feathr
v1.0.0

Feathr es una plataforma de ingeniería de datos e inteligencia artificial que se utiliza ampliamente en la producción en LinkedIn durante muchos años y fue de código abierto en 2022. Actualmente es un proyecto de LF AI & Data Foundation.
Lea nuestro anuncio sobre Open Sourcing Feathr y Feathr en Azure, así como el anuncio de LF AI & Data Foundation.
Feather te permite:
Feathr es particularmente útil en el modelado de IA, donde calcula automáticamente las transformaciones de sus características y las une a sus datos de entrenamiento, utilizando una semántica correcta en un momento dado para evitar la fuga de datos, y admite la materialización e implementación de sus características para su uso en línea en producción.
La forma más sencilla de probar Feathr es utilizar Feathr Sandbox, que es un contenedor autónomo con la mayoría de las capacidades de Feathr y debería ser productivo en 5 minutos. Para usarlo, simplemente ejecute este comando:
# 80: Feathr UI, 8888: Jupyter, 7080: Interpret
docker run -it --rm -p 8888:8888 -p 8081:80 -p 7080:7080 -e GRANT_SUDO=yes feathrfeaturestore/feathr-sandbox:releases-v1.0.0Y puede ver el cuaderno jupyter de inicio rápido de Feathr:
http://localhost:8888/lab/workspaces/auto-w/tree/local_quickstart_notebook.ipynbDespués de ejecutar la computadora portátil, todas las funciones se registrarán en la interfaz de usuario y podrá visitar la interfaz de usuario de Feathr en:
http://localhost:8081Si desea instalar el cliente Feathr en un entorno Python, utilice esto:
pip install feathrO utilice el código más reciente de GitHub:
pip install git+https://github.com/feathr-ai/feathr.git#subdirectory=feathr_projectFeathr tiene integraciones nativas con Databricks y Azure Synapse:
Siga la guía de implementación de Feathr ARM para ejecutar Feathr en Azure. Esto le permite comenzar rápidamente con la implementación automatizada utilizando la plantilla de Azure Resource Manager.
Si desea configurar todo manualmente, puede consultar la guía de implementación de Feathr CLI para ejecutar Feathr en Azure. Esto le permite comprender lo que está sucediendo y configurar un recurso a la vez.
| Nombre | Descripción | Plataforma |
|---|---|---|
| Demostración de taxi en Nueva York | Cuaderno de inicio rápido que muestra cómo definir, materializar y registrar funciones con datos de muestra de predicción de tarifas de taxi de Nueva York. | Azure Synapse, ladrillos de datos, chispa local |
| Demostración de taxi de inicio rápido de Databricks en Nueva York | Cuaderno Quickstart Databricks con datos de ejemplo de predicción de tarifas de taxi en Nueva York. | Ladrillos de datos |
| Incrustación de características | Ejemplo de Feathr UDF que muestra cómo definir y utilizar la incorporación de funciones con un modelo Transformer previamente entrenado y datos de muestra de reseñas de hoteles. | Ladrillos de datos |
| Demostración de detección de fraude | Un ejemplo para demostrar Feature Store utilizando múltiples fuentes de datos, como cuentas de usuario y datos de transacciones. | Azure Synapse, ladrillos de datos, chispa local |
| Demostración de recomendación de producto | Cuaderno de ejemplo de Feathr Feature Store con un escenario de recomendación de producto | Azure Synapse, ladrillos de datos, chispa local |
Lea Capacidades completas de Feathr para obtener más ejemplos. A continuación se muestran algunos seleccionados:
Feathr proporciona una interfaz de usuario intuitiva para que pueda buscar y explorar todas las funciones disponibles y sus linajes correspondientes.
Puede utilizar Feathr UI para buscar funciones, identificar fuentes de datos, realizar un seguimiento de los linajes de funciones y gestionar los controles de acceso. Vea la última demostración en vivo aquí para ver qué puede hacer Feathr UI por usted. Utilice una de las siguientes cuentas cuando se le solicite iniciar sesión:
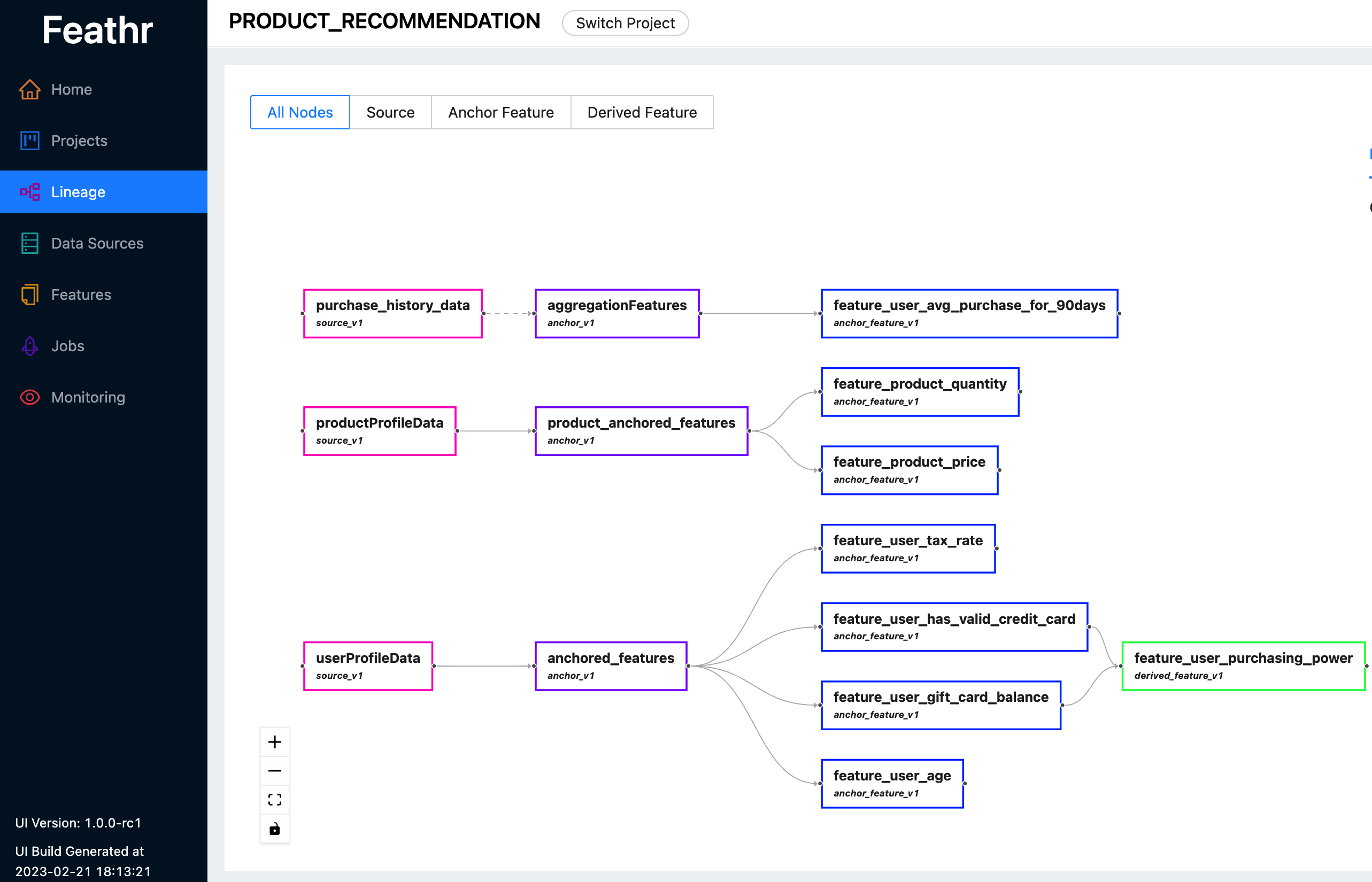
Para obtener más información sobre la interfaz de usuario de Feathr y el registro detrás de ella, consulte Registro de funciones de Feathr.
Feathr tiene UDF altamente personalizables con integración nativa de PySpark y Spark SQL para reducir la curva de aprendizaje de los científicos de datos:
def add_new_dropoff_and_fare_amount_column ( df : DataFrame ):
df = df . withColumn ( "f_day_of_week" , dayofweek ( "lpep_dropoff_datetime" ))
df = df . withColumn ( "fare_amount_cents" , df . fare_amount . cast ( 'double' ) * 100 )
return df
batch_source = HdfsSource ( name = "nycTaxiBatchSource" ,
path = "abfss://[email protected]/demo_data/green_tripdata_2020-04.csv" ,
preprocessing = add_new_dropoff_and_fare_amount_column ,
event_timestamp_column = "new_lpep_dropoff_datetime" ,
timestamp_format = "yyyy-MM-dd HH:mm:ss" ) agg_features = [ Feature ( name = "f_location_avg_fare" ,
key = location_id , # Query/join key of the feature(group)
feature_type = FLOAT ,
transform = WindowAggTransformation ( # Window Aggregation transformation
agg_expr = "cast_float(fare_amount)" ,
agg_func = "AVG" , # Apply average aggregation over the window
window = "90d" )), # Over a 90-day window
]
agg_anchor = FeatureAnchor ( name = "aggregationFeatures" ,
source = batch_source ,
features = agg_features ) # Compute a new feature(a.k.a. derived feature) on top of an existing feature
derived_feature = DerivedFeature ( name = "f_trip_time_distance" ,
feature_type = FLOAT ,
key = trip_key ,
input_features = [ f_trip_distance , f_trip_time_duration ],
transform = "f_trip_distance * f_trip_time_duration" )
# Another example to compute embedding similarity
user_embedding = Feature ( name = "user_embedding" , feature_type = DENSE_VECTOR , key = user_key )
item_embedding = Feature ( name = "item_embedding" , feature_type = DENSE_VECTOR , key = item_key )
user_item_similarity = DerivedFeature ( name = "user_item_similarity" ,
feature_type = FLOAT ,
key = [ user_key , item_key ],
input_features = [ user_embedding , item_embedding ],
transform = "cosine_similarity(user_embedding, item_embedding)" )Lea la Guía de ingesta de fuentes de streaming para obtener más detalles.
Lea Corrección en un momento determinado y Unirse a un momento determinado en Feathr para obtener más detalles.
Siga el inicio rápido de Jupyter Notebook para probarlo. También hay una guía de inicio rápido complementaria que contiene un poco más de explicación sobre el cuaderno.
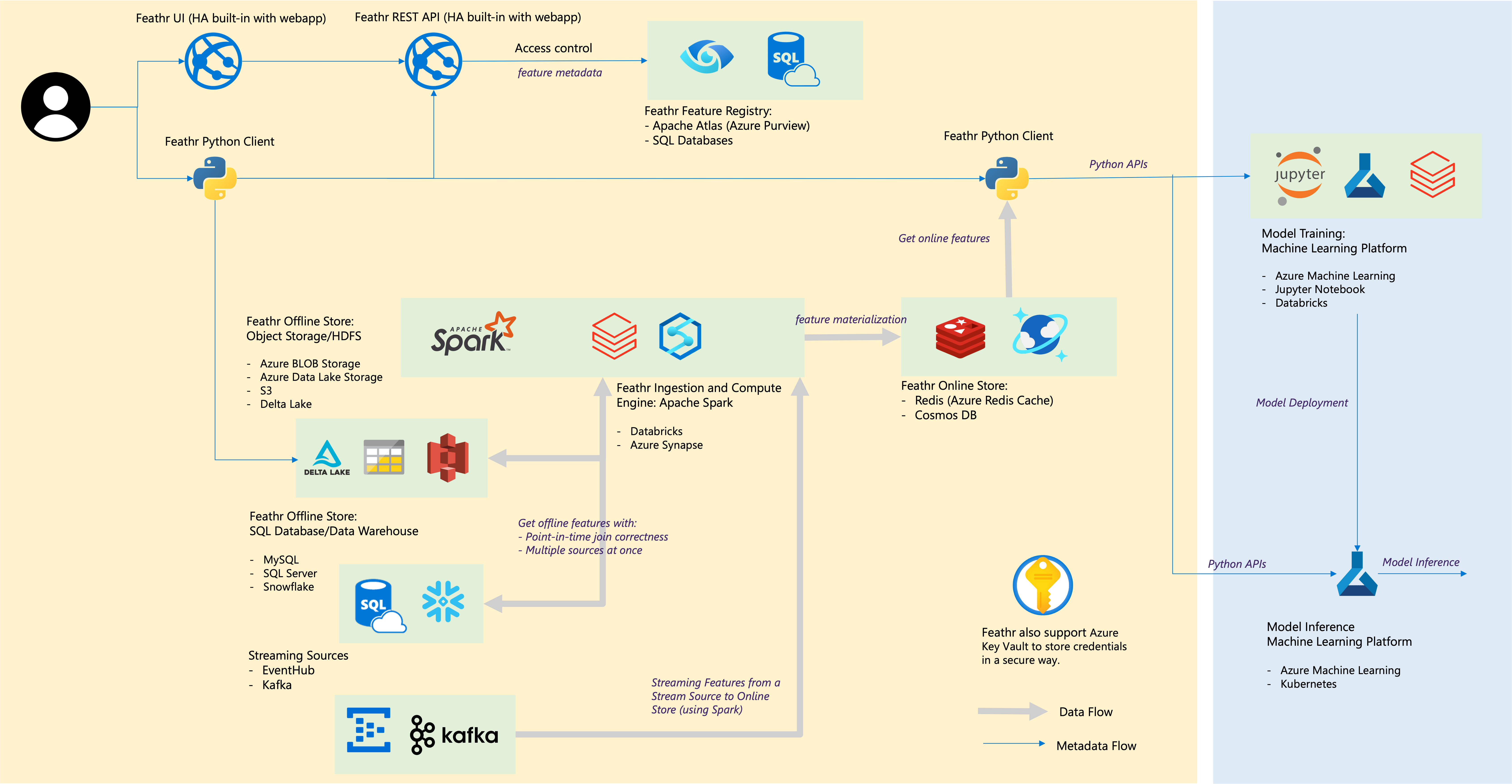
| Componente de plumas | Integraciones en la nube |
|---|---|
| Tienda fuera de línea – Tienda de objetos | Almacenamiento de blobs de Azure, Azure ADLS Gen2, AWS S3 |
| Tienda sin conexión – SQL | Azure SQL DB, grupos de SQL dedicados de Azure Synapse, Azure SQL en VM, Snowflake |
| Fuente de transmisión | Kafka, centro de eventos |
| tienda en línea | Redis, Azure Cosmos DB |
| Registro de funciones y gobernanza | Azure Purview, ANSI SQL como Azure SQL Server |
| Motor de Computación | Grupos de Spark de Azure Synapse y ladrillos de datos |
| Plataforma de aprendizaje automático | Azure Machine Learning, Jupyter Notebook, Databricks Notebook |
| Formato de archivo | Parquet, ORC, Avro, JSON, Delta Lake, CSV |
| Cartas credenciales | Bóveda de claves de Azure |
Construir para la comunidad y construir por la comunidad. Consulta las normas de la comunidad.
Únase a nuestro canal de Slack para preguntas y debates (o haga clic en el enlace de invitación).


