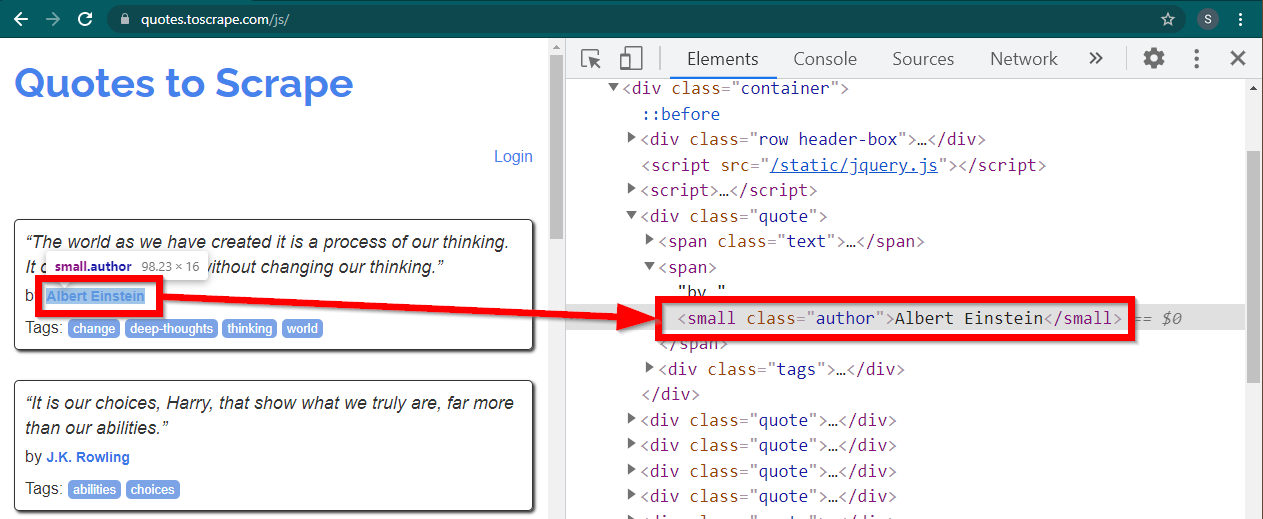
Este es un elemento small con su atributo class establecido en author .
< small class =" author " > Albert Einstein </ small >Selenium permite varios métodos para localizar los elementos HTML. Estos métodos son parte del objeto controlador. Algunos de los métodos que pueden resultar útiles aquí son los siguientes:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )Hay algunos otros métodos que pueden resultar útiles para otros escenarios. Estos métodos son los siguientes:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) Quizás los métodos más útiles sean find_element(By.CSS_SELECTOR) y find_element(By.XPATH) . Cualquiera de estos dos métodos debería poder seleccionar la mayoría de los escenarios.
Modifiquemos el código para que se pueda imprimir el primer autor.
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()¿Qué pasa si quieres imprimir todos los autores?
Todos los métodos find_element tienen una contraparte: find_elements . Tenga en cuenta la pluralización. Para encontrar todos los autores, simplemente cambie una línea:
elements = driver . find_elements ( By . CLASS_NAME , "author" )Esto devuelve una lista de elementos. Simplemente podemos ejecutar un bucle para imprimir todos los autores:
for element in elements :
print ( element . text )Nota: El código completo está en el archivo de código selenium_example.py.
Sin embargo, si ya se siente cómodo con BeautifulSoup, puede crear el objeto Beautiful Soup.
Como vimos en el primer ejemplo, el objeto Beautiful Soup necesita HTML. Para sitios estáticos de raspado web, el HTML se puede recuperar utilizando la biblioteca requests . El siguiente paso es analizar esta cadena HTML en el objeto BeautifulSoup.
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )Descubramos cómo crear un sitio web dinámico con BeautifulSoup.
La siguiente parte permanece sin cambios con respecto al ejemplo anterior.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) El HTML renderizado de la página está disponible en el atributo page_source .
soup = BeautifulSoup ( driver . page_source , "lxml" )Una vez que el objeto de sopa esté disponible, todos los métodos de Beautiful Soup se pueden utilizar como de costumbre.
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )Nota: El código fuente completo está en selenium_bs4.py
Browser sin cabezaUna vez que el script esté listo, no es necesario que el navegador esté visible cuando se esté ejecutando el script. El navegador se puede ocultar y el script seguirá funcionando bien. Este comportamiento de un navegador también se conoce como navegador sin cabeza.
Para que el navegador sea autónomo, importe ChromeOptions . Para otros navegadores, están disponibles sus propias clases de Opciones.
from selenium . webdriver import ChromeOptions Ahora, cree un objeto de esta clase y establezca el atributo headless en Verdadero.
options = ChromeOptions ()
options . headless = TrueFinalmente, envíe este objeto mientras crea la instancia de Chrome.
driver = Chrome ( ChromeDriverManager (). install (), options = options )Ahora, cuando ejecute el script, el navegador no será visible. Consulte el archivo selenium_bs4_headless.py para ver la implementación completa.
Cargar el navegador es costoso: consume CPU, RAM y ancho de banda que realmente no son necesarios. Cuando se elimina un sitio web, lo importante son los datos. Todos esos CSS, imágenes y renderizados no son realmente necesarios.
La forma más rápida y eficiente de extraer páginas web dinámicas con Python es localizar el lugar real donde se encuentran los datos.
Hay dos lugares donde se pueden ubicar estos datos:
<script>Veamos algunos ejemplos.
Abra https://quotes.toscrape.com/js en Chrome. Una vez cargada la página, presione Ctrl+U para ver la fuente. Presione Ctrl+F para abrir el cuadro de búsqueda, busque Albert.
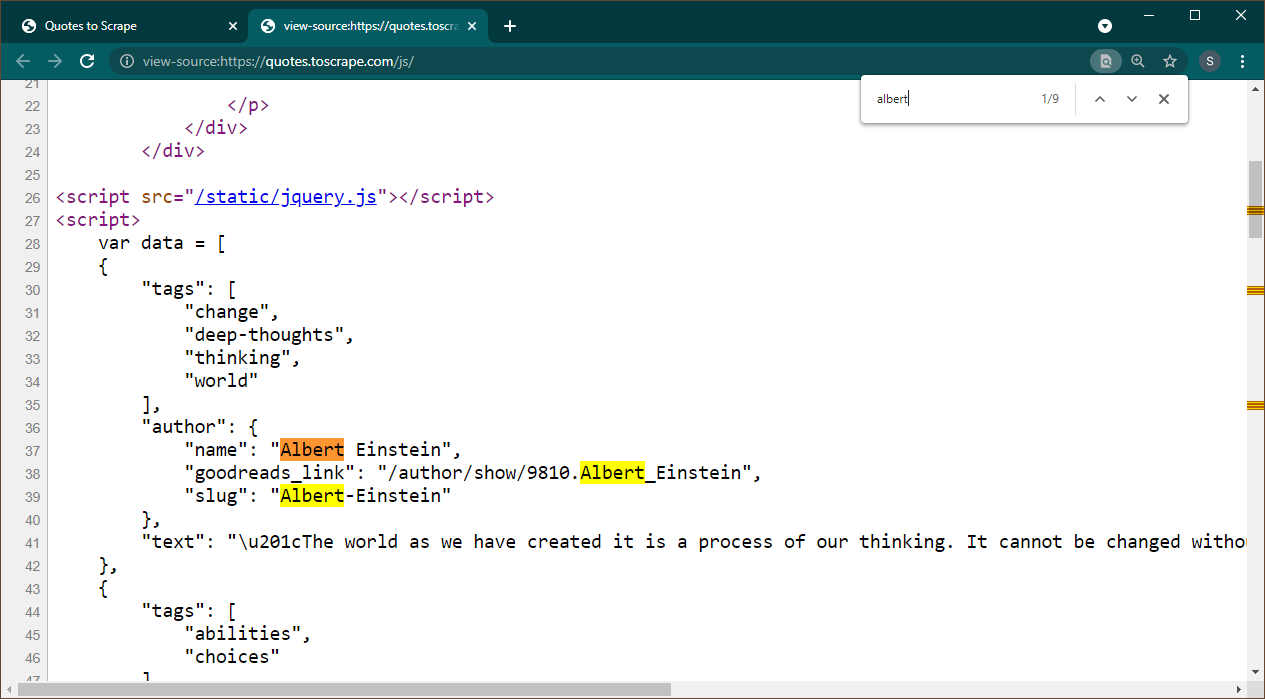
Podemos ver inmediatamente que los datos están incrustados como un objeto JSON en la página. Además, tenga en cuenta que esto es parte de un script donde estos datos se asignan a una variable data .
En este caso, podemos usar la biblioteca de Solicitudes para obtener la página y usar Beautiful Soup para analizar la página y obtener el elemento del script.
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) Tenga en cuenta que hay varios elementos <script> . El que contiene los datos que necesitamos no tiene atributo src . Usemos esto para extraer el elemento del script.
script_tag = soup . find ( "script" , src = None )Recuerda que este script contiene otro código JavaScript además de los datos que nos interesan. Por este motivo, vamos a utilizar una expresión regular para extraer estos datos.
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )La variable de datos es una lista que contiene un elemento. Ahora podemos usar la biblioteca JSON para convertir estos datos de cadena en un objeto de Python.
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )La salida será el objeto Python:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................Esta lista no se puede convertir a ningún formato según sea necesario. Además, tenga en cuenta que cada elemento contiene un enlace a la página del autor. Significa que puedes leer estos enlaces y crear una araña para obtener datos de todas estas páginas.
Este código completo está incluido en data_in_same_page.py.
Los sitios dinámicos de web scraping pueden seguir un camino completamente diferente. A veces, los datos se cargan en una página completamente separada. Un ejemplo de ello es Librivox.
Abra Herramientas de desarrollo, vaya a la pestaña Red y filtre por XHR. Ahora abra este enlace o busque cualquier libro. Verás que los datos son un HTML incrustado en JSON.
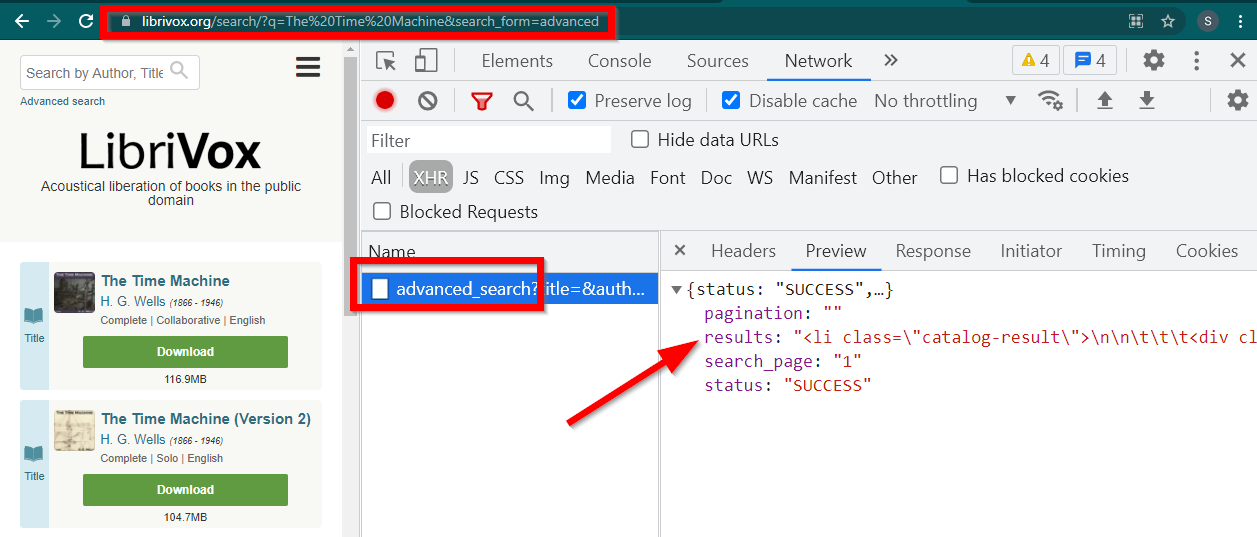
Tenga en cuenta algunas cosas:
La URL que muestra el navegador es https://librivox.org/search/?q=...
Los datos están en https://librivox.org/advanced_search?....
Si observa los encabezados, encontrará que a la página de búsqueda avanzada se le envía un encabezado especial X-Requested-With: XMLHttpRequest
Aquí hay un fragmento para extraer estos datos:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )El código completo se incluye en el archivo librivox.py.


