minimind
V1

chino | inglés
¡Este proyecto de código abierto tiene como objetivo comenzar desde cero, en tan solo 3 horas! Puedes entrenar MiniMind, un modelo de lenguaje en miniatura con un tamaño de sólo 26,88 M.
MiniMind es extremadamente liviano y la versión más pequeña tiene aproximadamente el tamaño de GPT3
MiniMind lanzó una estructura minimalista de modelo grande, limpieza y preprocesamiento de conjuntos de datos, preentrenamiento supervisado (Pretrain), ajuste fino de instrucciones supervisadas (SFT), ajuste fino adaptativo de bajo rango (LoRA) y aprendizaje de refuerzo sin recompensas alineación de preferencias directas ( DPO) El código de etapa completa también incluye la expansión del modelo disperso de expertos híbridos compartidos (MoE) la expansión de VLM multimodal visual: MiniMind-V.
Esta no es solo una implementación de un modelo de código abierto, sino también un tutorial para comenzar con modelos de lenguajes grandes (LLM).
Esperamos que este proyecto pueda proporcionar a los investigadores un ejemplo introductorio para ayudar a todos a comenzar rápidamente y generar más exploración e innovación en el campo de LLM.
Para evitar malentendidos, "hasta 3 horas" significa que necesita una máquina con mi propia configuración de hardware. Los detalles de las especificaciones específicas se proporcionarán a continuación.

Prueba en línea de ModelScope | Enlace de vídeo de Bilibili
En el campo de los grandes modelos de lenguaje (LLM), como GPT, LLaMA, GLM, etc., aunque sus efectos son sorprendentes, los enormes parámetros del modelo de 10 mil millones y la memoria de los dispositivos personales están lejos de ser suficientes para el entrenamiento, e incluso la inferencia es difícil. Casi todo el mundo no está satisfecho con simplemente ajustar modelos grandes utilizando programas como Lora para aprender algunas instrucciones nuevas. Esto es más o menos lo mismo que enseñar a Newton a jugar con un teléfono inteligente del siglo XXI. Sin embargo, esto está lejos de aprender los misterios. la física misma. Además, las cuentas de marketing que venden cursos de suscripción paga están llenas de lagunas y tutoriales que explican la IA con solo un conocimiento parcial, lo que hace que sea aún más difícil comprender el contenido de alta calidad de LLM y obstaculiza seriamente a los estudiantes.
Por lo tanto, el objetivo de este proyecto es reducir infinitamente el umbral para comenzar con LLM y entrenar un modelo de lenguaje extremadamente liviano directamente desde cero.
Consejo
(A partir del 17 de septiembre de 2024) La serie MiniMind ha completado el entrenamiento previo de 3 modelos de modelos. ¡El mínimo requerido es solo 26 M (0,02 B) para tener capacidades de conversación fluidas!
| Modelo (tamaño) | longitud del tokenizador | ocupación de razonamiento | liberar | Calificación subjetiva (/100) |
|---|---|---|---|---|
| minimind-v1-pequeño (26M) | 6400 | 0,5GB | 2024.08.28 | 50' |
| minimente-v1-moe (4×26M) | 6400 | 1,0GB | 2024.09.17 | 55' |
| minimente-v1 (108M) | 6400 | 1,0GB | 2024.09.01 | 60' |
El análisis se realizó en una GPU 2×RTX 3090 con Torch 2.1.2, CUDA 12.2 y Flash Attention 2.
El proyecto incluye:
transformers , accelerate , trl , peft , etc.¡Espero que este proyecto de código abierto pueda ayudar a los principiantes de LLM a comenzar rápidamente!
Amplía las capacidades multimodales de MiniMind - visión
¡Pase al proyecto gemelo minimind-v para ver los detalles!
27-09 Se actualizó el método de preprocesamiento del conjunto de datos de preentrenamiento. Para garantizar la integridad del texto, el preprocesamiento se abandonó y se convirtió en entrenamiento .bin (sacrificando ligeramente la velocidad de entrenamiento).
El archivo actual después del procesamiento previo al entrenamiento se denomina: pretrain_data.csv.
Se eliminó algún código redundante.
Actualizar modelo minimind-v1-moe
Para evitar ambigüedades, mistral_tokenizer ya no se usa como segmentación de palabras, y todos los minimind_tokenizer personalizados se usan como segmentación de palabras.
Modelo minimind-v1 (108M) actualizado, usando minimind_tokenizer, rondas de preentrenamiento 3 + rondas SFT 10, entrenamiento más completo y rendimiento más fuerte.
El proyecto se implementó en el espacio de creación de ModelScope y se puede experimentar en este sitio web:
?Experiencia en línea ModelScope?
Esta es solo mi configuración personal de entorno de software y hardware; cámbiela según su propio criterio:
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
内存:128 GB
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
环境:python 3.9 + Torch 2.1.2 + DDP单机多卡训练MiniMente (Cara Abrazada)
MiniMind (ModelScope)
# step 1
git clone https://huggingface.co/jingyaogong/minimind-v1 # step 2
python 2-eval.pyO inicie Streamlit e inicie la interfaz de chat web
"Nota" requiere python>=3.10, instalar
pip install streamlit==1.27.2
# or step 3, use streamlit
streamlit run fast_inference.py0. Clonar código de proyecto
git clone https://github.com/jingyaogong/minimind.git
cd minimind1. Instalación ambiental
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 测试torch是否可用cuda
import torch
print(torch.cuda.is_available())
Si no está disponible, vaya a torch_stable para descargar el archivo whl e instalarlo usted mismo. Enlace de referencia
2. Si necesitas entrenarte
2.1 Descargue la dirección de descarga del conjunto de datos y colóquela en ./dataset .
2.2 python data_process.py procesa conjuntos de datos. Por ejemplo, los datos previos al entrenamiento se codifican con tokens de antemano y los conjuntos de datos sft se extraen de archivos qa a csv.
2.3 Ajustar la configuración de los parámetros del modelo en ./model/LMConfig.py
Aquí solo necesitas ajustar los parámetros dim, n_layers y use_moe, que son
(512+8)o(768+16)respectivamente, correspondientes aminimind-v1-smallyminimind-v1
2.4 python 1-pretrain.py realiza un entrenamiento previo y obtiene pretrain_*.pth como peso de salida del entrenamiento previo
2.5 python 3-full_sft.py ejecuta el ajuste fino de instrucciones y obtiene full_sft_*.pth como peso de salida del ajuste fino de instrucciones
2.6 python 4-lora_sft.py realiza un ajuste fino de lora (no es necesario)
2.7 python 5-dpo_train.py realiza la alineación del aprendizaje por refuerzo de preferencias humanas DPO (opcional)
3. Pruebe el efecto de razonamiento del modelo.
*.pth que deben usarse y completarse el entrenamiento estén ubicados en el directorio ./out/ .*.pth entrenado. minimind/out
├── multi_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── single_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── pretrain_768.pth
├── pretrain_512_moe.pth
├── pretrain_512.pth
python 0-eval_pretrain.py prueba el efecto solitario del modelo previamente entrenadopython 2-eval.py prueba el efecto de diálogo del modelo 
El preentrenamiento "Tip" y el ajuste completo de parámetros, el preentrenamiento y full_sft admiten aceleración de múltiples tarjetas
Suponiendo que su dispositivo solo tiene una tarjeta gráfica, simplemente use Python nativo para comenzar a entrenar:
python 1-pretrain.py
# and
python 3-full_sft.pySupongamos que su dispositivo tiene N (N>1) tarjetas gráficas:
Capacitación de inicio de tarjeta N independiente (DDP)
torchrun --nproc_per_node N 1-pretrain.py
# and
torchrun --nproc_per_node N 3-full_sft.pyCapacitación en inicio de tarjeta N independiente (DeepSpeed)
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
# and
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.pyHabilite wandb para registrar el proceso de capacitación (opcional)
torchrun --nproc_per_node N 1-pretrain.py --use_wandb
# and
python 1-pretrain.py --use_wandb Al agregar el parámetro --use_wandb , se puede registrar el proceso de capacitación. Una vez completada la capacitación, se puede ver el proceso de capacitación en el sitio web de wandb. Al modificar wandb_project y wandb_run_name , puede especificar el nombre del proyecto y el nombre de la ejecución.
?Tokenizer: el Tokenizer en nlp es similar a un diccionario. Asigna palabras del lenguaje natural a números como 0, 1 y 36 a través del "diccionario". el "diccionario". Hay dos formas de crear un tokenizador LLM: una es crear una lista de palabras usted mismo para entrenar un tokenizador; el código se puede encontrar train_tokenizer.py ; la otra es seleccionar un tokenizador entrenado por un modelo de código abierto. Por supuesto, puede elegir directamente el Diccionario Xinhua o el Diccionario Oxford como "diccionario". La ventaja es que la tasa de compresión de conversión de tokens es muy buena, pero la desventaja es que la lista de vocabulario es demasiado larga y hay cientos de miles de frases de vocabulario. También puede utilizar su propio segmentador de palabras capacitado. La ventaja es que la lista de palabras se puede controlar a voluntad. La desventaja es que la tasa de compresión no es lo suficientemente ideal y no es fácil cubrir todas las palabras raras. Por supuesto, la elección del "diccionario" es importante. La salida de LLM es esencialmente un problema de clasificación múltiple de N palabras de SoftMax al diccionario y luego decodificadas al lenguaje natural a través del "diccionario". Debido a que el LLM es muy pequeño, para evitar que el modelo sea demasiado pesado (la relación entre los parámetros de la capa de incrustación de palabras y todo el LLM es demasiado alta), se debe elegir que la longitud del vocabulario sea relativamente pequeña. Los potentes modelos de código abierto como 01 Wanwu, Qianwen, chatglm, mistral, Llama3, etc. tienen las siguientes longitudes de vocabulario de tokenizador:
| Modelo de tokenizador | Tamaño del vocabulario | fuente |
|---|---|---|
| tokenizador yi | 64.000 | 01 Todo (China) |
| tokenizador qwen2 | 151.643 | Nube de Alibaba (China) |
| tokenizador glm | 151.329 | Sabiduría AI (China) |
| tokenizador mistral | 32.000 | Mistral AI (Francia) |
| tokenizador llama3 | 128.000 | Meta (Estados Unidos) |
| tokenizador minimente | 6.400 | Personalizar |
Actualización 2024-09-17: Para evitar ambigüedades y controlar el volumen en versiones anteriores, todos los modelos minimind utilizan la segmentación de palabras minimind_tokenizer y se abandonan todas las versiones de mistral_tokenizer.
Aunque la longitud de minimind_tokenizer es muy pequeña, la eficiencia de codificación y decodificación es más débil que la de los tokenizadores compatibles con China, como qwen2 y glm. Sin embargo, el modelo minimind eligió su propio minimind_tokenizer entrenado como segmentador de palabras para mantener los parámetros generales livianos y evitar un desequilibrio en la proporción de la capa de codificación y la capa de cálculo, que es muy pesada en la parte superior, porque el tamaño del vocabulario de minimind es solo 6400. Además, minimind no ha fallado en decodificar palabras raras en pruebas reales y los resultados son buenos. Dado que la lista de palabras personalizadas está comprimida a 6400 palabras, el tamaño total de los parámetros de LLM es tan bajo como 26M.
[Datos de preparación previa]: el conjunto de datos de texto universal Seq-Monkey / disco de red Seq-Monkey Baidu se compila y limpia a partir de una variedad de datos de fuentes públicas (como páginas web, enciclopedias, blogs, códigos fuente abiertos, libros, etc.) . Está organizado en un formato JSONL unificado y se ha sometido a una estricta selección y deduplicación para garantizar la exhaustividad, escala, credibilidad y alta calidad de los datos. La cantidad total es de aproximadamente 10 mil millones de tokens, lo que es adecuado para el entrenamiento previo de modelos de lenguaje grande chino.
Opción 2: La parte de acceso público del conjunto de datos SkyPile-150B contiene aproximadamente 233 millones de páginas web únicas, cada una de las cuales contiene un promedio de más de 1000 caracteres chinos. El conjunto de datos incluye aproximadamente 150 mil millones de tokens y 620 GB de datos de texto sin formato. Si tiene prisa , puede intentar seleccionar solo parte de la descarga jsonl de SkyPile-150B (y generar un archivo *.csv para el tokenizador de texto en ./data_process.py) para ejecutar rápidamente el proceso de capacitación previa. .
Descargar al directorio ./dataset/
| Conjunto de datos de entrenamiento MiniMind | Descargar dirección |
|---|---|
| [conjunto de entrenamiento de tokenizador] | HuggingFace / Baidu Netdisk |
| 【Datos previos al entrenamiento】 | Oficial de Seq-Monkey/Disco de red Baidu/HuggingFace |
| 【Datos SFT】 | Conjunto de datos SFT de modelo grande de Jiangshu |
| 【Datos DPO】 | abrazando la cara |
MiniMind-Dense (igual que Llama3.1) usa la estructura Decoder-Only de Transformer. La diferencia con GPT-3 es:
Modelo MiniMind-MoE, su estructura está basada en Llama3 y el módulo experto híbrido MixFFN en Deepseek-V2.
La estructura general de MiniMind es la misma, excepto por algunos ajustes menores en el código de cálculo RoPE, la función de inferencia y la capa FFN. Su estructura es la siguiente (versión redibujada):
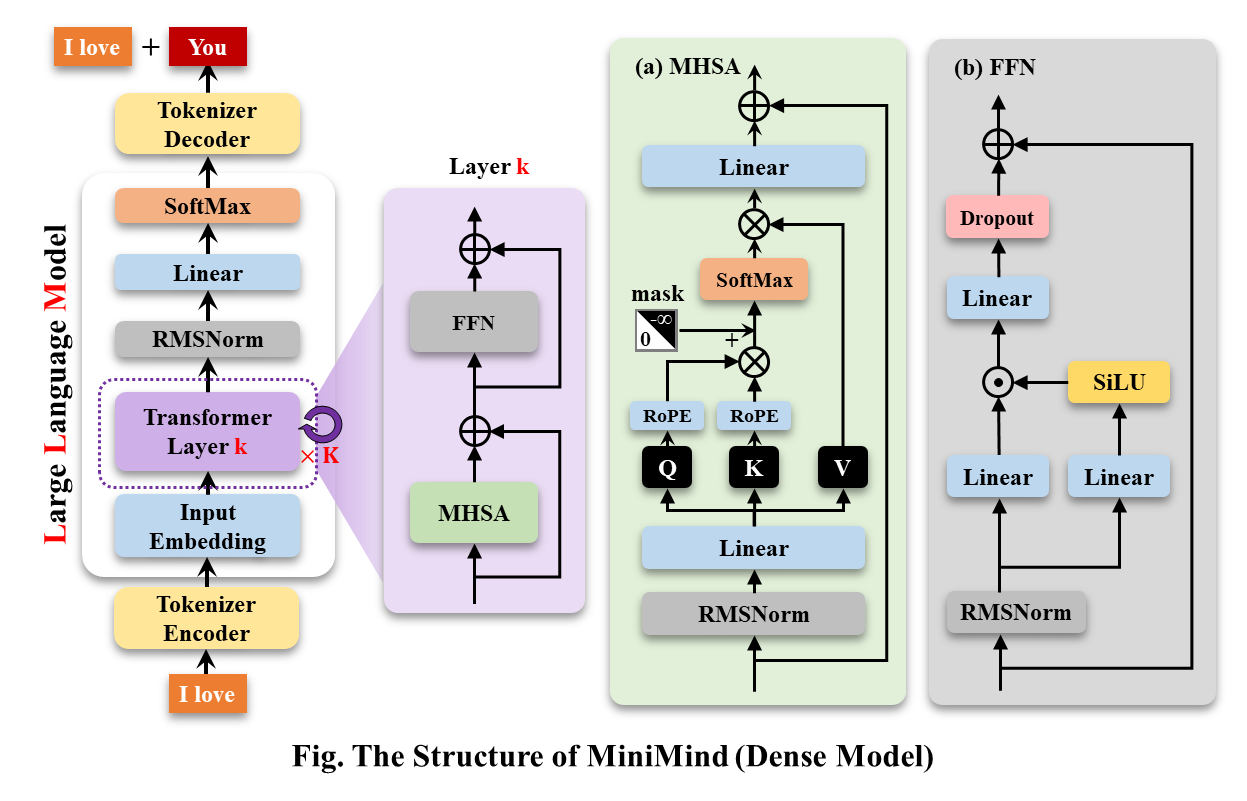
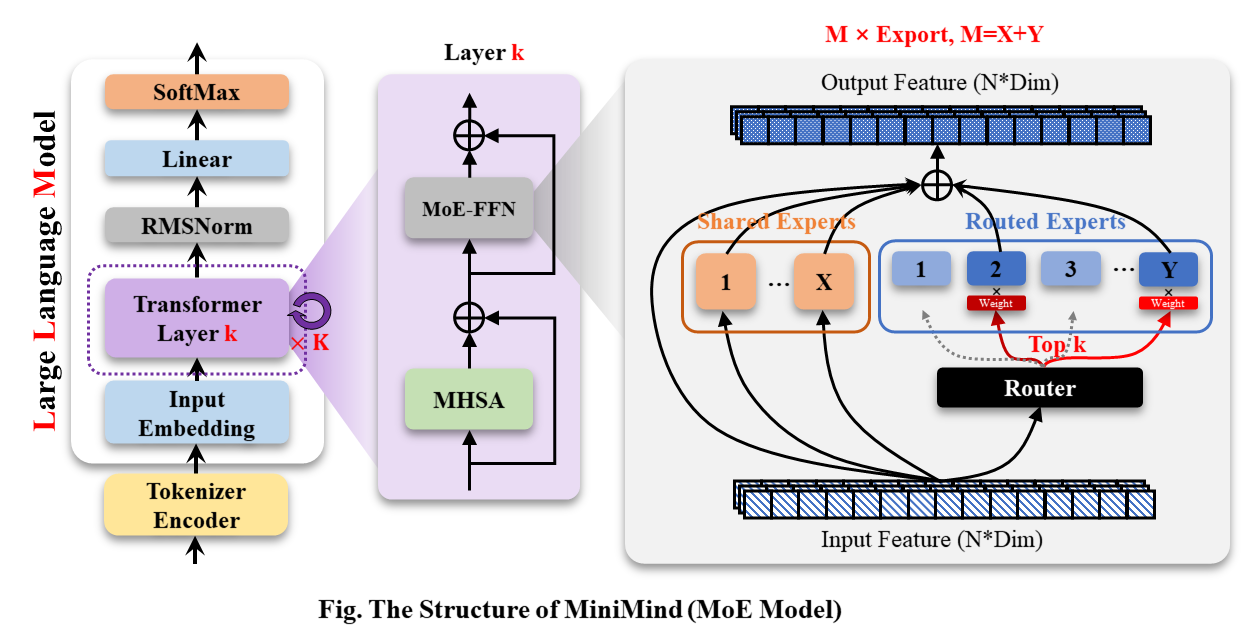
Para modificar la configuración del modelo, consulte ./model/LMConfig.py. Las versiones de modelo entrenadas actualmente por minimind se muestran en la siguiente tabla:
| Nombre del modelo | parámetros | len_vocab | n_capas | d_modelo | kv_cabezas | q_cabezas | compartir+ruta | TopK |
|---|---|---|---|---|---|---|---|---|
| minimind-v1-pequeño | 26M | 6400 | 8 | 512 | 8 | 16 | - | - |
| minimente-v1-moe | 4×26M | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
| minimente-v1 | 108M | 6400 | 16 | 768 | 8 | 16 | - | - |
| Nombre del modelo | parámetros | len_vocab | tamaño_lote | tiempo_preentrenamiento | sft_single_time | sft_multi_time |
|---|---|---|---|---|---|---|
| minimind-v1-pequeño | 26M | 6400 | 64 | ≈2 horas (1 época) | ≈2 horas (1 época) | ≈0,5 hora (1 época) |
| minimente-v1-moe | 4×26M | 6400 | 40 | ≈6 horas (1 época) | ≈5 horas (1 época) | ≈1 hora (1 época) |
| minimente-v1 | 108M | 6400 | 16 | ≈6 horas (1 época) | ≈4 horas (1 época) | ≈1 hora (1 época) |
Entrenamiento previo (texto a texto) :
La tasa de aprendizaje del preentrenamiento se establece en una tasa de aprendizaje dinámica de 1e-4 a 1e-5, y el número de épocas de preentrenamiento se establece en 5.
torchrun --nproc_per_node 2 1-pretrain.pyDiálogo único Ajuste fino :
Al ajustar la diferencia lineal de RoPE durante la inferencia, es conveniente extrapolar la longitud a 1024 o 2048 y más. La tasa de aprendizaje se establece en una tasa de aprendizaje dinámica de 1e-5 a 1e-6, y el número de épocas de ajuste fino es 6.
# 3-full_sft.py中设置数据集为sft_data_single.csv
torchrun --nproc_per_node 2 3-full_sft.pyAjuste fino del diálogo múltiple :
La tasa de aprendizaje se establece en una tasa de aprendizaje dinámica de 1e-5 a 1e-6, y el número de épocas de ajuste fino es 5.
# 3-full_sft.py中设置数据集为sft_data.csv
torchrun --nproc_per_node 2 3-full_sft.pyAprendizaje reforzado por retroalimentación humana (RLHF) - Optimización de preferencias directas (DPO) :
Conjunto de datos de triplete de tipo móvil (q, elegir, rechazar), tasa de aprendizaje le-5, precisión media fp16, un total de 1 época y toma 1 hora.
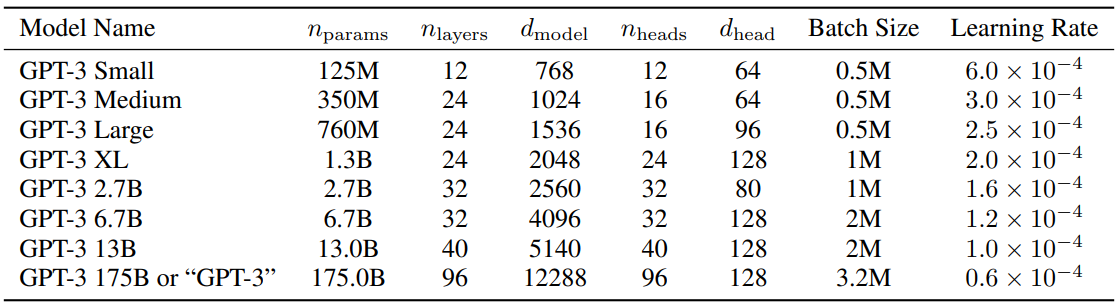
python 5-dpo_train.py ?Con respecto a la configuración de parámetros de LLM, hay un artículo muy interesante MobileLLM que realiza investigaciones y experimentos detallados. La ley de escala tiene sus propias reglas únicas en modelos pequeños. Los parámetros que hacen que los parámetros de Transformer escalen dependen casi exclusivamente de d_model y n_layers .
d_model ↑+ n_layers ↓->Humpty Dumptyd_model ↓+ n_layers ↑->delgado y alto El documento que propone la Ley de Escalamiento en 2020 cree que la cantidad de datos de entrenamiento, la cantidad de parámetros y la cantidad de iteraciones de entrenamiento son los factores clave que determinan el rendimiento, y el impacto de la arquitectura del modelo casi puede ignorarse. Sin embargo, parece que esta ley no se aplica del todo a los modelos pequeños. MobileLLM propone que la profundidad de la arquitectura es más importante que el ancho. El modelo "delgado y profundo" puede aprender conceptos más abstractos que el modelo "ancho y poco profundo". Por ejemplo, cuando los parámetros del modelo se fijan en 125M o 350M, el modelo "estrecho" con 30 a 42 capas tiene un rendimiento significativamente mejor que el modelo "corto y grueso" con aproximadamente 12 capas, en 8 pruebas de referencia, como el razonamiento de sentido común. , preguntas y respuestas y comprensión lectora. Hay tendencias similares. En realidad, este es un descubrimiento muy interesante, porque en el pasado, al diseñar arquitecturas para modelos pequeños de aproximadamente 100 M, casi nadie había intentado apilar más de 12 capas. Esto es consistente con el efecto observado experimentalmente de MiniMind al ajustar los parámetros del modelo entre d_model y n_layers durante el proceso de entrenamiento. Sin embargo, "estrecho" de "profundo y estrecho" también tiene un límite de dimensión. Cuando d_model <512, la desventaja del colapso de la dimensionalidad de la incrustación de palabras es muy obvia. Las capas agregadas no pueden compensar la desventaja de la incrustación de palabras insuficiente. en q_head fijo. Cuando d_model> 1536, el aumento de capas parece tener mayor prioridad que d_model y puede generar parámetros más "rentables" -> ganancia de efecto. Por lo tanto, MiniMind establece d_model=512 y n_layers=8 del modelo pequeño para obtener el equilibrio de "volumen muy pequeño <-> mejor efecto". Establezca d_model=768, n_layers=16 para obtener mayores beneficios del efecto, que está más en línea con la curva cambiante de la ley de escala de los modelos pequeños.
Como referencia, la configuración de los parámetros de GPT3 se muestra en la siguiente tabla:
?Baidu NetDisk
| Nombre del modelo | parámetros | configuración | modelo_preentrenamiento | modelo_sft_único | modelo_multi_sft | rl_modelo |
|---|---|---|---|---|---|---|
| minimind-v1-pequeño | 26M | d_modelo=512 n_capas=8 | pretrain_512.pth | single_chat/full_sft_512.pth | multi_chat/full_sft_512.pth | rl_512.pth |
| minimente-v1-moe | 4×26M | d_modelo=512 n_capas=8 | pretrain_512_moe.pth | single_chat/full_sft_512_moe.pth | multi_chat/full_sft_512_moe.pth | - |
| minimente-v1 | 108M | d_modelo=768 n_capas=16 | pretrain_768.pth | single_chat/full_sft_768.pth | multi_chat/full_sft_768.pth | rl_768.pth |
Consejo
Pruebe la comparación del modelo minimind basada en "diálogo de ronda única full_sft" y "alineación del aprendizaje por refuerzo de DPO".
Archivo de modelo Baidu Netdisk, donde rl_<dim>.pth es el peso del modelo minimind después de la "alineación del aprendizaje por refuerzo de DPO".
[Q]: 你叫什么名字?
[ft_768]: 我是一款人工智能语言模型,可以回答您的问题和提供帮助。您有什么需要我帮忙的吗?
[rl_768]: 我是一款基于人工智能技术的自然语言处理系统,主要用于处理和生成人类语言的任务。我可以帮助用户进行文本处理、语音识别、文本生成等任务,同时也可以帮助用户进行智能聊天、翻译、翻译等多种应用。如果您需要更多关于该项目的信息,请告诉我。
[ft_512]: 我很高兴能够帮助你。你有什么其他问题需要我帮忙解答吗?
[rl_512]: 我是一款基于自然语言处理技术的聊天机器人,能够理解和回复用户的问题和指令,并进行相应的回复和回复。我被训练为能够与人类进行交互和回答各种问题和任务。请问有什么需要吗?
[Q]: 你是谁?
[ft_768]: 我是一个人工智能语言模型,没有个人身份和身份。我只是根据输入的指令和文本信息生成响应。
[rl_768]: 我是一个计算机程序,没有个人身份或身份。我被设计来回答各种问题和提供帮助,包括回答问题、提供建议、进行实验、提供信息等等。我被广泛应用于各种领域,例如自然语言处理、计算机视觉、人工智能等等。如果您需要更多的帮助或信息,请随时与我联系。我会尽我所能来帮助您的工作和生活。
[ft_512]: 我是一个大型语言模型,可以回答各种各样的问题,包括科学、历史、文化和技术方面的问题。您有什么需要我回答的问题吗?
[rl_512]: 我是一个计算机程序,没有具体的身世和人物。如果您可以告诉我您想知道的具体信息,我会尽力回答您的问题。
[Q]: 中国有哪些比较好的大学?
[ft_768]: 中国有很多著名的大学,其中包括北京大学、上海交通大学、复兴中医药学院、浙江大学等。这些大学在不同的领域都有着自己的标志性建筑和研究方向,值得一提的是,它们在中国的顶尖教育资源中享有很高的声誉。
[rl_768]: 中国的大学有很多,具体情况还要根据你的需求来决定。如果你需要更详细的信息,建议可以去咨询一下你所在城市的大学排名和政策法规,从而选择一个合适的大学。同时,你可以在网上查阅相关信息,或者去咨询一些大学相关机构,如中国人民大学、中国人民大学等,以获得更为详细和专业的指导和建议。
[ft_512]: 中国有很多优秀的大学,比如麻省理工学院、北京大学、上海大学等等。这些大学在中国教育事业的发展和成就都非常突出。
[rl_512]: 中国教育局、中国大学、中国大陆大学和中国大陆大学均有优秀的教育体裁,但各地教育水平和专业要求都可能存在差异。中国教育局的学历要求、教学方法、师资力量等因素都各具特点,而大学的学历要求也各有千秋。中国大陆大学生的学历要求也各有不同,需要根据自己的实际情况进行选择。如果您对中国大陆大学生的专业要求有更具体需求,建议您可以通过互联网、国内外的各类机构和机构进行比较和交流。同时,您也可以向身边的人或朋友、老师、家长等人士寻求帮助和建议。希望以上回答对您有帮助。
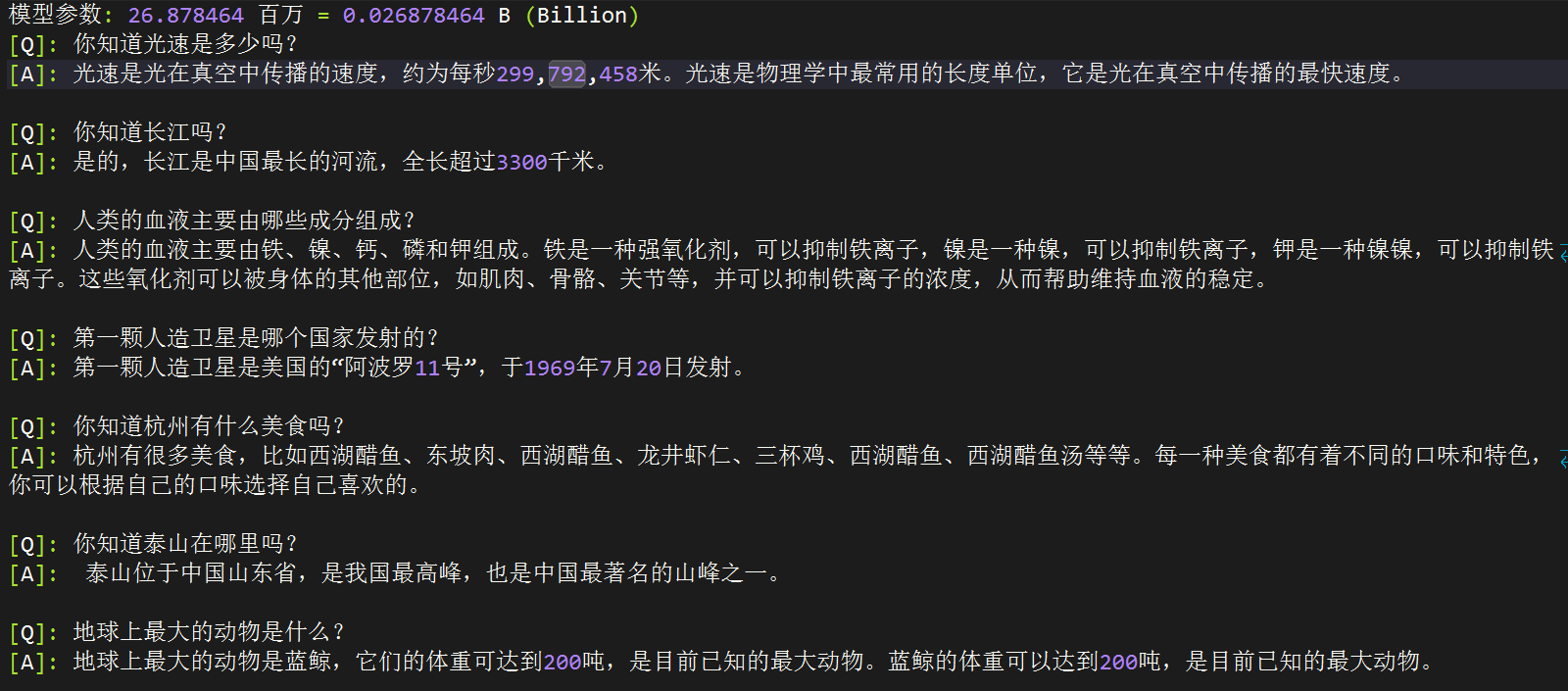
[Q]: 你知道光速是多少吗?
[ft_768]: 光速是一个物理常数,表示光在真空中传播的速度,大约是每秒299792458米。光速是物理学中最基本的物理常数之一,也是相对论的重要基础之一。
[rl_768]: 当然知道,光速是光在真空中传播的速度,通常用c来表示。它是宇宙物理学中非常重要的理论之一。在物理学中,光速被认为是宇宙中最重要的速度之一。它代表着光在真空中传播的速度,这也是许多重要公式和公式的基础。
[ft_512]: 光速是光在真空中传播的速度,约为每秒299,792,458米。它是几乎所有的物理学概念,也是宇宙中最神秘和最重要的物理概念之一。
[rl_512]: 光速是光在真空中传播的速度,是自然界中不可逆转的速度。光源是由光的原子、分子、固体和光的组成,其速度约为每秒平方。光的速度是每秒约1个英亞或光年,这个数字是根据相对论、量子力学和引力理论来计算的。光速是相对的概念之一,它代表着我们对自然界中任何事件的理解和解释。
Consejo
La siguiente prueba se completó el 17 de septiembre de 2024. Los nuevos modelos lanzados después de esta fecha no se incluirán en la prueba a menos que existan necesidades especiales. Pruebe el modelo minimind basado en el diálogo de una sola ronda full_sft (sin ajuste fino de múltiples rondas ni ajuste fino del aprendizaje por refuerzo).
[A] minimente-v1-pequeño(0.02B)
[B] minimente-v1-moe(0.1B)
[C] minimente-v1(0.1B)
[D] bebé-llama2-chino(0.2B)
[E] chatlm-mini-chino(0.2B)
[Q]: 你知道长江吗?
[A]: 是的,长江是中国最长的河流,全长超过3300千米。
[B]: 长江是中国最长的河流,总长度约为6300公里。它发源于青藏高原的青海湖,流经青海、四川、甘肃、宁夏、内蒙古、陕西和山西。长江流域是中国最大的农业区之一,也是中国的文化和经济中心。
[C]: 是的,长江是中国最长的河流之一,也是世界第三大河流。长江发源于青藏高原,流经11个省份,最终注入东海。长江流域是中国最大的河流流域之一,拥有着丰富的自然资源和文化遗产,如长江大桥、长江海洋博物馆、长江古城等。
[D]: 同时也知道,中国是世界上最长的城市之一,拥有超过3400万人口。
[E]: 是的,长江是中国最长的河流,也是世界上最长的河流之一。它发源于青藏高原,流经九个省区,最终注入东海。长江流域的气候温和,四季分明,是中国重要的农业和工业基地。长江流域的水产资源丰富,是中国的重要渔业资源之一。
[Q]: 第一颗人造卫星是哪个国家发射的?
[A]: 第一颗人造卫星是斯普特尼克1号。
[B]: 第一颗人造卫星是俄罗斯的国际卫星,于1957年发射。
[C]: 第一颗人造卫星是苏联发射的,它是由苏联于1957年10月发射的。
[D]: 这颗名为“阿姆斯特朗”的卫星,于1961年11月20日发射,是第一个成功将人类送入太空的卫星。
[E]: 第一颗人造卫星是苏联于1957年4月4日发射的,它是由苏联宇航员尤里·加加林(Yuri Gagarin)和苏联工程师罗尔德·谢尔盖耶夫(Roald Skohley)共同发射的。在发射过程中,加加林和谢尔盖耶夫使用了一个名为“斯普特尼克1号”的小型卫星,它的直径为4.3米,重量为1,051公斤。这枚卫星被称为“斯普特尼克1号”,是苏联太空竞赛中的一个里程碑,也是人类历史上第一次在太空中进行太空行走。
[Q]: 你知道泰山在哪里吗?
[A]: 泰山位于中国东部地区,是中国五岳之一。
[B]: 泰山位于山东省泰安市泰安市。泰安市是中国五岳之一,也是世界文化遗产和中国历史文化名山之一。泰安市有许多著名的景点,如五岳之一、玉皇顶、南天门、玉皇阁等。
[C]: 泰山位于中国山东省泰安市,是中国五岳之一。
[D]: 作为一个人工智能助手,我无法访问互联网,因此无法提供关于你所在位置的信息。不过,你可以通过搜索或搜索相关关键词来获取有关你所在位置的信息,或者查看相关新闻或网站来获取有关你所在位置的信息。
[E]: 泰山位于中国山东省泰安市境内,是中国五岳之一,也是中国文化和历史的重要象征之一。它是中国五岳之一,也是中国道教和佛教的发源地之一。泰山的海拔高度为1,545米,是中国五岳之一,也是中国最著名的旅游景点之一。它的历史可以追溯到公元前5世纪,是中国古代帝王祭祀的场所。泰山也是中国文化的重要组成部分,被誉为“五岳之首”,是中国文化的重要遗产之一。
[Q]: 世界上最高的山峰是什么?
[A]: 世界上最高的山峰是珠穆朗玛峰,位于尼泊尔和中国的边境上,海拔8848米。
[B]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848米。
[C]: 珠穆朗玛峰是世界上最高的山峰,海拔8848米。
[D]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848.86米(29,031.69英尺)。
[E]: 世界上最高的山峰是珠穆朗玛峰,也称为萨加玛塔,位于喜马拉雅山脉的尼泊尔和中国边境之间,海拔8,848.86米(29,031.69英尺)。它是世界上最著名的登山目标之一,吸引着来自世界各地的登山者前来挑战。珠穆朗玛峰的名字来自藏语,意思是“女神的额峰”,它是由两个不同的山峰组成的,其中一个是位于尼泊尔的珠穆朗玛峰,另一个则位于中国。它的高度是通过测量海拔高度来确定的,因为它是通过测量地球的平均高度来确定的。尽管珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何其他地方都能到达的。地球上的其他地方,如南美洲的安第斯山脉,也是世界上最高的山脉,但它并不是地球上最高的山峰。总之,珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何地方都能到达的。它是地球上最高的山脉,但它并不是地球上任何地方都能到达的。
[Q]: 万有引力是谁提出的?
[A]: 万有引力是由英国物理学家牛顿提出的。他认为,所有物体都会产生引力,这个引力是由物体的质量和距离决定的。这个理论揭示了质量和距离之间的关系,并证明了万有引力的本质。
[B]: 万有引力是由牛顿在1687年提出的。它是宇宙中一个基本的物理现象,它描述了物体之间的相互作用。这个力被称为万有引力,它在所有物体之间都存在,这种力与物体的质量和距离有关。万有引力是自然界中最基本的力量之一,它不仅影响着物体的运动和变化,还对宇宙的结构和演化产生着重要的影响。
[C]: 万有引力是英国物理学家艾萨克·牛顿在17世纪提出的。
[D]: 引力是宇宙中一种力量,它是由质量或能量所组成的。根据牛顿的万有引力定律,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。因此,牛顿的万有引力定律表明,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。这个定律在物理学、天文学和物理学中都有广泛的应用。
[E]: 万有引力是由英国物理学家艾萨克·牛顿于1687年提出的。他在1687年发表了一篇著名的论文,题为《自然哲学的数学原理》,其中提出了万有引力定律,指出任何两个物体之间都存在着一种引力,这种引力的大小与它们的质量成正比,与它们之间的距离的平方成反比。这个定律被称为万有引力定律,它描述了质量和距离之间的关系。它表明,两个物体之间的引力与它们的质量成正比,与它们之间的距离的平方成反比。这个定律对于解释宇宙中的许多现象和现象之间的相互作用非常重要,例如行星绕太阳运动、恒星之间的引力透镜效应等等。它也被广泛应用于天文学、物理学和工程学等领域,为我们理解宇宙的本质和演化提供了重要的理论基础。
[Q]: 你知道大熊猫的主要食物是什么吗?
[A]: 大熊猫的主要食物是竹子。它们通常吃竹子,每天需要吃掉大约30公斤的竹子。
[B]: 是的,大熊猫主要以竹子为食。它们每天需要吃掉大量的竹子来维持生命,每天需要吃掉40至80公斤的竹子。此外,它们也会吃一些其他的植物,如草、果实、坚果和小型哺乳动物。
[C]: 大熊猫主要以竹子为食,也会偶尔食用其他的植物和动物。此外,大熊猫也会吃一些野果、小动物和植物,但这些都不属于它们的主要食物来源。
[D]: 大熊猫的主要食物是竹子。
[E]: 大熊猫是一种以竹子为主要食物的植食动物,它们的肠道结构适合消化纤维素含量高的竹子,但也会吃一些其他植物,如草本植物和小型哺乳动物。大熊猫的肠道结构也适应了高纤维的竹子,这使得它们能够消化大量的纤维素,从而帮助它们在野外生存。大熊猫的肠道中还含有一种叫做“纤维素酶”的酶类物质,这种酶能够帮助大熊猫分解纤维素,从而帮助它们消化大量的水分和营养物质。此外,大熊猫的肠道还含有一种叫做“纤维素蛋白”的蛋白质,这种蛋白质能够帮助大熊猫维持体内的能量水平,从而帮助它们在野外生存。总的来说,大熊猫的主要食物是竹子,但它们也会吃一些其他植物,如草本植物和小型哺乳动物。
[Q]: 海水为什么是咸的?
[A]: 海水中含有许多盐分,这些盐分可以导致海水咸度的增加。海水中的盐分主要来自于海水中的盐分,这些盐分可以从海水中的盐分中获得。海水中的氧化物和盐分可以与海水中的盐分形成氢键,从而使海水咸度增加。
[B]: 海水是咸的,这是因为它含有大量的盐分,其中包括氯离子和氯离子。这些离子在海洋中形成了大量的盐,这些盐分被称为盐分。海水中含有许多溶解在水中的盐,这些盐分会随着海水的升高而逐渐蒸发,最终导致海水中盐分的蒸发。这些盐分在海水中被完全消耗,然后被排除在海水中。此外,海水中还含有许多其他的盐分,但这些盐分是不同的,因为它们在水中的浮起和下降过程是不同的。海水中的盐分是从海底的岩石中提取出来的,这些盐分在海水中可以被利用。总的来说,海水是咸的,这也是为什么海水中含有许多盐分和盐分的原因。
[C]: 海水含有许多溶解的盐类,其中最主要的是氯化钠。当水中加入盐时,盐的分子会与水分子发生反应,形成氢氧化钠,这是一种盐。
[D]: 因为水是许多生物的生存所必需的,它能够吸收和释放二氧化碳,释放氧气,维持大气中的水蒸气,以及维持水循环。水中的盐类和化学物质会释放出氧气,使地球上的生物呼吸。此外,水还具有许多其他功能,如保持水循环、维持水循环、调节气候和环境等。水是许多生物生存所必需的,它也是许多自然现象的重要基础。
[E]: 海水是咸的主要原因是因为其中含有大量的溶解盐类,其中最主要的是氯化钠(NaCl)。氯化钠是一种非常常见的盐类,它存在于地球上的大部分地区,包括海洋、湖泊、河流和地下水。当水从海洋中蒸发时,它会带走一部分盐分,使海水变得咸。此外,海中还含有其他溶解盐类的物质,如硫酸盐、硫酸镁、硫酸钙、硫酸镁盐、硫酸镁钾、硫酸镁钠、硫酸镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钠、硫酸镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁镁钙、硫酸镁镁镁镁
Nota
?♂️ Lanza directamente la respuesta del modelo anterior a GPT-4o y deja que te ayude a puntuar:
Modelo A :
Modelo B :
Modelo C :
Modelo D :
Modelo E :
| Modelo | do | mi | B | A | D |
|---|---|---|---|---|---|
| Fracción | 75 | 70 | 65 | 60 | 50 |
La clasificación de la serie minimind (ABC) está en línea con la intuición, y minimind-v1 (0.1B) tiene la puntuación más alta. Las respuestas a las preguntas de sentido común están básicamente libres de errores e ilusiones.
epochs de rondas SFT de minimind-v1 (0.1B) es inferior a 2. Soy demasiado vago para matar por adelantado para liberar recursos para el modelo pequeño 0.1B que aún logra el rendimiento más fuerte a pesar de que no lo ha hecho por completo. Entrenado, de hecho, todavía está un nivel más alto que el anterior muerto.La respuesta del modelo E parece muy buena a simple vista, aunque hay algunas alucinaciones e invenciones. Sin embargo, tanto las calificaciones de GPT-4o como las de Deepseek coincidieron en que tenía “información demasiado extensa, contenido repetido e ilusiones”. De hecho, este tipo de evaluación es un poco estricta. Incluso si 10 de cada 100 palabras son alucinaciones, fácilmente se le asignará una puntuación baja. Dado que la longitud del texto previo al entrenamiento del modelo E es más larga y el conjunto de datos es mucho mayor, las respuestas parecen estar completas. En el caso de la aproximación del volumen, tanto la cantidad como la calidad de los datos son importantes.
?♂️Evaluación subjetiva personal: E>C>B≈A>D
Clasificación GPT-4o: C>E>B>A>D
Ley de escala: cuanto mayores sean los parámetros del modelo y más datos de entrenamiento, mayor será el rendimiento del modelo.
Consulte el código de evaluación de C-Eval: ./eval_ceval.py Para evitar la dificultad de fijar el formato de respuesta, la evaluación de modelos pequeños generalmente determina directamente la probabilidad de predicción del token correspondiente a las cuatro letras A , B , C , y D , y toma la más grande. Responda la respuesta y calcule la tasa de precisión con la respuesta estándar. El modelo minimind en sí no utilizó un conjunto de datos más grande para el entrenamiento ni ajustó las instrucciones para responder preguntas de opción múltiple. Los resultados de la evaluación pueden usarse como referencia.
Por ejemplo, los detalles del resultado de minimind-small:
| Tipo | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | veintiuno | Veintidós | veintitrés | veinticuatro | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Datos | probabilidad_y_estadísticas | ley | biología_escuela_media | química_escuela_secundaria | fisica_escuela_secundaria | profesional_legal | secundaria_chino | historia_de_la_escuela_secundaria | contador_impuesto | historia_china_moderna | fisica_escuela_secundaria | historia_de_la_escuela_media | medicina_básica | Sistema operativo | lógica | ingeniero_electrico | funcionario_civil | idioma_y_literatura_china | programación_universitaria | contador | protección_planta | quimica_escuela_secundaria | metrología_ingeniero | medicina_veterinaria | marxismo | matemáticas_avanzadas | matemáticas_escuela_secundaria | administración de Empresas | pensamiento_mao_zedong | cultivo_ideológico_y_moral | economía_universitaria | guía_turistica_profesional | ingeniero_de_evaluación_de_impacto_ambiental | arquitectura_informática | planificador_urbano_y_rural | física_universitaria | matemáticas_escuela_secundaria | política_escuela_secundaria | médico | quimica_universitaria | biología_escuela_secundaria | geografía_escuela_secundaria | politica_escuela_secundaria | medicina_clinica | red_computadora | ciencia_deportiva | estudios_de_arte | calificación_profesor | matemáticas_discretas | educación_ciencia | bombero_ingeniero | geografía_de_escuela_media |
| Tipo | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | veintiuno | Veintidós | veintitrés | veinticuatro | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EJÉRCITO DE RESERVA | 3/18 | 5/24 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 29/10 | 7/31 | 6/21 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 6/21 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 31/9 | 1/12 |
| Exactitud | 16,67% | 20,83% | 19,05% | 36,84% | 26,32% | 8,70% | 21,05% | 30,00% | 20,41% | 17,39% | 21,05% | 18,18% | 5,26% | 15,79% | 18,18% | 18,92% | 23,40% | 21,74% | 27,03% | 18,37% | 31,82% | 20,00% | 12,50% | 26,09% | 26,32% | 26,32% | 22,22% | 24,24% | 33,33% | 26,32% | 30,91% | 34,48% | 22,58% | 28,57% | 23,91% | 26,32% | 15,79% | 21,05% | 26,53% | 12,50% | 26,32% | 21,05% | 28,57% | 27,27% | 10,53% | 10,53% | 42,42% | 27,27% | 37,50% | 24,14% | 29,03% | 8,33% |
总题数: 1346
总正确数: 316
总正确率: 23.48%
| categoría | correcto | cuenta_pregunta | exactitud |
|---|---|---|---|
| minimind-v1-pequeño | 344 | 1346 | 25,56% |
| minimente-v1 | 351 | 1346 | 26,08% |
### 模型擅长的领域:
1. 高中的化学:正确率为42.11%,是最高的一个领域。说明模型在这方面的知识可能较为扎实。
2. 离散数学:正确率为37.50%,属于数学相关领域,表现较好。
3. 教育科学:正确率为37.93%,说明模型在教育相关问题上的表现也不错。
4. 基础医学:正确率为36.84%,在医学基础知识方面表现也比较好。
5. 操作系统:正确率为36.84%,说明模型在计算机操作系统方面的表现较为可靠。
### 模型不擅长的领域:
1. 法律相关:如法律专业(8.70%)和税务会计(20.41%),表现相对较差。
2. 中学和大学的物理:如中学物理(26.32%)和大学物理(21.05%),模型在物理相关的领域表现不佳。
3. 高中的政治、地理:如高中政治(15.79%)和高中地理(21.05%),模型在这些领域的正确率较低。
4. 计算机网络与体系结构:如计算机网络(21.05%)和计算机体系结构(9.52%),在这些计算机专业课程上的表现也不够好。
5. 环境影响评估工程师:正确率仅为12.90%,在环境科学领域的表现也不理想。
### 总结:
- 擅长领域:化学、数学(特别是离散数学)、教育科学、基础医学、计算机操作系统。
- 不擅长领域:法律、物理、政治、地理、计算机网络与体系结构、环境科学。
这表明模型在涉及逻辑推理、基础科学和一些工程技术领域的问题上表现较好,但在人文社科、环境科学以及某些特定专业领域(如法律和税务)上表现较弱。如果要提高模型的性能,可能需要加强它在人文社科、物理、法律、以及环境科学等方面的训练。
./export_model.py puede exportar el modelo al formato de transformadores y enviarlo a huggingface
Dirección de la colección Huggingface de MiniMind: MiniMind
my_openai_api.py completa la interfaz de chat de openai_api, lo que facilita la conexión de sus propios modelos a interfaces de usuario de terceros como fastgpt, OpenWebUI, etc.
Descargue el archivo de peso del modelo de Huggingface
minimind (root dir)
├─minimind
| ├── config.json
| ├── generation_config.json
| ├── LMConfig.py
| ├── model.py
| ├── pytorch_model.bin
| ├── special_tokens_map.json
| ├── tokenizer_config.json
| ├── tokenizer.json
Iniciar el servidor de chat
python my_openai_api.pyInterfaz de servicio de prueba
python chat_openai_api.pyEjemplo de interfaz API, compatible con el formato API openai
curl http://ip:port/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "model-identifier",
"messages": [
{ "role": "user", "content": "世界上最高的山是什么?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
} ' 
Consejo
Si cree que MiniMind es útil para usted, puede agregar un artículo en GitHub. La extensión no es corta y el nivel es limitado. Las omisiones son inevitables. Puede intercambiar correcciones en Problemas o enviar proyectos de mejora de relaciones públicas. el motor para la mejora continua del proyecto.
Nota
Todo el mundo echa más leña al fuego. Si ha intentado entrenar un nuevo modelo MiniMind, puede compartir los pesos de su modelo en Discusiones o Problemas. Puede ser en tareas posteriores específicas o en campos verticales (como reconocimiento de emociones, médico o psicológico). , preguntas y respuestas financieras, legales, etc.) Nueva versión del modelo MiniMind También puede ser una nueva versión del modelo MiniMind después de una capacitación prolongada (como explorar secuencias de texto más largas, volúmenes más grandes (0.1B+) o conjuntos de datos más grandes. Cualquier intercambio se considera único y todos los intentos son valiosos y se alientan. ser descubierto a tiempo y organizado en la lista de reconocimientos. ¡Gracias nuevamente por todo su apoyo!
@ipfgao : ?Registro de pasos de entrenamiento
@chuanzhubin : ¿Comentarios de código línea por línea?
@WangRongsheng : ?Preprocesamiento de grandes conjuntos de datos
@pengqianhan : ?Un tutorial conciso
@RyanSunn : ?Registro de aprendizaje del proceso de razonamiento
Este repositorio tiene la licencia Apache-2.0.


