soundstorm pytorch
0.5.0
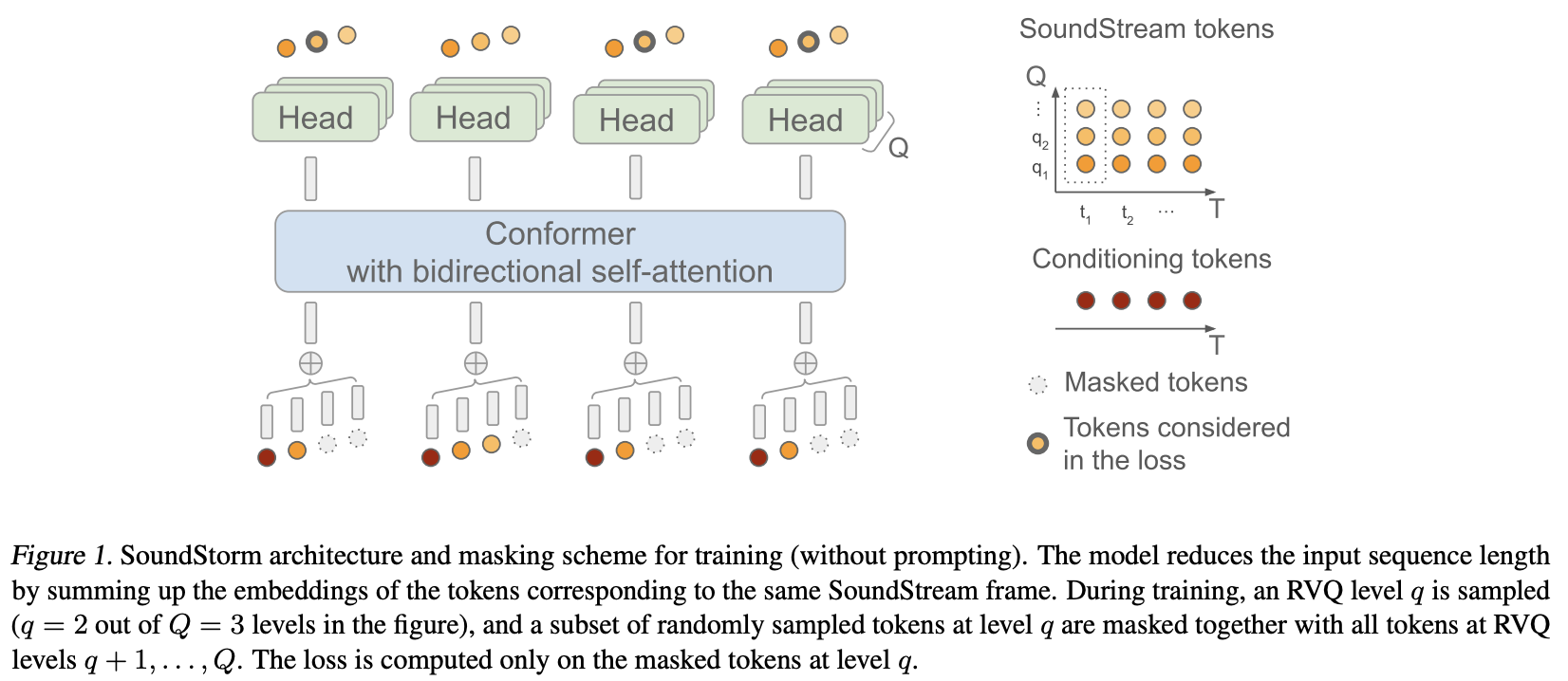
Implementación de SoundStorm, Generación Eficiente de Audio Paralelo de Google Deepmind, en Pytorch.
Básicamente, aplicaron MaskGiT a los códigos cuantificados vectoriales residuales de Soundstream. La arquitectura de transformador que eligieron utilizar es una que encaja bien con el dominio del audio, llamada Conformer.
Página del proyecto
Estabilidad y ? Huggingface por sus generosos patrocinios para trabajar en investigaciones de inteligencia artificial de vanguardia y de código abierto.
Lucas Newman por sus numerosas contribuciones, incluido el código de entrenamiento inicial, la lógica de indicaciones acústicas y la decodificación del cuantificador por nivel.
? Accelerate para proporcionar una solución simple y poderosa para la capacitación
Einops por la abstracción indispensable que hace que la construcción de redes neuronales sea divertida, fácil y edificante
¡Steven Hillis por enviar la estrategia de enmascaramiento correcta y por verificar que el repositorio funciona!
Lucas Newman por entrenar básicamente un pequeño Soundstorm funcional con modelos en múltiples repositorios, demostrando que todo funciona de un extremo a otro. Los modelos incluyen SoundStream, Text-to-Semantic T5 y, finalmente, el transformador SoundStorm aquí.
@Jiang-Stan por identificar un error crítico en el desenmascaramiento iterativo.
$ pip install soundstorm-pytorch import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
model = SoundStorm (
conformer ,
steps = 18 , # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# get your pre-encoded codebook ids from the soundstream from a lot of raw audio
codes = torch . randint ( 0 , 1024 , ( 2 , 1024 , 12 )) # (batch, seq, num residual VQ)
# do the below in a loop for a ton of data
loss , _ = model ( codes )
loss . backward ()
# model can now generate in 18 steps. ~2 seconds sounds reasonable
generated = model . generate ( 1024 , batch_size = 2 ) # (2, 1024) Para entrenar directamente con audio sin formato, debe pasar su SoundStream previamente entrenado a SoundStorm . Puedes entrenar tu propio SoundStream en audiolm-pytorch.
import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper , Conformer , SoundStream
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
soundstream = SoundStream (
codebook_size = 1024 ,
rq_num_quantizers = 12 ,
attn_window_size = 128 ,
attn_depth = 2
)
model = SoundStorm (
conformer ,
soundstream = soundstream # pass in the soundstream
)
# find as much audio you'd like the model to learn
audio = torch . randn ( 2 , 10080 )
# course it through the model and take a gazillion tiny steps
loss , _ = model ( audio )
loss . backward ()
# and now you can generate state-of-the-art speech
generated_audio = model . generate ( seconds = 30 , batch_size = 2 ) # generate 30 seconds of audio (it will calculate the length in seconds based off the sampling frequency and cumulative downsamples in the soundstream passed in above) La conversión de texto a voz completa dependerá de un transformador codificador/decodificador TextToSemantic capacitado. Luego cargará los pesos y los pasará a SoundStorm como spear_tts_text_to_semantic
Este es un trabajo en progreso, ya que spear-tts-pytorch solo tiene la arquitectura del modelo completa, y no la lógica de preentrenamiento + pseudoetiquetado + retrotraducción.
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic (
dim = 512 ,
source_depth = 12 ,
target_depth = 12 ,
num_text_token_ids = 50000 ,
num_semantic_token_ids = 20000 ,
use_openai_tokenizer = True
)
# load the trained text-to-semantic transformer
text_to_semantic . load ( '/path/to/trained/model.pt' )
# pass it into the soundstorm
model = SoundStorm (
conformer ,
soundstream = soundstream ,
spear_tts_text_to_semantic = text_to_semantic
). cuda ()
# and now you can generate state-of-the-art speech
generated_speech = model . generate (
texts = [
'the rain in spain stays mainly in the plain' ,
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - raw waveform decoded from soundstream integrar flujo de sonido
al generar, y la duración se puede definir en segundos (tiene en cuenta la frecuencia de muestreo, etc.)
asegúrese de que se admita rvq agrupado. incrustaciones concat en lugar de suma en la dimensión del grupo
simplemente copie el conformador y rehaga la incrustación posicional relativa de Shaw con incrustación rotativa. Ya nadie usa shaw.
atención flash predeterminada a verdadero
elimine la norma por lotes y simplemente use la norma por capas, pero después del chasquido (como en el documento normativo)
entrenador con aceleración - gracias a @lucasnewman
permitir el entrenamiento y la generación de secuencias de longitud variable, pasando mask hacia forward y generate
Opción para devolver la lista de archivos de audio al generar.
conviértalo en una herramienta de línea de comando
agregar atención cruzada y condicionamiento normativo de capa adaptativa
@misc { borsos2023soundstorm ,
title = { SoundStorm: Efficient Parallel Audio Generation } ,
author = { Zalán Borsos and Matt Sharifi and Damien Vincent and Eugene Kharitonov and Neil Zeghidour and Marco Tagliasacchi } ,
year = { 2023 } ,
eprint = { 2305.09636 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

