PaLM rlhf pytorch
0.3.9
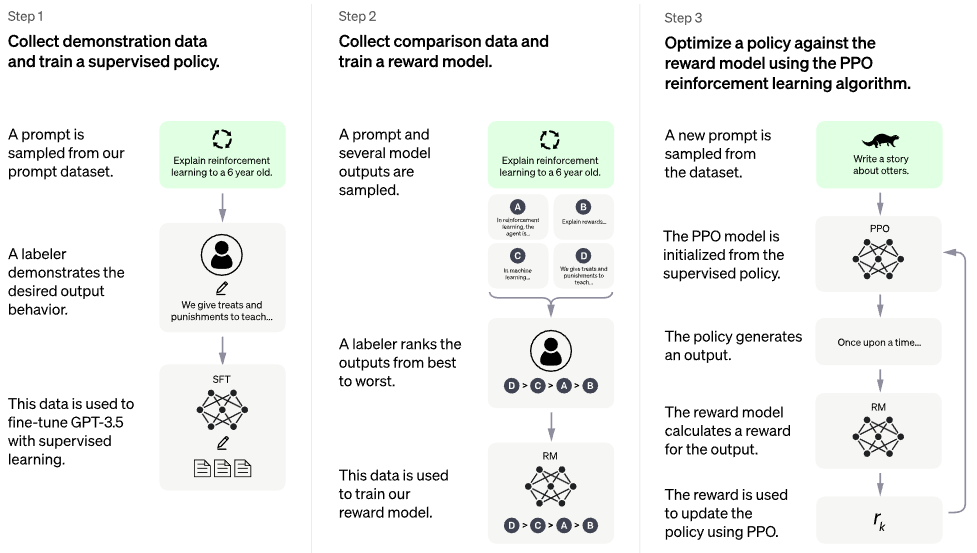
publicación de blog oficial de chatgpt
Implementación de RLHF (Aprendizaje por refuerzo con retroalimentación humana) sobre la arquitectura PaLM. Quizás también agregue funcionalidad de recuperación, al estilo RETRO
Si está interesado en replicar algo como ChatGPT abiertamente, considere unirse a Laion
Sucesor potencial: Optimización de preferencia directa: todo el código en este repositorio se convierte en ~ pérdida de entropía cruzada binaria, <5 loc. Hasta aquí los modelos de recompensa y PPO
No existe un modelo entrenado. Este es sólo el barco y el mapa general. Todavía necesitamos millones de dólares en computación y datos para navegar hasta el punto correcto en el espacio de parámetros de alta dimensión. Incluso entonces, se necesitan marineros profesionales (como Robin Rombach, famoso por Stable Diffusion) para guiar el barco a través de tiempos turbulentos hasta ese punto.
CarperAI había estado trabajando en un marco RLHF para modelos de lenguaje grandes durante muchos meses antes del lanzamiento de ChatGPT.
Yannic Kilcher también está trabajando en una implementación de código abierto.
Pausa para el café AI con Letitia | Emporio de códigos | Emporio de códigos, parte 2
Stability.ai por el generoso patrocinio para trabajar en investigaciones de vanguardia en inteligencia artificial
? Hugging Face y CarperAI por escribir la publicación del blog Illustrating Reinforcement Learning from Human Feedback (RLHF), y el primero también por su biblioteca acelerada.
@kisseternity y @taynoel84 por la revisión del código y la búsqueda de errores
Enrico por integrar Flash Attention de Pytorch 2.0
$ pip install palm-rlhf-pytorch Primer tren PaLM , como cualquier otro transformador autorregresivo
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048) Luego, entrene su modelo de recompensa con comentarios humanos seleccionados. En el artículo original, no pudieron lograr que el modelo de recompensa se ajustara desde un transformador previamente entrenado sin sobreajustarlo, pero de todos modos les di la opción de ajustar con LoRA , ya que todavía es una investigación abierta.
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask ) Luego pasarás tu transformador y el modelo de recompensas al RLHFTrainer
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) Transformador de base clonada con lora separada para crítico.
también permite ajustes no basados en LoRA
rehacer la normalización para poder tener una versión enmascarada, no estoy seguro si alguien alguna vez usará recompensas/valores por token, pero es una buena práctica implementar
equipar con la mejor atención
agregue Hugging Face, acelere y pruebe la instrumentación wandb
Busque literatura para descubrir cuál es el SOTA más reciente para PPO, suponiendo que el campo de RL todavía esté progresando.
Pruebe el sistema utilizando una red de sentimiento previamente entrenada como modelo de recompensa.
escriba la memoria en PPO en un archivo numpy memmapped
hacer que el muestreo funcione con indicaciones de duración variable, incluso si no es necesario dado que el cuello de botella es la retroalimentación humana
permitir el ajuste fino de las penúltimas N capas solo en actor o crítico, suponiendo que esté previamente entrenado
incorporar algunos puntos de aprendizaje de Sparrow, dado el video de Letitia
interfaz web sencilla con django + htmx para recopilar comentarios humanos
considere RLAIF
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

