cnn svm
1.0.0
Este proyecto se inspiró en el aprendizaje profundo de Y. Tang utilizando máquinas de vectores de soporte lineal (2013).
El documento completo sobre este proyecto se puede leer en arXiv.org.
Las redes neuronales convolucionales (CNN) son similares a las redes neuronales "ordinarias" en el sentido de que están formadas por capas ocultas que consisten en neuronas con parámetros "aprendibles". Estas neuronas reciben entradas, realizan un producto escalar y luego lo siguen con una no linealidad. Toda la red expresa el mapeo entre los píxeles de la imagen sin procesar y sus puntuaciones de clase. Convencionalmente, la función Softmax es el clasificador utilizado en la última capa de esta red. Sin embargo, se han realizado estudios (Alalshekmubarak y Smith, 2013; Agarap, 2017; Tang, 2013) para desafiar esta norma. Los estudios citados introducen el uso de una máquina de vectores de soporte lineal (SVM) en una arquitectura de red neuronal artificial. Este proyecto es otra visión del tema y está inspirado en (Tang, 2013). Los datos empíricos han demostrado que el modelo CNN-SVM pudo lograr una precisión de prueba de ~99,04 % utilizando el conjunto de datos MNIST (LeCun, Cortes y Burges, 2010). Por otro lado, CNN-Softmax pudo lograr una precisión de prueba de ~99,23 % utilizando el mismo conjunto de datos. Ambos modelos también se probaron en el conjunto de datos Fashion-MNIST publicado recientemente (Xiao, Rasul y Vollgraf, 2017), que se supone que es un conjunto de datos de clasificación de imágenes más difícil que MNIST (Zalandoresearch, 2017). Este resultó ser el caso, ya que CNN-SVM alcanzó una precisión de prueba de ~90,72%, mientras que CNN-Softmax alcanzó una precisión de prueba de ~91,86%. Dichos resultados pueden mejorarse si se emplearan técnicas de preprocesamiento de datos en los conjuntos de datos y si el modelo CNN base fuera relativamente más sofisticado que el utilizado en este estudio.
Primero, clona el proyecto.
git clone https://github.com/AFAgarap/cnn-svm.git/ Ejecute setup.sh para asegurarse de que las bibliotecas de requisitos previos estén instaladas en el entorno.
sudo chmod +x setup.sh
./setup.shParámetros del programa.
usage: main.py [-h] -m MODEL -d DATASET [-p PENALTY_PARAMETER] -c
CHECKPOINT_PATH -l LOG_PATH
CNN & CNN-SVM for Image Classification
optional arguments:
-h, --help show this help message and exit
Arguments:
-m MODEL, --model MODEL
[1] CNN-Softmax, [2] CNN-SVM
-d DATASET, --dataset DATASET
path of the MNIST dataset
-p PENALTY_PARAMETER, --penalty_parameter PENALTY_PARAMETER
the SVM C penalty parameter
-c CHECKPOINT_PATH, --checkpoint_path CHECKPOINT_PATH
path where to save the trained model
-l LOG_PATH, --log_path LOG_PATH
path where to save the TensorBoard logs Luego, vaya al directorio del repositorio y ejecute el módulo main.py según los parámetros deseados.
cd cnn-svm
python3 main.py --model 2 --dataset ./MNIST_data --penalty_parameter 1 --checkpoint_path ./checkpoint --log_path ./logsLos hiperparámetros utilizados en este proyecto se asignaron manualmente y no mediante optimización.
| Hiperparámetros | CNN-Softmax | CNN-SVM |
|---|---|---|
| Tamaño del lote | 128 | 128 |
| Tasa de aprendizaje | 1e-3 | 1e-3 |
| Pasos | 10000 | 10000 |
| SVM C | N / A | 1 |
Los experimentos se realizaron en una computadora portátil con CPU Intel Core(TM) i5-6300HQ a 2,30 GHz x 4, 16 GB de RAM DDR3 y GPU NVIDIA GeForce GTX 960M de 4 GB DDR5.
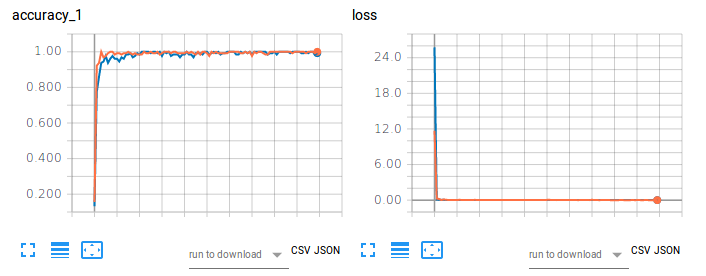
Figura 1. Precisión del entrenamiento (izquierda) y pérdida (derecha) de CNN-Softmax y CNN-SVM en la clasificación de imágenes utilizando MNIST.
El gráfico naranja se refiere a la precisión del entrenamiento y la pérdida de CNN-Softmax, con una precisión de prueba del 99,22999739646912%. Por otro lado, el gráfico azul se refiere a la precisión del entrenamiento y la pérdida de CNN-SVM, con una precisión de prueba del 99,04000163078308%. Los resultados no corroboran los hallazgos de Tang (2017) para la clasificación de dígitos escritos a mano del MNIST. Esto puede atribuirse al hecho de que no se realizó ningún preprocesamiento de datos ni reducción de dimensionalidad en el conjunto de datos de este proyecto.
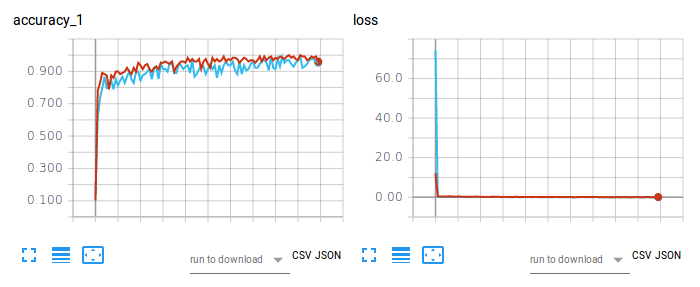
Figura 2. Precisión del entrenamiento (izquierda) y pérdida (derecha) de CNN-Softmax y CNN-SVM en la clasificación de imágenes utilizando Fashion-MNIST.
El gráfico rojo se refiere a la precisión del entrenamiento y la pérdida de CNN-Softmax, con una precisión de prueba del 91,86000227928162%. Por otro lado, el gráfico azul claro se refiere a la precisión del entrenamiento y la pérdida de CNN-SVM, con una precisión de prueba del 90,71999788284302%. El resultado de CNN-Softmax corrobora el hallazgo de zalandoresearch en Fashion-MNIST.
Para citar el artículo, utilice la siguiente entrada de BibTex:
@article{agarap2017architecture,
title={An Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification},
author={Agarap, Abien Fred},
journal={arXiv preprint arXiv:1712.03541},
year={2017}
}
Para citar el repositorio/software, utilice la siguiente entrada BibTex:
@misc{abien_fred_agarap_2017_1098369,
author = {Abien Fred Agarap},
title = {AFAgarap/cnn-svm v0.1.0-alpha},
month = dec,
year = 2017,
doi = {10.5281/zenodo.1098369},
url = {https://doi.org/10.5281/zenodo.1098369}
}
Copyright 2017-2020 Abien Fred Agarap
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


