pba
1.0.0
Nuevo: Visualice PBA y los aumentos aplicados con el cuaderno pba.ipynb .
Ahora con soporte para Python 3.
El aumento basado en la población (PBA) es un algoritmo que aprende de forma rápida y eficiente funciones de aumento de datos para el entrenamiento de redes neuronales. PBA iguala los resultados de última generación en CIFAR con mil veces menos computación, lo que permite a investigadores y profesionales aprender de manera efectiva nuevas políticas de aumento utilizando una única GPU de estación de trabajo.
Este repositorio contiene código para el trabajo "Aumento basado en la población: aprendizaje eficiente de cronogramas de aumento" (http://arxiv.org/abs/1905.05393) en TensorFlow y Python. Incluye entrenamiento de modelos con los cronogramas de aumento informados y descubrimiento de nuevos cronogramas de políticas de aumento.
Vea a continuación una visualización de nuestra estrategia de aumento.

El código es compatible con Python 2 y 3.
pip install -r requirements.txtbash datasets/cifar10.sh
bash datasets/cifar100.sh| Conjunto de datos | Modelo | Error de prueba (%) |
|---|---|---|
| CIFAR-10 | Wide-ResNet-28-10 | 2.58 |
| Agitar-Agitar (26 2x32d) | 2.54 | |
| Agitar-Agitar (26 2x96d) | 2.03 | |
| Agitar-Agitar (26 2x112d) | 2.03 | |
| PyramidNet+ShakeDrop | 1.46 | |
| CIFAR-10 reducido | Wide-ResNet-28-10 | 12,82 |
| Agitar-Agitar (26 2x96d) | 10.64 | |
| CIFAR-100 | Wide-ResNet-28-10 | 16,73 |
| Agitar-Agitar (26 2x96d) | 15.31 | |
| PyramidNet+ShakeDrop | 10.94 | |
| SVHN | Wide-ResNet-28-10 | 1.18 |
| Agitar-Agitar (26 2x96d) | 1.13 | |
| SVHN reducido | Wide-ResNet-28-10 | 7,83 |
| Agitar-Agitar (26 2x96d) | 6.46 |
Los scripts para reproducir los resultados se encuentran en scripts/table_*.sh . Se requiere un argumento, el nombre del modelo, para todos los scripts. Las opciones disponibles son las reportadas para cada conjunto de datos en la Tabla 2 del documento, entre las opciones: wrn_28_10, ss_32, ss_96, ss_112, pyramid_net . Los hiperparámetros también se encuentran dentro de cada archivo de script.
Por ejemplo, para reproducir los resultados de CIFAR-10 en Wide-ResNet-28-10:
bash scripts/table_1_cifar10.sh wrn_28_10Para reproducir resultados de SVHN reducido en Shake-Shake (26 2x96d):
bash scripts/table_4_svhn.sh rsvhn_ss_96Un buen lugar para comenzar es SVHN reducido en Wide-ResNet-28-10, que puede completarse en menos de 10 minutos en una GPU Titan XP y alcanza una precisión de prueba superior al 91 %.
Ejecutar los modelos más grandes en 1800 épocas puede requerir varios días de capacitación. Por ejemplo, CIFAR-10 PyramidNet+ShakeDrop tarda alrededor de 9 días en una GPU Tesla V100.
Ejecute la búsqueda de PBA en Wide-ResNet-40-2 con el archivo scripts/search.sh . Se requiere un argumento, el nombre del conjunto de datos. Las opciones son rsvhn o rcifar10 .
Se especifica un tamaño de GPU parcial para iniciar varias pruebas en la misma GPU. El SVHN reducido tarda aproximadamente una hora en una GPU Titan XP y el CIFAR-10 reducido tarda unas 5 horas.
CUDA_VISIBLE_DEVICES=0 bash scripts/search.sh rsvhn Las programaciones resultantes utilizadas en la búsqueda se pueden recuperar del directorio de resultados de Ray y los archivos de registro se pueden convertir en programaciones de políticas con la función parse_log() en pba/utils.py . Por ejemplo, el cronograma de políticas aprendido en CIFAR-10 reducido durante 200 épocas se divide en valores de hiperparámetros de probabilidad y magnitud (los dos valores para cada operación de aumento se fusionan) y se visualiza a continuación:
| Hiperparámetros de probabilidad a lo largo del tiempo | Hiperparámetros de magnitud a lo largo del tiempo |
|---|---|
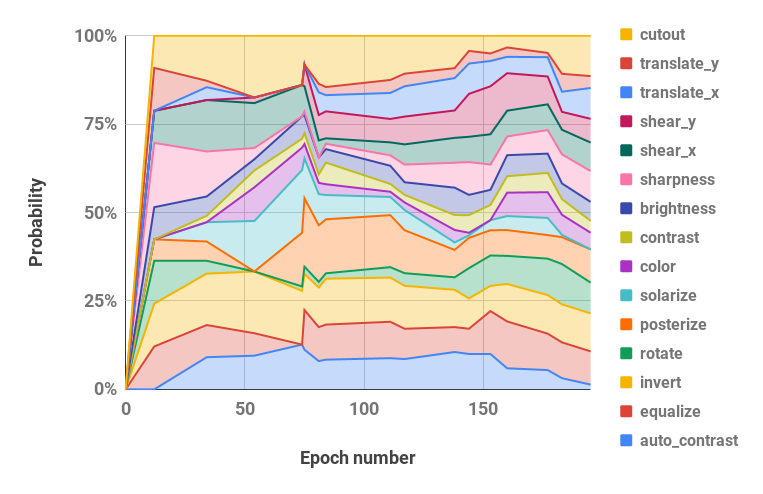 | 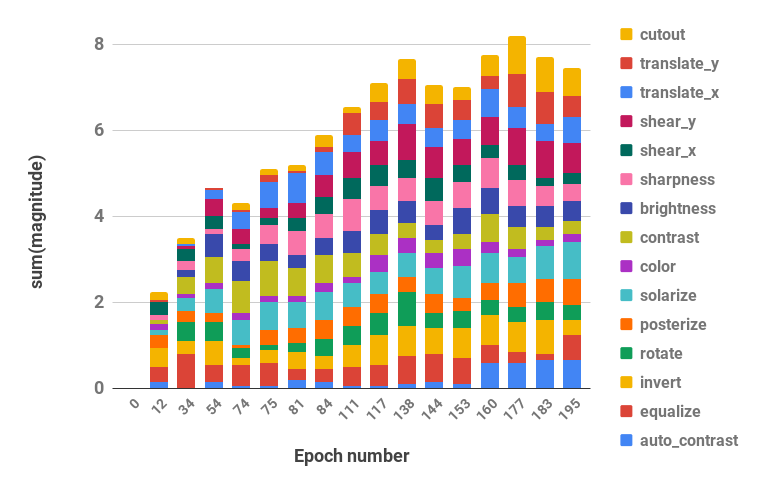 |
Si utiliza PBA en su investigación, cite:
@inproceedings{ho2019pba,
title = {Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules},
author = {Daniel Ho and
Eric Liang and
Ion Stoica and
Pieter Abbeel and
Xi Chen
},
booktitle = {ICML},
year = {2019}
}


