L2C
1.0.0
Una estrategia de clustering con redes neuronales profundas. Este artículo de blog proporciona una descripción general genérica.
Este repositorio proporciona la implementación en PyTorch de los esquemas de aprendizaje por transferencia (L2C) y dos criterios de aprendizaje útiles para la agrupación profunda:
*Se cambia el nombre de CCL
Este repositorio cubre las siguientes referencias:
@inproceedings{Hsu19_MCL,
title = {Multi-class classification without multi-class labels},
author = {Yen-Chang Hsu, Zhaoyang Lv, Joel Schlosser, Phillip Odom, Zsolt Kira},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2019},
url = {https://openreview.net/forum?id=SJzR2iRcK7}
}
@inproceedings{Hsu18_L2C,
title = {Learning to cluster in order to transfer across domains and tasks},
author = {Yen-Chang Hsu and Zhaoyang Lv and Zsolt Kira},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2018},
url = {https://openreview.net/forum?id=ByRWCqvT-}
}
@inproceedings{Hsu16_KCL,
title = {Neural network-based clustering using pairwise constraints},
author = {Yen-Chang Hsu and Zsolt Kira},
booktitle = {ICLR workshop},
year = {2016},
url = {https://arxiv.org/abs/1511.06321}
}
Este repositorio es compatible con PyTorch 1.0, Python 2.7, 3.6 y 3.7.
pip install -r requirements.txt # A quick trial:
python demo.py # Default Dataset:MNIST, Network:LeNet, Loss:MCL
python demo.py --loss KCL
# Lookup available options:
python demo.py -h
# For more examples:
./scripts/exp_supervised_MCL_vs_KCL.sh # Learn the Similarity Prediction Network (SPN) with Omniglot_background and then transfer to the 20 alphabets in Omniglot_evaluation.
# Default loss is MCL with an unknown number of clusters (Set a large cluster number, i.e., k=100)
# It takes about half an hour to finish.
python demo_omniglot_transfer.py
# An example of using KCL and set k=gt_#cluster
python demo_omniglot_transfer.py --loss KCL --num_cluster -1
# Lookup available options:
python demo_omniglot_transfer.py -h
# Other examples:
./scripts/exp_unsupervised_transfer_Omniglot.sh| Conjunto de datos | gt #clase | KCL (k=100) | LCM (k=100) | KCL (k=gt) | MCL (k=gt) |
|---|---|---|---|---|---|
| Angelical | 20 | 73,2% | 82,2% | 89,0% | 91,7% |
| Atemayar_Qelisayer | 26 | 73,3% | 89,2% | 82,5% | 86,0% |
| atlante | 26 | 65,5% | 83,3% | 89,4% | 93,5% |
| Aurek_Besh | 26 | 88,4% | 92,8% | 91,5% | 92,4% |
| avesta | 26 | 79,0% | 85,8% | 85,4% | 86,1% |
| Ge_ez | 26 | 77,1% | 84,0% | 85,4% | 86,6% |
| glagolítico | 45 | 83,9% | 85,3% | 84,9% | 87,4% |
| Gurmukhi | 45 | 78,8% | 78,7% | 77,0% | 78,0% |
| canarés | 41 | 64,6% | 81,1% | 73,3% | 81,2% |
| Keble | 26 | 91,4% | 95,1% | 94,7% | 94,3% |
| malayalam | 47 | 73,5% | 75,0% | 72,7% | 73,0% |
| manipuri | 40 | 82,8% | 81,2% | 85,8% | 81,5% |
| mongol | 30 | 84,7% | 89,0% | 88,3% | 90,2% |
| Antiguo_iglesia_eslavo_cirílico | 45 | 89,9% | 90,7% | 88,7% | 89,8% |
| Oriya | 46 | 56,5% | 73,4% | 63,2% | 75,3% |
| Sylheti | 28 | 61,8% | 68,2% | 69,8% | 80,6% |
| siríaco_serto | 23 | 72,1% | 82,0% | 85,8% | 89,8% |
| Tengwar | 25 | 67,7% | 76,4% | 82,5% | 85,5% |
| tibetano | 42 | 81,8% | 80,2% | 84,3% | 81,9% |
| ULOG | 26 | 53,3% | 77,1% | 73,0% | 89,1% |
| --Promedio-- | 75,0% | 82,5% | 82,4% | 85,7% |
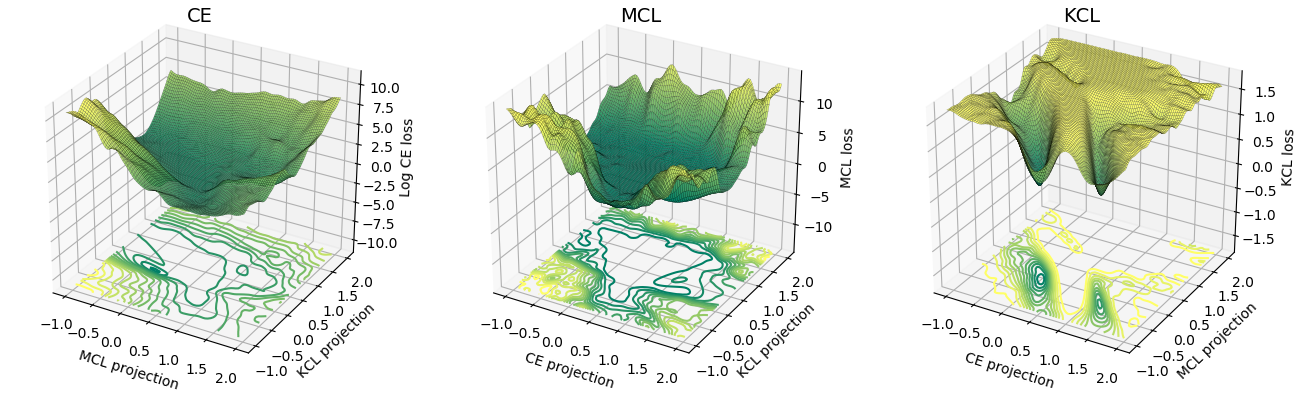
La superficie de pérdida de MCL es más similar a la entropía cruzada (CE) que la de KCL. Empíricamente, MCL convergió más rápido que KCL. Para obtener más información, consulte el documento de ICLR.
@article{Hsu18_InsSeg,
title = {Learning to Cluster for Proposal-Free Instance Segmentation},
author = {Yen-Chang Hsu, Zheng Xu, Zsolt Kira, Jiawei Huang},
booktitle = {accepted to the International Joint Conference on Neural Networks (IJCNN)},
year = {2018},
url = {https://arxiv.org/abs/1803.06459}
}
Este trabajo fue apoyado por la Fundación Nacional de Ciencias y la Iniciativa Nacional de Robótica (subvención n.° IIS-1426998) y el programa Lifelong Learning Machines (L2M) de DARPA, en virtud del acuerdo cooperativo HR0011-18-2-001.


