adeptRL
1.0.0
adept es un marco de aprendizaje por refuerzo diseñado para acelerar la investigación abstrayendo los desafíos de ingeniería asociados con el aprendizaje por refuerzo profundo. adepto proporciona:
Este código es de acceso temprano, espere algunas asperezas. Interfaces sujetas a cambios. Estaremos encantados de aceptar comentarios y contribuciones.
git clone https://github.com/heronsystems/adeptRL
cd adeptRL
pip install -e .[all]Desde la ventana acoplable:
Los registros de capacitación de un agente van a /tmp/adept_logs/ de forma predeterminada. El directorio de registro contiene el archivo tensorboard, los modelos guardados y otros metadatos.
# Local Mode (A2C)
# We recommend 4GB+ GPU memory, 8GB+ RAM, 4+ Cores
python -m adept.app local --env BeamRiderNoFrameskip-v4
# Distributed Mode (A2C, requires NCCL)
# We recommend 2+ GPUs, 8GB+ GPU memory, 32GB+ RAM, 4+ Cores
python -m adept.app distrib --env BeamRiderNoFrameskip-v4
# IMPALA (requires ray, resource intensive)
# We recommend 2+ GPUs, 8GB+ GPU memory, 32GB+ RAM, 4+ Cores
python -m adept.app actorlearner --env BeamRiderNoFrameskip-v4
# To see a full list of options:
python -m adept.app -h
python -m adept.app help < command >Utilice su propio agente, entorno, red o submódulo
"""
my_script.py
Train an agent on a single GPU.
"""
from adept . scripts . local import parse_args , main
from adept . network import NetworkModule , SubModule1D
from adept . agent import AgentModule
from adept . env import EnvModule
class MyAgent ( AgentModule ):
pass # Implement
class MyEnv ( EnvModule ):
pass # Implement
class MyNet ( NetworkModule ):
pass # Implement
class MySubModule1D ( SubModule1D ):
pass # Implement
if __name__ == '__main__' :
import adept
adept . register_agent ( MyAgent )
adept . register_env ( MyEnv )
adept . register_network ( MyNet )
adept . register_submodule ( MySubModule1D )
main ( parse_args ())python my_script.py --agent MyAgent --env env-id-1 --custom-network MyNetLocal (nodo único, GPU única)
Distribuido (multinodo, multi-GPU)
Arquitecturas de aprendizaje de actores ponderados por importancia, IMPALA (nodo único, GPU múltiple)
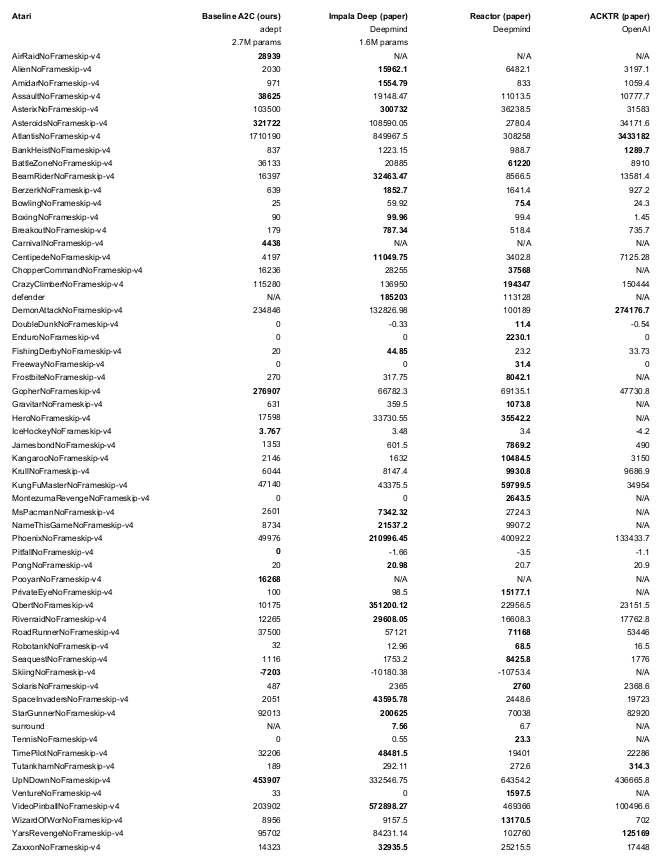
python -m adept.app local --logdir ~/local64_benchmark --eval -y --nb-step 50e6 --env <env-id> Tomamos prestados fragmentos del código de líneas de base y gimnasio de OpenAI. Indicamos dónde se hace esto.


