imagen pytorch
2.1.0
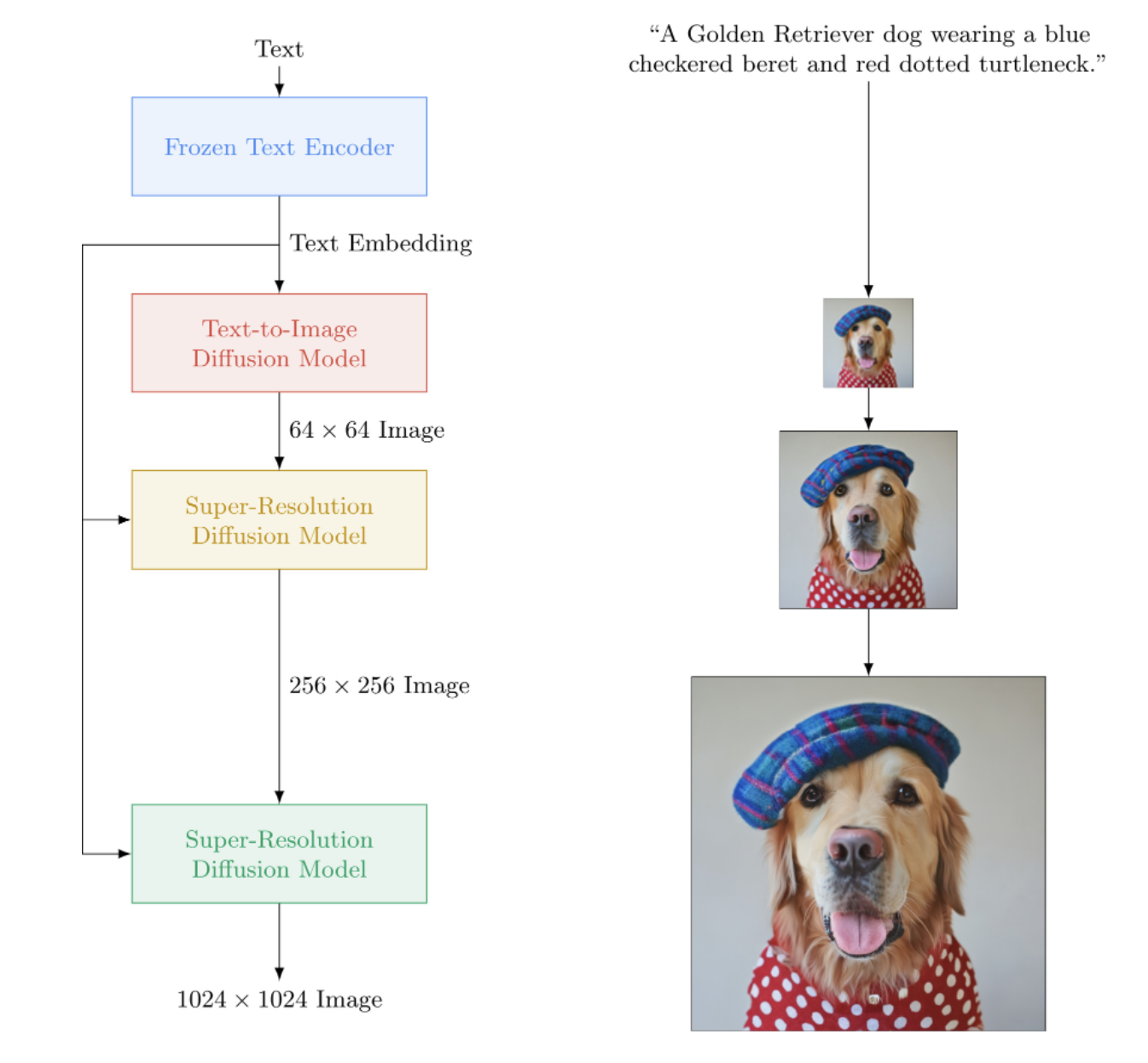
Implementación de Imagen, la red neuronal de texto a imagen de Google que supera a DALL-E2, en Pytorch. Es el nuevo SOTA para síntesis de texto a imagen.
Arquitectónicamente, en realidad es mucho más simple que DALL-E2. Consiste en un DDPM en cascada condicionado a incrustaciones de texto de un gran modelo T5 previamente entrenado (red de atención). También contiene recorte dinámico para una mejor guía sin clasificador, acondicionamiento del nivel de ruido y un diseño unet eficiente en memoria.
Después de todo, parece que no se necesita ni CLIP ni una red previa. Y así continúa la investigación.
Pausa para el café AI con Letitia | Asamblea AI | Yannic Kilcher
Únase si está interesado en ayudar con la replicación con la comunidad LAION.
StabilityAI por el generoso patrocinio, así como a mis otros patrocinadores.
? Huggingface por su increíble biblioteca de transformadores. La parte del codificador de texto está bastante cuidada gracias a ellos.
Jonathan Ho por provocar una revolución en la inteligencia artificial generativa a través de su artículo fundamental
Sylvain y Zachary por la biblioteca Accelerate, que este repositorio utiliza para la capacitación distribuida
Alex para einops, herramienta indispensable para la manipulación de tensores
Jorge Gomes por ayudar con el código de carga del T5 y consejos sobre la versión correcta del T5
Katherine Crowson, por su hermoso código, que me ayudó a comprender la versión en tiempo continuo de la difusión gaussiana.
Marunine y Netruk44, por revisar el código, compartir resultados experimentales y ayudar con la depuración
Marunine por proporcionar una solución potencial para un problema de cambio de color en los u-nets con memoria eficiente. Gracias a Jacob por compartir comparaciones experimentales entre las unidades base y de memoria eficiente.
Marunine por encontrar numerosos errores, resolver un problema con el cambio de tamaño correcto y por compartir sus configuraciones y resultados experimentales.
MalumaDev por proponer el uso de un muestreador aleatorio de píxeles para corregir los artefactos del tablero de verificación
Valentin por señalar insuficientes conexiones skip en el unet, así como el método específico de condicionamiento de la atención en el base-unet en el apéndice.
BIGJUN para detectar un gran error con acondicionamiento del nivel de ruido de difusión gaussiana en tiempo continuo en el tiempo de inferencia
Bingbing para identificar un error con muestreo y orden de normalización y ruido con imagen condicionante de baja resolución
¡Kay por contribuir con el entrenamiento de comando de una línea de Imagen!
Hadrien Reynaud por probar la conversión de texto a video en un conjunto de datos médicos, compartir sus resultados e identificar problemas.
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)Para una capacitación más sencilla, puede proporcionar cadenas de texto directamente en lugar de precalcular codificaciones de texto. (Aunque para fines de escala, definitivamente querrás precalcular las incrustaciones de texto + máscara)
La cantidad de subtítulos textuales debe coincidir con el tamaño del lote de las imágenes si sigue esta ruta.
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () Con la clase contenedora ImagenTrainer , los promedios móviles exponenciales para todas las U-nets en el DDPM en cascada se cuidarán automáticamente al llamar update
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)También puedes entrenar Imagen sin texto (generación de imagen incondicional) de la siguiente manera
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)O entrenar solo unidades súper resolutivas
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) En cualquier momento puede guardar y cargar el entrenador y todos los estados asociados con los métodos save y load . Se recomienda utilizar estos métodos en lugar de guardar manualmente con una llamada state_dict , ya que se realiza cierta gestión de la memoria del dispositivo dentro del entrenador.
ex.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 También puede confiar en ImagenTrainer para entrenar automáticamente las instancias DataLoader . Simplemente tiene que diseñar su DataLoader para que devuelva images (para casos incondicionales) o ('images', 'text_embeds') para generación guiada por texto.
ex. entrenamiento incondicional
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )Gracias a ? Acelere, puede realizar un entrenamiento de múltiples GPU fácilmente con dos pasos.
Primero debe invocar accelerate config en el mismo directorio que su script de entrenamiento (digamos que se llama train.py ).
$ accelerate config A continuación, en lugar de llamar python train.py como lo haría para una sola GPU, usaría la CLI de aceleración como tal.
$ accelerate launch train.py¡Eso es todo!
Imagen también se puede utilizar directamente a través de CLI.
ex.
$ imagen configo
$ imagen config --path ./configs/config.jsonEn la configuración, puede cambiar la configuración del entrenador, el conjunto de datos y la configuración de la imagen.
Los parámetros de configuración de Imagen se pueden encontrar aquí
Los parámetros de configuración de Imagen aclarados se pueden encontrar aquí
Los parámetros de configuración de Imagen Trainer se pueden encontrar aquí
Para los parámetros del conjunto de datos se pueden utilizar todos los parámetros del cargador de datos.
Este comando le permite entrenar o reanudar el entrenamiento de su modelo.
ex.
$ imagen traino
$ imagen train --unet 2 --epoches 10Puede pasar los siguientes argumentos al comando de entrenamiento.
--config especifica el archivo de configuración que se usará para el entrenamiento [predeterminado: ./imagen_config.json]--unet el índice del unet a entrenar [predeterminado: 1]--epoches para cuántas épocas entrenar [predeterminado: 50]Tenga en cuenta que al tomar muestras de su punto de control, debe haber entrenado a todos los unidades para obtener un resultado utilizable.
ex.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngPuede pasar los siguientes argumentos al comando de muestra.
--model especifica el archivo de modelo que se utilizará para el muestreo--cond_scale escala de acondicionamiento (guía libre del clasificador) en el decodificador--load_ema carga la versión EMA de unets si está disponible Para utilizar un punto de control guardado con esta función, debe crear una instancia de su instancia de Imagen utilizando las clases de configuración ImagenConfig y ElucidatedImagenConfig o crear un punto de control directamente a través de la CLI.
Para una capacitación adecuada, es probable que desee configurar una capacitación basada en configuración de todos modos.
ex.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminalRealmente debería ser así de simple.
También puede pasar este archivo de punto de control y cualquiera puede continuar ajustando sus propios datos.
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning Inpainting sigue la formulación establecida por el reciente artículo Repaint. Simplemente pase inpaint_images e inpaint_masks a la función sample en Imagen o ElucidatedImagen
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) Para videos, pase de manera similar sus videos a la palabra clave inpaint_videos en .sample . La máscara de pintura puede ser la misma en todos los fotogramas (batch, height, width) o diferente (batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) Tero Karras, famoso por StyleGAN, ha escrito un nuevo artículo con resultados que han sido corroborados por varios investigadores independientes, así como en mi propia máquina. He decidido crear una versión de Imagen , ElucidatedImagen , para que se pueda utilizar el nuevo DDPM dilucidado para la generación en cascada guiada por texto.
Simplemente importe ElucidatedImagen y luego cree una instancia de la instancia como lo hizo antes. Los hiperparámetros son diferentes a los habituales para la difusión gaussiana en tiempo discreto y continuo, y pueden individualizarse para cada unidad de la cascada.
Ex.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above Este repositorio también comenzará a acumular nuevas investigaciones sobre la síntesis de vídeo guiada por texto. Para empezar, adoptará la arquitectura unet 3D descrita por Jonathan Ho en Video Diffusion Models.
Actualización: trabajo verificado por Hadrien Reynaud.
Ex.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) También puedes entrenar primero con pares de texto e imágenes. Unet3D lo convertirá automáticamente en videos de un solo cuadro y aprenderá sin los componentes temporales (configurando automáticamente ignore_time = True ), ya sean convoluciones 1d o atención causal a lo largo del tiempo.
Este es el enfoque adoptado actualmente por todos los grandes laboratorios de inteligencia artificial (Brain, MetaAI, Bytedance)
Imagen utiliza un algoritmo llamado Classifier Free Guidance. Al realizar el muestreo, se aplica una escala al condicionamiento (texto en este caso) mayor que 1.0 .
El investigador Netruk44 ha informado que 5-10 es óptimo, pero cualquier valor superior a 10 no es adecuado.
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than averageNo por el momento, pero es probable que uno esté capacitado y abierto dentro de un año, si no antes. Si desea participar, puede unirse a la comunidad de entrenadores de redes neuronales artificiales en Laion (el enlace de Discord se encuentra en el archivo Léame arriba) y comenzar a colaborar.
¡Más razones por las que deberías empezar a entrenar tu propio modelo, a partir de hoy! Lo último que necesitamos es que esta tecnología esté en manos de una élite. Con suerte, este repositorio reduce el trabajo a simplemente encontrar la computación necesaria y aumentarla con su propio conjunto de datos seleccionado.
¡Cualquier cosa! Tiene licencia del MIT. En otras palabras, puedes copiar/pegar libremente para tu propia investigación, remezclado para cualquier modalidad que se te ocurra. Vaya a entrenar modelos asombrosos con fines de lucro, para la ciencia o simplemente para saciar su placer personal al presenciar cómo algo divino se desmorona frente a usted.
Síntesis de ecocardiograma [Código]
Síntesis de matriz de contacto SOTA Hi-C [Código]
Generación de planos de planta
Diapositivas de histopatología de ultra alta resolución
Imágenes laparoscópicas sintéticas
Diseño de metamateriales
Difusión de audio de Flavio Schneider
Mini imagen de Ryan O. | Redacción de AssemblyAI
Utilice transformadores Huggingface para incrustaciones de texto pequeño T5.
agregar umbrales dinámicos
agregue umbrales dinámicos DALLE2 y repositorio de difusión de video también
permita que uno configure T5-grande (y tal vez un método de fábrica pequeño para aceptar cualquier transformador de cara abrazada)
agregue el nivel de ruido de baja resolución con el pseudocódigo en el apéndice y descubra qué es este barrido que hacen en el momento de la inferencia
puerto sobre algún código de entrenamiento de DALLE2
Es necesario poder usar un programa de ruido diferente por unet (se usó coseno para la base, pero lineal para SR)
simplemente haga una unidad configurable maestra
bloque resnet completo (¿inspirado en biggan? pero con norma de grupo) - atención personal completa
bloque de incrustación de acondicionamiento completo (y hacerlo completamente configurable, ya sea atención, película, etc.)
considere usar percepter-resampler de https://github.com/lucidrains/flamingo-pytorch en lugar de agrupar la atención
agregar la opción de agrupación de atención, además de atención cruzada y película
agregue un programa opcional de caída del coseno con calentamiento, para cada unidad, al entrenador
cambie a pasos de tiempo continuos en lugar de discretizados, ya que parece que eso es lo que usaron para todas las etapas; primero descubra el caso del cronograma de ruido lineal del documento variacional de ddpm https://openreview.net/forum?id=2LdBqxc1Yv
Calcule log(snr) para el programa de ruido alfa coseno.
suprime la advertencia de los transformadores porque solo se utiliza el codificador T5
permitir la configuración para usar atención lineal en capas donde no se puede usar atención completa
fuerce a los unets en el caso de tiempo continuo a usar condiciones no fouriered (simplemente pase el registro (snr) a través de un MLP con normas de capa opcionales), ya que eso es lo que tengo trabajando localmente
se eliminó la varianza aprendida
agregue ponderación de pérdida p2 para tiempo continuo
asegúrese de que el ddpm en cascada pueda entrenarse sin condición de texto y asegúrese de que funcione la difusión gaussiana en tiempo continuo y discreto.
use las convs en profundidad del cebador en las proyecciones qkv en atención lineal (o use el cambio de token antes de las proyecciones); también use el nuevo abandono propuesto por bayesformer, ya que parece funcionar bien con la atención lineal
explorar la excitación de capa de salto en el decodificador unet
acelerar la integración
Construya una herramienta CLI y una generación de imágenes de una sola línea.
eliminar cualquier problema que surgiera de acelerar
agregue la capacidad de pintar usando un remuestreador de papel de repintado https://arxiv.org/abs/2201.09865
construir un sistema de puntos de control simple, respaldado por una carpeta
agregue una conexión de salto desde las salidas de todos los bloques de muestra superior, utilizada en papel cuadriculado de unet y algunos trabajos anteriores de unet
agregue fsspec, recomendado por Romain @rom1504, para la persistencia de puntos de control independiente del sistema de archivos local/nube
Pruebe la persistencia en gcs con https://github.com/fsspec/gcsfs
extender a la generación de video, usando atención de tiempo axial como en el artículo de video ddpm de Ho
permitir que la imagen aclarada se generalice a cualquier forma
permitir que la imagen se generalice a cualquier forma
agregue un sesgo posicional dinámico para obtener el mejor tipo de extrapolación de longitud a lo largo del tiempo del video
mover fotogramas de vídeo a la función de muestra, ya que intentaremos extrapolar el tiempo
El sesgo de atención a claves/valores nulos debe ser un escalar aprendido de la dimensión principal.
agregue autoacondicionamiento a partir de papel de difusión de bits, ya codificado en ddpm-pytorch
agregue v-parametrización (https://arxiv.org/abs/2202.00512) del documento de video de imagen, lo único nuevo
incorporar todos los aprendizajes de make-a-video (https://makeavideo.studio/)
Desarrolle la herramienta CLI para la capacitación y reanude la capacitación a partir del archivo de configuración.
permitir la interpolación temporal en etapas específicas
asegúrese de que la interpolación temporal funcione con inpainting
asegúrese de poder personalizar todos los modos de interpolación (algunos investigadores están encontrando mejores resultados con trilineal)
imagen-video: permite condicionar fotogramas de vídeos anteriores (y posiblemente futuros). ignorar el tiempo no debería permitirse en ese escenario
asegúrese de encargarse automáticamente del muestreo temporal hacia abajo o hacia arriba para acondicionar los cuadros de video, pero permita una opción para desactivarlo
asegúrese de que inpainting funcione con video
asegúrese de que la máscara de pintura para video se pueda personalizar por cuadro
agregar atención flash
Vuelva a leer cogvideo y descubra cómo se podría utilizar el condicionamiento de la velocidad de fotogramas.
incorporar experiencia en atención para las capas de autoatención en unet3d
considere incorporar la atención convolucional 3D de NUWA
Considere los recuerdos de Transformer-XL en los bloques de atención temporal.
considerar el enfoque del perceptor para atender al tiempo pasado
abandonos del cuadro durante la atención para lograr tanto un efecto de regularización como un tiempo de entrenamiento más corto
investigue las afirmaciones de frank wood https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch y agregue la técnica de muestreo jerárquico o informe a la gente sobre sus deficiencias
Ofrecer un mnist en movimiento desafiante (con objetos distractores) como una línea de base entrenable de una sola línea para que los investigadores puedan derivar de texto a video.
precodificación de texto en incrustaciones con memoria
Ser capaz de crear iteradores de cargador de datos basados en el estilo de la época antigua, también configurar la mezcla, etc.
También podrá pasar argumentos (en lugar de requerir que todos los argumentos de palabras clave del modelo sean forward)
incorporar bloques reversibles de revnets para 3d unet, para reducir la carga de memoria
agregar capacidad para entrenar solo redes de súper resolución
lea dpm-solver y vea si es aplicable a la difusión gaussiana de tiempo continuo
permitir acondicionar cuadros de video con tiempos absolutos arbitrarios (calcular RPE durante la atención temporal)
acomodar el ajuste fino de la cabina de ensueño
agregar inversión textual
autocondicionamiento de limpieza que se extraerá en la instanciación de la imagen
asegúrese de que el eventual dreambooth funcione con imagen-video
agregar acondicionamiento de velocidad de fotogramas para la difusión de video
asegúrese de que se puedan condicionar simultáneamente los fotogramas de vídeo como mensaje, así como alguna imagen condicionada en todos los fotogramas
probar y agregar técnica de destilación a partir de modelos de consistencia
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

