phenaki pytorch
0.5.0
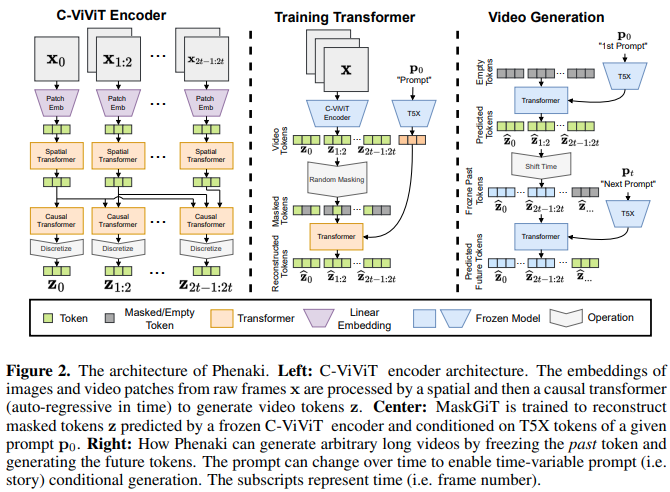
Implementación de Phenaki Video, que utiliza Mask GIT para producir videos guiados por texto de hasta 2 minutos de duración, en Pytorch. También combinará otra técnica que implica una crítica simbólica para generaciones potencialmente incluso mejores.
Únase si está interesado en replicar este trabajo al aire libre.
Explicación de la pausa para el café con IA
Stability.ai por el generoso patrocinio para trabajar en investigaciones de vanguardia en inteligencia artificial
? Huggingface por sus increíbles transformadores y biblioteca de aceleración.
Guillem por sus continuas aportaciones.
¿Tú? Si eres un gran ingeniero y/o investigador de aprendizaje automático, no dudes en contribuir a la frontera de la IA generativa de código abierto.
$ pip install phenaki-pytorchC-ViViT
import torch
from phenaki_pytorch import CViViT , CViViTTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
). cuda ()
trainer = CViViTTrainer (
cvivit ,
folder = '/path/to/images/or/videos' ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = False , # you can train on images first, before fine tuning on video, for sample efficiency
use_ema = False , # recommended to be turned on (keeps exponential moving averaged cvivit) unless if you don't have enough resources
num_train_steps = 10000
)
trainer . train () # reconstructions and checkpoints will be saved periodically to ./resultsFenaki
import torch
from phenaki_pytorch import CViViT , MaskGit , Phenaki
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = ( 256 , 128 ), # video with rectangular screen allowed
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
videos = torch . randn ( 3 , 3 , 17 , 256 , 128 ). cuda () # (batch, channels, frames, height, width)
mask = torch . ones (( 3 , 17 )). bool (). cuda () # [optional] (batch, frames) - allows for co-training videos of different lengths as well as video and images in the same batch
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = phenaki ( videos , texts = texts , video_frame_mask = mask )
loss . backward ()
# do the above for many steps, then ...
video = phenaki . sample ( texts = 'a squirrel examines an acorn' , num_frames = 17 , cond_scale = 5. ) # (1, 3, 17, 256, 128)
# so in the paper, they do not really achieve 2 minutes of coherent video
# at each new scene with new text conditioning, they condition on the previous K frames
# you can easily achieve this with this framework as so
video_prime = video [:, :, - 3 :] # (1, 3, 3, 256, 128) # say K = 3
video_next = phenaki . sample ( texts = 'a cat watches the squirrel from afar' , prime_frames = video_prime , num_frames = 14 ) # (1, 3, 14, 256, 128)
# the total video
entire_video = torch . cat (( video , video_next ), dim = 2 ) # (1, 3, 17 + 14, 256, 128)
# and so on... O simplemente importe la función make_video
# ... above code
from phenaki_pytorch import make_video
entire_video , scenes = make_video ( phenaki , texts = [
'a squirrel examines an acorn buried in the snow' ,
'a cat watches the squirrel from a frosted window sill' ,
'zoom out to show the entire living room, with the cat residing by the window sill'
], num_frames = ( 17 , 14 , 14 ), prime_lengths = ( 5 , 5 ))
entire_video . shape # (1, 3, 17 + 14 + 14 = 45, 256, 256)
# scenes - List[Tensor[3]] - video segment of each scene¡Eso es todo!
Un nuevo artículo sugiere que en lugar de confiar en las probabilidades predichas de cada token como medida de confianza, se puede entrenar a un crítico adicional para que decida qué enmascarar iterativamente durante el muestreo. Opcionalmente, puedes entrenar a este crítico para generaciones potencialmente mejores como se muestra a continuación.
import torch
from phenaki_pytorch import CViViT , MaskGit , TokenCritic , Phenaki
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = ( 256 , 128 ),
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
maskgit = MaskGit (
num_tokens = 65536 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
)
# (1) define the critic
critic = TokenCritic (
num_tokens = 65536 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
has_cross_attn = True
)
trainer = Phenaki (
maskgit = maskgit ,
cvivit = cvivit ,
critic = critic # and then (2) pass it into Phenaki
). cuda ()
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
videos = torch . randn ( 3 , 3 , 3 , 256 , 128 ). cuda () # (batch, channels, frames, height, width)
loss = trainer ( videos = videos , texts = texts )
loss . backward () O incluso más simple, simplemente reutilice MaskGit como autocrítico (Nijkamp et al), estableciendo self_token_critic = True en la inicialización de Phenaki
phenaki = Phenaki (
...,
self_token_critic = True # set this to True
)¡Ahora vuestras generaciones deberían mejorar mucho!
Este repositorio también se esforzará por permitir al investigador capacitarse en texto a imagen y luego texto a video. De manera similar, para una capacitación incondicional, el investigador debe poder entrenar primero con imágenes y luego realizar ajustes en video. A continuación se muestra un ejemplo de texto a vídeo.
import torch
from torch . utils . data import Dataset
from phenaki_pytorch import CViViT , MaskGit , Phenaki , PhenakiTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
unconditional = False
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
# mock text video dataset
# you will have to extend your own, and return the (<video tensor>, <caption>) tuple
class MockTextVideoDataset ( Dataset ):
def __init__ (
self ,
length = 100 ,
image_size = 256 ,
num_frames = 17
):
super (). __init__ ()
self . num_frames = num_frames
self . image_size = image_size
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
video = torch . randn ( 3 , self . num_frames , self . image_size , self . image_size )
caption = 'video caption'
return video , caption
dataset = MockTextVideoDataset ()
# pass in the dataset
trainer = PhenakiTrainer (
phenaki = phenaki ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = False , # if your mock dataset above return (images, caption) pairs, set this to True
dataset = dataset , # pass in your dataset here
sample_texts_file_path = '/path/to/captions.txt' # each caption should be on a new line, during sampling, will be randomly drawn
)
trainer . train ()Incondicional es el siguiente
ex. Imágenes incondicionales y entrenamiento en video.
import torch
from phenaki_pytorch import CViViT , MaskGit , Phenaki , PhenakiTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
unconditional = False
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
# pass in the folder to images or video
trainer = PhenakiTrainer (
phenaki = phenaki ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = True , # for sake of example, bottom is folder of images
dataset = '/path/to/images/or/video'
)
trainer . train ()pase la probabilidad de la máscara a maskgit y auto-mask y obtenga la pérdida de entropía cruzada
atención cruzada + obtenga código de incrustaciones t5 de imagen-pytorch y obtenga guía gratuita del clasificador conectado
conecte vqgan-vae completo para c-vivit, simplemente tome lo que ya está en parti-pytorch, pero asegúrese de usar un discriminador stylegan como se dice en el documento
código completo de entrenamiento de críticos de tokens
completar el primer paso del muestreo programado de Maskgit + crítico de token (opcionalmente sin él si el investigador no desea realizar capacitación adicional)
código de inferencia que permite deslizar el tiempo + condicionamiento en K fotogramas pasados
coartada pos sesgo para la atención temporal
dar a la atención espacial el sesgo posicional más poderoso
asegúrese de utilizar el discriminador stylegan-esque
Sesgo posicional relativo 3D para Maskgit
asegúrese de que maskgit también pueda admitir el entrenamiento de imágenes y asegúrese de que funcione en la máquina local
También cree una opción para que el crítico simbólico esté condicionado con el texto.
Debería poder entrenar primero para la generación de texto a imagen.
asegúrese de que el entrenador de críticos pueda aceptar cvivit y pasar automáticamente la forma del parche de video para un sesgo posicional relativo; asegúrese de que el crítico también obtenga un sesgo posicional relativo óptimo
código de entrenamiento para cvivit
mover cvivit a su propio archivo
generaciones incondicionales (tanto vídeo como imágenes)
conecte la aceleración para el entrenamiento con múltiples GPU tanto para c-vivit como para maskgit
agregue convs en profundidad a cvivit para generar posición
algún código básico de manipulación de video, permite guardar el tensor muestreado como gif
código básico de entrenamiento crítico
agregue posición generando dsconv a maskgit también
equipar bloques de atención personal personalizables para el discriminador stylegan
Agregue toda la investigación de vanguardia para la capacitación en estabilización de transformadores.
obtener un código de muestreo crítico básico, mostrar una comparación con y sin crítico
introducir un cambio de token concatenativo (dimensión temporal)
agregue un muestreador DDPM, ya sea un puerto de imagen-pytorch o simplemente reescriba una versión simple aquí
cuidar el enmascaramiento en maskgit
prueba maskgit + crítico solo en el conjunto de datos de flores de Oxford
admite vídeos de tamaño rectangular
agregue atención flash como opción para todos los transformadores y cite a @tridao
@article { Villegas2022PhenakiVL ,
title = { Phenaki: Variable Length Video Generation From Open Domain Textual Description } ,
author = { Ruben Villegas and Mohammad Babaeizadeh and Pieter-Jan Kindermans and Hernan Moraldo and Han Zhang and Mohammad Taghi Saffar and Santiago Castro and Julius Kunze and D. Erhan } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02399 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { press2021ALiBi ,
title = { Train Short, Test Long: Attention with Linear Biases Enable Input Length Extrapolation } ,
author = { Ofir Press and Noah A. Smith and Mike Lewis } ,
year = { 2021 } ,
url = { https://ofir.io/train_short_test_long.pdf }
} @article { Liu2022SwinTV ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11999-12009 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

