rotary embedding torch
0.8.6
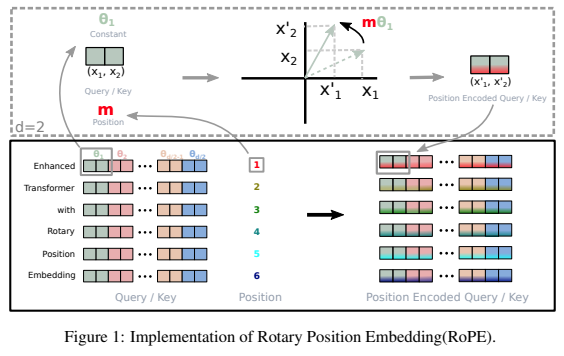
Una biblioteca independiente para agregar incrustaciones rotativas a transformadores en Pytorch, luego de su éxito como codificación posicional relativa. Específicamente, hará que rotar información en cualquier eje de un tensor sea fácil y eficiente, ya sea posicional fijo o aprendido. Esta biblioteca le brindará resultados de última generación para la incrustación posicional, a bajo costo.
Mi instinto también me dice que hay algo más en las rotaciones que puede explotarse en redes neuronales artificiales.
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usualSi realiza todos los pasos anteriores correctamente, debería ver una mejora espectacular durante el entrenamiento.
Cuando se trata de cachés de clave/valor en la inferencia, la posición de la consulta debe compensarse con key_value_seq_length - query_seq_length
Para facilitar esto, utilice el método rotate_queries_with_cached_keys
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )También puedes hacer esto manualmente así.
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])Para facilitar el uso de la incrustación posicional relativa axial de n dimensiones, es decir. transformadores de vídeo
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k ) En este artículo, pudieron solucionar el problema de extrapolación de longitud con incrustaciones rotativas dándole una decadencia similar a ALiBi. Llamaron a esta técnica XPos y puedes usarla configurando use_xpos = True en la inicialización.
Esto sólo se puede utilizar para transformadores autorregresivos.
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )Este artículo de MetaAI propone simplemente ajustar las interpolaciones de las posiciones de la secuencia para extenderlas a una longitud de contexto más larga para modelos previamente entrenados. Muestran que esto funciona mucho mejor que simplemente realizar un ajuste fino en las mismas posiciones de la secuencia pero ampliadas más.
Puede usar esto configurando interpolate_factor en la inicialización en un valor mayor que 1. (por ejemplo, si el modelo previamente entrenado se entrenó en 2048, establecer interpolate_factor = 2. permitiría un ajuste fino a 2048 x 2. = 4096 ).
Actualización: alguien en la comunidad ha informado que no funciona bien. por favor envíeme un correo electrónico si ve un resultado positivo o negativo
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

