point transformer pytorch
0.1.5
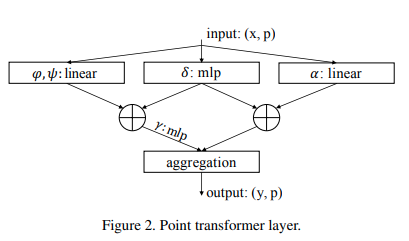
Implementación de la capa de autoatención de Point Transformer, en Pytorch. El circuito simple anterior parecía haber permitido a su grupo superar todos los métodos anteriores en clasificación y segmentación de nubes de puntos.
$ pip install point-transformer-pytorch import torch
from point_transformer_pytorch import PointTransformerLayer
attn = PointTransformerLayer (
dim = 128 ,
pos_mlp_hidden_dim = 64 ,
attn_mlp_hidden_mult = 4
)
feats = torch . randn ( 1 , 16 , 128 )
pos = torch . randn ( 1 , 16 , 3 )
mask = torch . ones ( 1 , 16 ). bool ()
attn ( feats , pos , mask = mask ) # (1, 16, 128)Este tipo de atención vectorial es mucho más cara que la tradicional. En el artículo, utilizaron k vecinos más cercanos en los puntos para excluir la atención en puntos lejanos. Puedes hacer lo mismo con una única configuración adicional.
import torch
from point_transformer_pytorch import PointTransformerLayer
attn = PointTransformerLayer (
dim = 128 ,
pos_mlp_hidden_dim = 64 ,
attn_mlp_hidden_mult = 4 ,
num_neighbors = 16 # only the 16 nearest neighbors would be attended to for each point
)
feats = torch . randn ( 1 , 2048 , 128 )
pos = torch . randn ( 1 , 2048 , 3 )
mask = torch . ones ( 1 , 2048 ). bool ()
attn ( feats , pos , mask = mask ) # (1, 16, 128) @misc { zhao2020point ,
title = { Point Transformer } ,
author = { Hengshuang Zhao and Li Jiang and Jiaya Jia and Philip Torr and Vladlen Koltun } ,
year = { 2020 } ,
eprint = { 2012.09164 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

