LongNet
0.4.8

Esta es una implementación de código abierto para el artículo LongNet: Scaling Transformers to 1,000,000,000 Tokens de Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei. LongNet es una variante de Transformer diseñada para escalar la longitud de la secuencia hasta más de mil millones de tokens sin sacrificar el rendimiento en secuencias más cortas.
pip install longnet Una vez que haya instalado LongNet, puede utilizar la clase DilatedAttention de la siguiente manera:
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerUn modelo de transformador totalmente listo para entrenar con bloques de transformadores dilatados con Feedforwards con Layernorm, SWIGLU y un bloque de transformadores en paralelo.
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
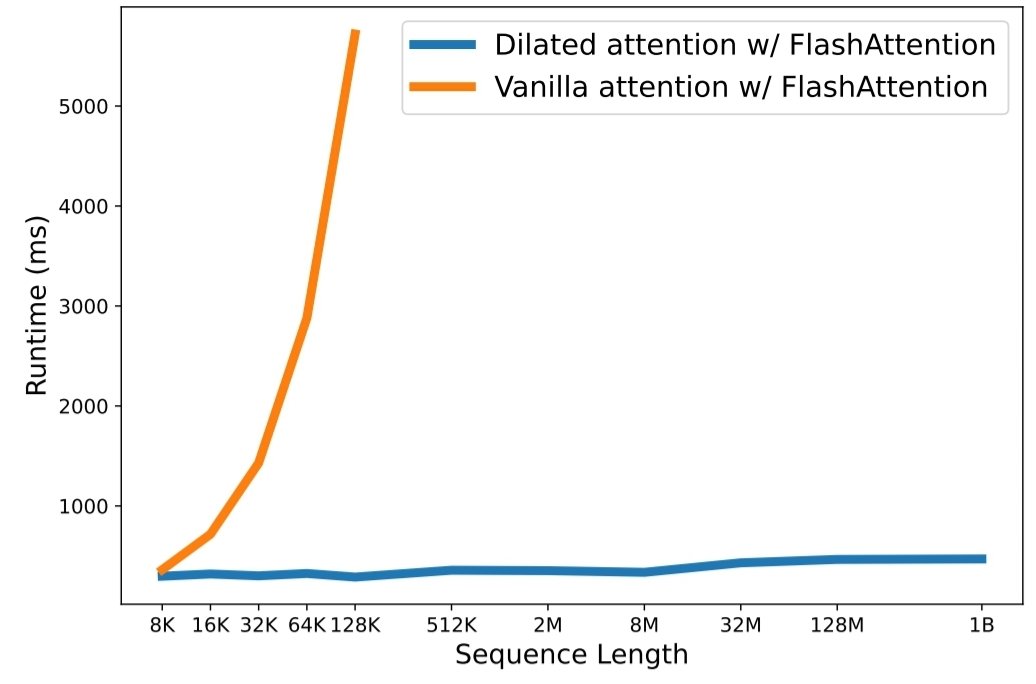
python3 train.py Escalar la longitud de la secuencia se ha convertido en un cuello de botella crítico en la era de los grandes modelos de lenguaje. Sin embargo, los métodos existentes luchan con la complejidad computacional o la expresividad del modelo, lo que restringe la longitud máxima de la secuencia. En este artículo, presentan LongNet, una variante de Transformer que puede escalar la longitud de la secuencia a más de mil millones de tokens, sin sacrificar el rendimiento en secuencias más cortas. En concreto, proponen la atención dilatada, que amplía exponencialmente el campo atento a medida que crece la distancia.
LongNet tiene importantes ventajas:
Los resultados del experimento demuestran que LongNet produce un rendimiento sólido tanto en el modelado de secuencias largas como en tareas de lenguaje general. Su trabajo abre nuevas posibilidades para modelar secuencias muy largas, por ejemplo, tratando un corpus completo o incluso toda Internet como una secuencia.
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

