atari
1.0.0

Research Playground construido sobre el Atari Gym de OpenAI, preparado para implementar varios algoritmos de aprendizaje por refuerzo.
Puede emular cualquiera de los siguientes juegos:
['Asterix', 'Asteroides', 'MsPacman', 'Kaboom', 'BankHeist', 'Kangaroo', 'Skiing', 'FishingDerby', 'Krull', 'Berzerk', 'Tutankham', 'Zaxxon', ' Aventura', 'Riverraid', 'Ciempiés', 'Aventura', 'BeamRider', 'CrazyClimber', 'TimePilot', 'Carnival', 'Tennis', 'Seaquest', 'Bowling', 'SpaceInvaders', 'Freeway', 'YarsRevenge', 'RoadRunner', 'JourneyEscape', 'WizardOfWor', 'Gopher ', 'Breakout', 'StarGunner', 'Atlantis', 'DoubleDunk', 'Hero', 'BattleZone', 'Solaris', 'UpNDown', 'Frostbite', 'KungFuMaster', 'Pooyan', 'Pitfall', 'MontezumaRevenge', 'PrivateEye', 'AirRaid', 'Amidar', 'Robotank ', 'DemonAttack', 'Defender', 'NameThisGame', 'Phoenix', 'Gravitar', 'ElevatorAction', 'Pong', 'VideoPinball', 'IceHockey', 'Boxeo', 'Assault', 'Alien', 'Qbert', 'Enduro', 'ChopperCommand', 'Jamesbond']
Consulte el artículo correspondiente de Medium: Atari: ¿aprendizaje por refuerzo en profundidad? (Parte 1: DDQN)
El objetivo final de este proyecto es implementar y comparar varios enfoques de RL con juegos de Atari como denominador común.
pip install -r requirements.txt .python atari.py --help . * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
Red neuronal convolucional profunda de DeepMind
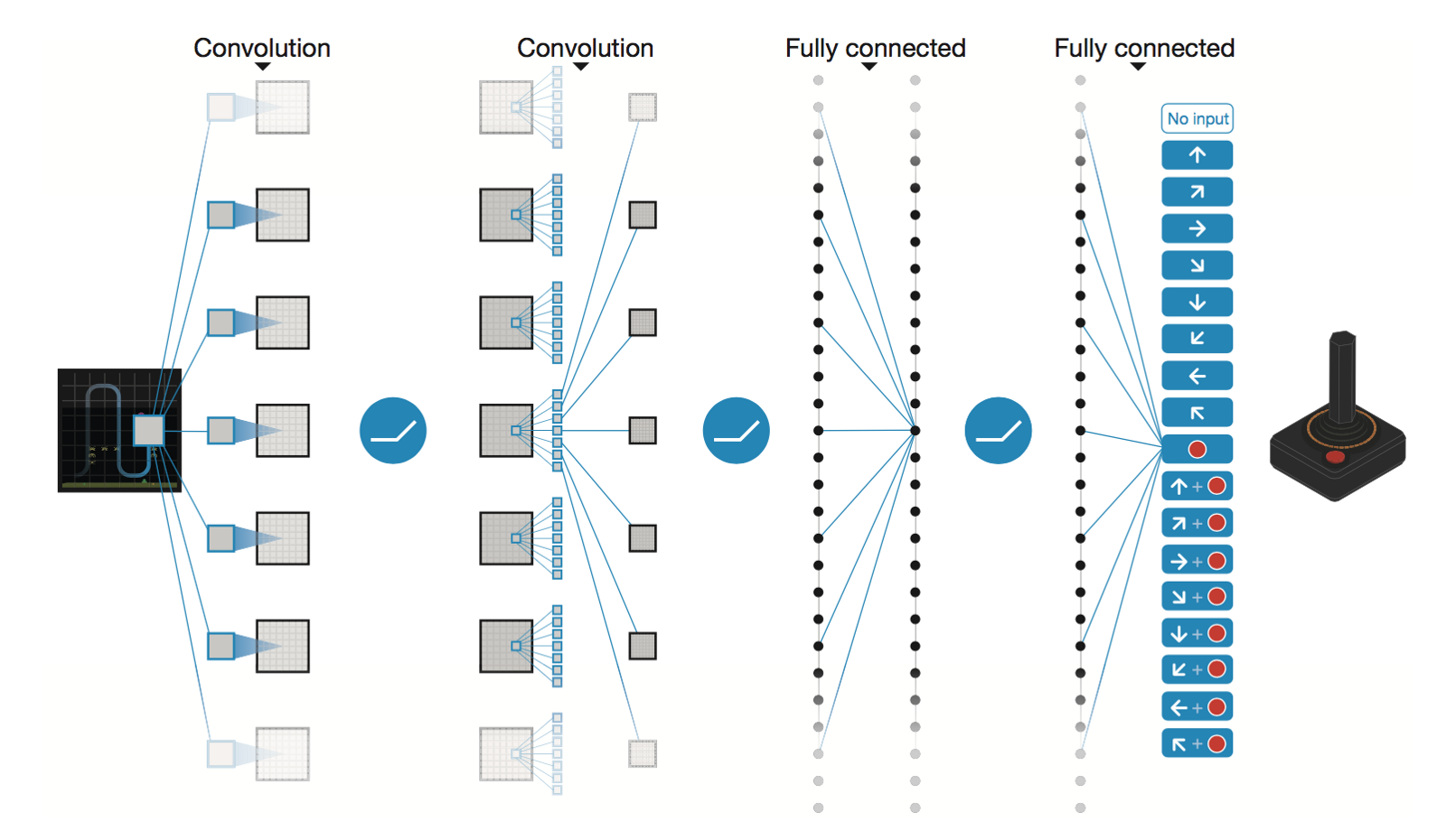
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
Después de 5 millones de pasos ( ~40 h en la GPU Tesla K80 o ~90 h en la CPU Intel i7 Quad-Core de 2,9 GHz):
Capacitación:
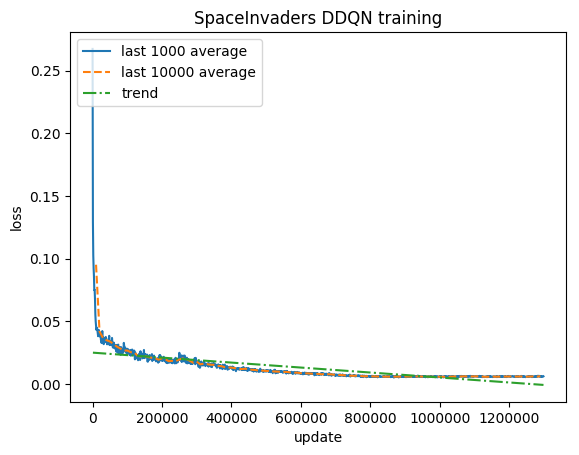
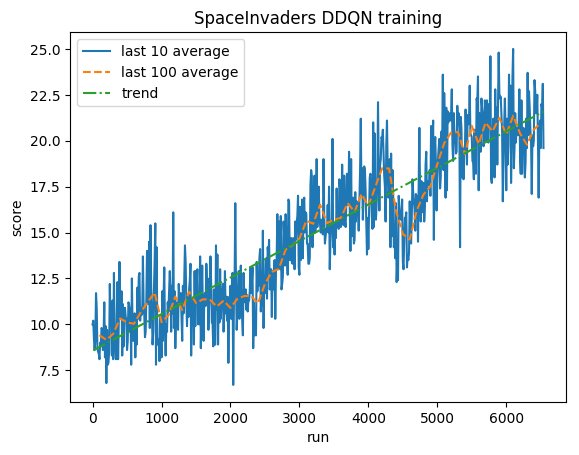
Puntuación normalizada: cada recompensa recortada a (-1, 1)
Pruebas:
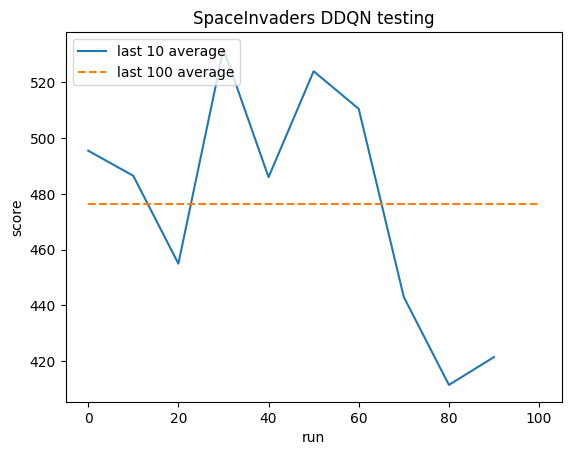
Promedio humano: ~372
Promedio DDQN: ~479 (128%)
Capacitación:
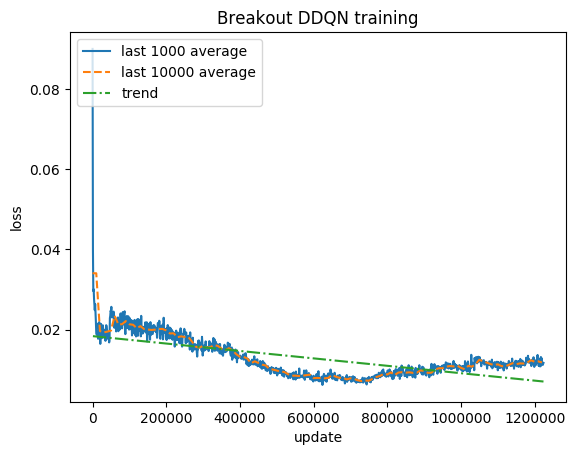
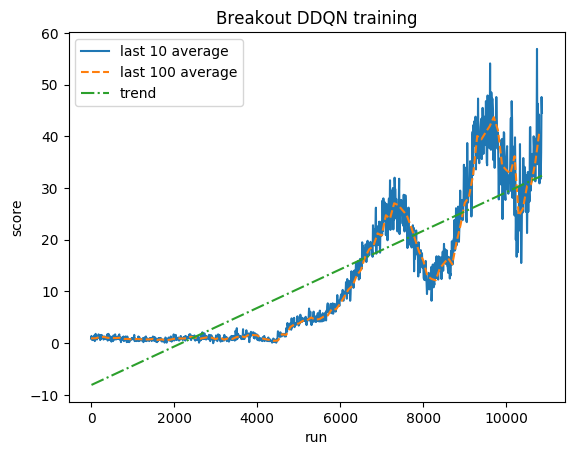
Puntuación normalizada: cada recompensa recortada a (-1, 1)
Pruebas:
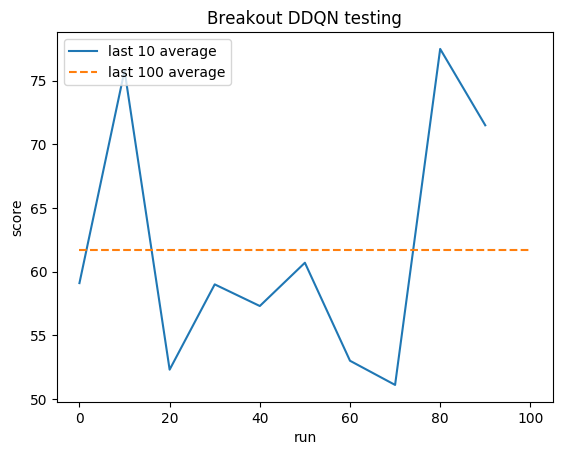
Promedio humano: ~28
Promedio de DDQN: ~62 (221%)
Capacitación:
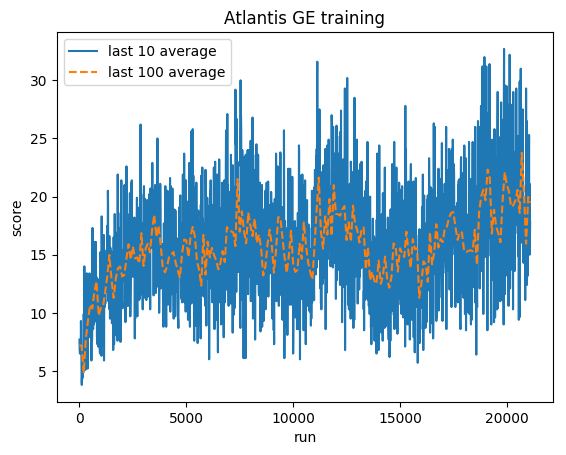
Puntuación normalizada: cada recompensa recortada a (-1, 1)
Pruebas:

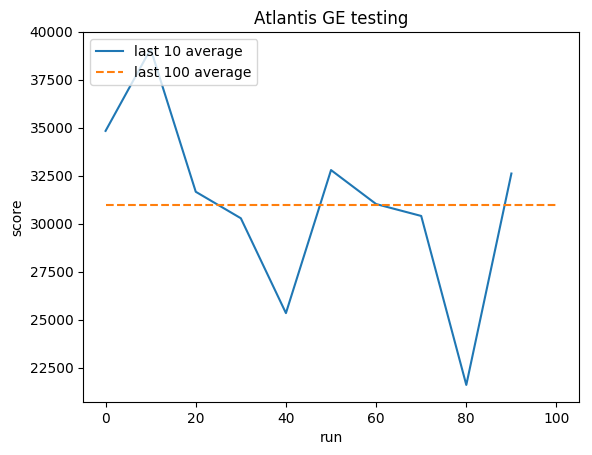
Promedio humano: ~29,000
Promedio de GE: 31.000 (106%)
Greg (Grzegorz) Surma
CARTERA
GITHUB
BLOG


