disclosure backend static
1.0.0
El repositorio disclosure-backend-static es el backend que impulsa Open Disclosure California.
Fue creado apresuradamente en vísperas de las elecciones de 2016 y, por lo tanto, está diseñado en torno a una filosofía de "hazlo". En ese momento, ya habíamos diseñado una API y construido (la mayor parte) una interfaz; Este repositorio fue creado para implementarlos lo más rápido posible.
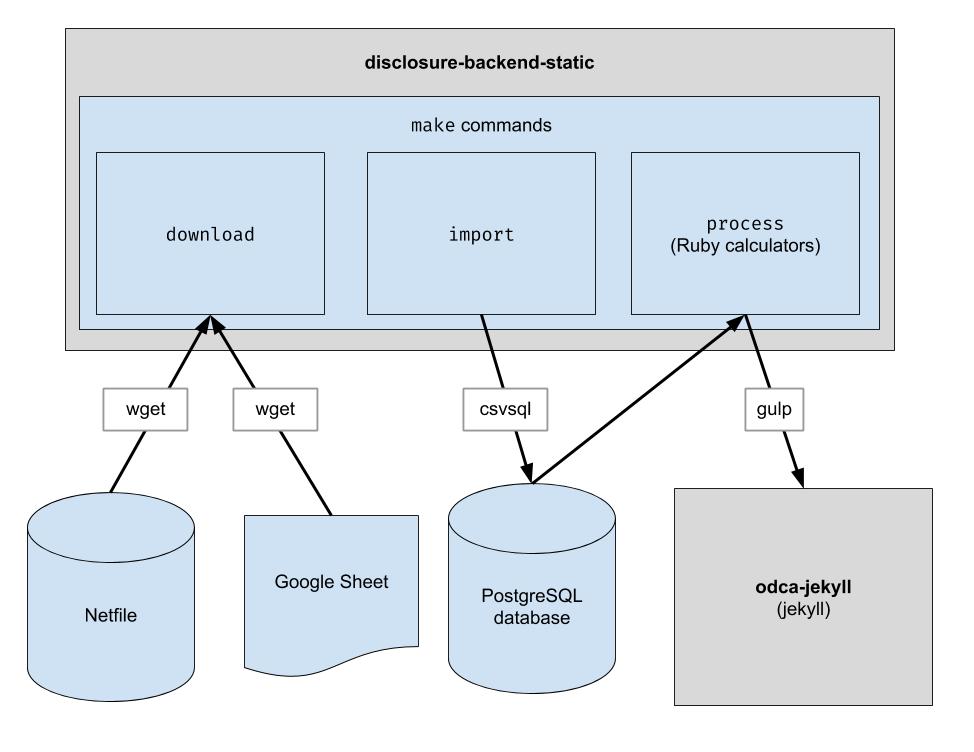
Este proyecto implementa una canalización ETL básica para descargar los datos netfile de Oakland, descargar los datos CSV seleccionados por humanos para Oakland y combinar los dos. El resultado es un directorio de archivos JSON que imitan la estructura API existente, por lo que no será necesario realizar cambios en el código del cliente.
.ruby-version ) Nota: No es necesario ejecutar estos comandos para desarrollar en la interfaz. Todo lo que necesita hacer es clonar el repositorio adyacente al repositorio frontend.
Si planea modificar el código backend, siga estos pasos para configurar todas las dependencias de desarrollo necesarias, incluida una nueva base de datos PostgreSQL y Python 3:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip en lugar de pip para asegurarse de que se use Python 3: python3 -m pip install ...
pip de tu sistema apunta a Python 3, puedes usar pip directamente: pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
Este repositorio está configurado para funcionar en un contenedor en Codespaces. En otras palabras, puede iniciar un entorno que ya esté configurado sin tener que realizar ninguno de los pasos de instalación necesarios para configurar un entorno local. Esto se puede utilizar como una forma de solucionar problemas de código antes de enviarlo al proceso de producción. La siguiente información puede resultar útil para empezar a utilizar Codespaces:
Code y haga clic en la pestaña Codespaces en el menú desplegable/workspace en la página web, que le resultará familiar si ha trabajado con VS Code antes.make downloadpsql en la terminal para conectarse al servidor.make import llenará la base de datos de Postgresgit pushEste repositorio también está configurado para ejecutarse dentro de un contenedor Docker. Esto es similar a Codespaces excepto que puedes usar cualquier IDE y configuración local que prefieras. A continuación se explica cómo empezar a utilizar Docker con VSCode:
Descargue los archivos de datos sin procesar. Sólo necesita ejecutar esto de vez en cuando para obtener los datos más recientes.
$ make download
Importe los datos a la base de datos para facilitar su procesamiento. Solo necesita ejecutar esto después de haber descargado nuevos datos.
$ make import
Ejecute las calculadoras. Todo se envía a la carpeta "compilación".
$ make process
Opcionalmente, reindexe los resultados de la compilación en Algolia. (La reindexación requiere las variables de entorno ALGOLIASEARCH_APPLICATION_ID y ALGOLIASEARCH_API_KEY).
$ make reindex
Si desea servir los archivos JSON estáticos a través de un servidor web local:
$ make run
Cuando se ejecuta make import , se crean varias tablas de Postgres para importar los datos descargados. El esquema de estas tablas se define explícitamente en el directorio dbschema y es posible que deba actualizarse en el futuro para dar cabida a datos futuros. Es posible que las columnas que contienen datos de cadenas no tengan un tamaño lo suficientemente grande para datos futuros. Por ejemplo, si una columna de nombre acepta nombres de como máximo 20 caracteres y en el futuro tenemos datos donde el nombre tiene 21 caracteres, la importación de datos fallará. Cuando esto ocurra, tendremos que actualizar el archivo de esquema correspondiente en dbschema para admitir más caracteres. Simplemente haga el cambio y vuelva a ejecutar make import para verificar que se realice correctamente.
Este repositorio se utiliza para generar archivos de datos que utiliza el sitio web. Después de ejecutar make process , se genera un directorio build que contiene los archivos de datos. Este directorio se registra en el repositorio y luego se retira al generar el sitio web. Después de realizar cambios en el código, es importante comparar el directorio build generado con el directorio build generado antes de que cambie el código y verificar que los cambios del código sean los esperados.
Debido a que una comparación estricta de todo el contenido del directorio build siempre incluirá cambios que ocurren independientemente de cualquier cambio de código, cada desarrollador debe conocer estos cambios esperados para poder realizar esta verificación. Para eliminar la necesidad de esto, un archivo específico, bin/create-digests.py , genera resúmenes de datos JSON en el directorio build después de excluir estos cambios esperados. Para buscar cambios que excluyan estos cambios esperados, simplemente busque un cambio en el archivo build/digests.json .
Actualmente, estos son los cambios esperados que ocurren independientemente de cualquier cambio de código:
Los cambios esperados se excluyen antes de generar resúmenes de datos en el directorio build . La lógica para esto se puede encontrar en la función clean_data , que se encuentra en el archivo bin/create-digests.py . Después de modificar el código de modo que ya no exista un cambio esperado, la exclusión de ese cambio se puede eliminar de clean_data . Por ejemplo, el redondeo de los flotadores no es siempre el mismo cada vez que se ejecuta make process , debido a diferencias en el entorno. Cuando el código se corrige para que el redondeo de los flotantes sea el mismo siempre que los datos no hayan cambiado, se puede eliminar la llamada round_float en clean_data .
Se ha creado un script adicional para generar un informe que permite comparar los totales de los candidatos. El script es bin/report-candidates.py y genera build/candidates.csv y build/candidates.xlsx . Los informes incluyen una lista de todos los candidatos y totales calculados de varias maneras que deberían sumar el mismo número.
Para garantizar que los cambios en el esquema de la base de datos sean visibles en las solicitudes de extracción, el esquema postgres completo también se guarda en un archivo schema.sql en el directorio build . Debido a que el directorio build se reconstruye automáticamente para cada rama en un PR y se confirma en el repositorio, cualquier cambio en el esquema causado por un cambio de código se mostrará como una diferencia en el archivo schema.sql al revisar el PR.
Cada métrica sobre un candidato se calcula de forma independiente. Una métrica podría ser algo como "contribuciones totales recibidas" o algo más complejo como "porcentaje de contribuciones que son inferiores a $100".
Al agregar un nuevo cálculo, un buen primer lugar para comenzar es el Formulario 460 oficial. ¿Los datos que busca se informan en ese formulario? Si es así, probablemente lo encontrarás en tu base de datos después del proceso de importación. También hay un par de formularios más que importamos, como el Formulario 496. (Estos son los nombres de los archivos en el directorio input . Compruébelos).
Cada cronograma de cada formulario se importa a una tabla de Postgres separada. Por ejemplo, el Anexo A del Formulario 460 se importa a la tabla A-Contributions .
Ahora que tiene una forma de consultar los datos, debe crear una consulta SQL que calcule el valor que intenta obtener. Una vez que pueda expresar su cálculo como SQL, colóquelo en un archivo de calculadora así:
calculators/[your_thing]_calculator.rb # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID .candidate.save_calculation . Ese método serializará su segundo argumento como JSON, por lo que puede almacenar cualquier tipo de datos.candidate.calculation(:your_thing) . Querrá agregar esto a una respuesta API en el archivo process.rb . Así es como los datos fluyen por el back-end. Los datos financieros se extraen de Netfile, que se complementa con una hoja de Google que asigna ID de archivador a información de la boleta electoral, como nombres de candidatos, cargos, medidas electorales, etc. Una vez que los datos se filtran, agregan y transforman, la interfaz los consume y crea el HTML estático. Interfaz.
Durante la instalación del paquete
error: use of undeclared identifier 'LZMA_OK'
Intentar:
brew unlink xz
bundle install
brew link xz
Durante make download
wget: command not found
Ejecute brew install wget .
Durante make import
Parece que hay un problema en los sistemas Macintosh que utilizan los chips Apple.
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
Pruebe lo siguiente:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


