audiolm pytorch
2.2.3
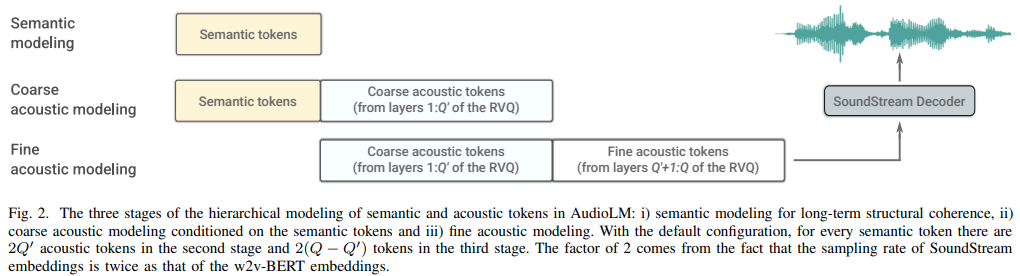
Implementación de AudioLM, un enfoque de modelado de lenguaje para la generación de audio de Google Research, en Pytorch
También se amplía el trabajo de acondicionamiento con guiado libre de clasificador con T5. Esto permite convertir texto a audio o TTS, algo que no se ofrece en el documento. Sí, esto significa que VALL-E se puede entrenar desde este repositorio. Es esencialmente lo mismo.
Únase si está interesado en replicar este trabajo al aire libre.
Este repositorio ahora también contiene una versión de SoundStream con licencia del MIT. También es compatible con EnCodec, que también tiene licencia MIT en el momento de escribir este artículo.
Actualización: AudioLM se utilizó esencialmente para "resolver" la generación de música en el nuevo MusicLM
En el futuro, este clip de película ya no tendría ningún sentido. En su lugar, simplemente solicitarías una IA.
Stability.ai por el generoso patrocinio para trabajar y abrir la investigación de vanguardia en inteligencia artificial
? Huggingface por sus increíbles bibliotecas de aceleración y transformadores.
MetaAI para Fairseq y la licencia liberal
@eonglints y Joseph por ofrecer su asesoramiento profesional y experiencia, así como solicitudes de extracción.
@djqualia, @yigityu, @inspirit y @BlackFox1197 por ayudar con la depuración de soundstream
¡Allen y LWprogramming por revisar el código y enviar correcciones de errores!
Ilya por encontrar un problema con la reducción de resolución del discriminador de múltiples escalas y por las mejoras en el entrenador de flujo de sonido
Andrey por identificar una pérdida faltante en el flujo de sonido y guiarme a través de los hiperparámetros del espectrograma mel adecuados.
Alejandro e Ilya por compartir sus resultados con Soundstream de capacitación y por resolver algunos problemas con las incorporaciones posicionales de atención local.
¡Programación LW para agregar compatibilidad con Encodec!
¡LWprogramming para encontrar un problema con el manejo del token EOS al muestrear desde FineTransformer !
@YoungloLee por identificar un gran error en la convolución causal 1d del flujo de sonido relacionado con el relleno que no tiene en cuenta los avances.
Hayden por señalar algunas discrepancias en el discriminador multiescala de Soundstream
$ pip install audiolm-pytorchHay dos opciones para el códec neuronal. Si desea utilizar el codificador de 24 kHz previamente entrenado, simplemente cree un objeto codificador de la siguiente manera:
from audiolm_pytorch import EncodecWrapper
encodec = EncodecWrapper ()
# Now you can use the encodec variable in the same way you'd use the soundstream variables below. De lo contrario, para ser más fiel al documento original, puede utilizar SoundStream . Primero, SoundStream necesita entrenarse en un gran corpus de datos de audio.
from audiolm_pytorch import SoundStream , SoundStreamTrainer
soundstream = SoundStream (
codebook_size = 4096 ,
rq_num_quantizers = 8 ,
rq_groups = 2 , # this paper proposes using multi-headed residual vector quantization - https://arxiv.org/abs/2305.02765
use_lookup_free_quantizer = True , # whether to use residual lookup free quantization - there are now reports of successful usage of this unpublished technique
use_finite_scalar_quantizer = False , # whether to use residual finite scalar quantization
attn_window_size = 128 , # local attention receptive field at bottleneck
attn_depth = 2 # 2 local attention transformer blocks - the soundstream folks were not experts with attention, so i took the liberty to add some. encodec went with lstms, but attention should be better
)
trainer = SoundStreamTrainer (
soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 4 ,
grad_accum_every = 8 , # effective batch size of 32
data_max_length_seconds = 2 , # train on 2 second audio
num_train_steps = 1_000_000
). cuda ()
trainer . train ()
# after a lot of training, you can test the autoencoding as so
soundstream . eval () # your soundstream must be in eval mode, to avoid having the residual dropout of the residual VQ necessary for training
audio = torch . randn ( 10080 ). cuda ()
recons = soundstream ( audio , return_recons_only = True ) # (1, 10080) - 1 channel Su SoundStream entrenado puede usarse como tokenizador genérico para audio.
audio = torch . randn ( 1 , 512 * 320 )
codes = soundstream . tokenize ( audio )
# you can now train anything with the codebook ids
recon_audio_from_codes = soundstream . decode_from_codebook_indices ( codes )
# sanity check
assert torch . allclose (
recon_audio_from_codes ,
soundstream ( audio , return_recons_only = True )
) También puede utilizar transmisiones de sonido específicas de AudioLM y MusicLM importando AudioLMSoundStream y MusicLMSoundStream respectivamente.
from audiolm_pytorch import AudioLMSoundStream , MusicLMSoundStream
soundstream = AudioLMSoundStream (...) # say you want the hyperparameters as in Audio LM paper
# rest is the same as above A partir de la versión 0.17.0 , ahora puede invocar el método de clase en SoundStream para cargar desde archivos de puntos de control, sin tener que recordar sus configuraciones.
from audiolm_pytorch import SoundStream
soundstream = SoundStream . init_and_load_from ( './path/to/checkpoint.pt' ) Para utilizar el seguimiento de pesos y sesgos, primero configure use_wandb_tracking = True en SoundStreamTrainer , luego haga lo siguiente
trainer = SoundStreamTrainer (
soundstream ,
...,
use_wandb_tracking = True
)
# wrap .train() with contextmanager, specifying project and run name
with trainer . wandb_tracker ( project = 'soundstream' , run = 'baseline' ):
trainer . train () Luego es necesario entrenar tres transformadores separados ( SemanticTransformer , CoarseTransformer , FineTransformer ).
ex. SemanticTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
# hubert checkpoints can be downloaded at
# https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
flash_attn = True
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () ex. CoarseTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SoundStream , CoarseTransformer , CoarseTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
coarse_transformer = CoarseTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
codebook_size = 1024 ,
num_coarse_quantizers = 3 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = CoarseTransformerTrainer (
transformer = coarse_transformer ,
codec = soundstream ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train () ex. FineTransformer
import torch
from audiolm_pytorch import SoundStream , FineTransformer , FineTransformerTrainer
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
fine_transformer = FineTransformer (
num_coarse_quantizers = 3 ,
num_fine_quantizers = 5 ,
codebook_size = 1024 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = FineTransformerTrainer (
transformer = fine_transformer ,
codec = soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()Todos juntos ahora
from audiolm_pytorch import AudioLM
audiolm = AudioLM (
wav2vec = wav2vec ,
codec = soundstream ,
semantic_transformer = semantic_transformer ,
coarse_transformer = coarse_transformer ,
fine_transformer = fine_transformer
)
generated_wav = audiolm ( batch_size = 1 )
# or with priming
generated_wav_with_prime = audiolm ( prime_wave = torch . randn ( 1 , 320 * 8 ))
# or with text condition, if given
generated_wav_with_text_condition = audiolm ( text = [ 'chirping of birds and the distant echos of bells' ])Actualización: Parece que esto funcionará, dado 'VALL-E'
ex. Transformador semántico
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = 500 ,
dim = 1024 ,
depth = 6 ,
has_condition = True , # this will have to be set to True
cond_as_self_attn_prefix = True # whether to condition as prefix to self attention, instead of cross attention, as was done in 'VALL-E' paper
). cuda ()
# mock text audio dataset (as an example)
# you will have to extend your own from `Dataset`, and return an audio tensor as well as a string (the audio description) in any order (the framework will autodetect and route it into the transformer)
from torch . utils . data import Dataset
class MockTextAudioDataset ( Dataset ):
def __init__ ( self , length = 100 , audio_length = 320 * 32 ):
super (). __init__ ()
self . audio_length = audio_length
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
mock_audio = torch . randn ( self . audio_length )
mock_caption = 'audio caption'
return mock_caption , mock_audio
dataset = MockTextAudioDataset ()
# instantiate semantic transformer trainer and train
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
dataset = dataset ,
batch_size = 4 ,
grad_accum_every = 8 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()
# after much training above
sample = trainer . generate ( text = [ 'sound of rain drops on the rooftops' ], batch_size = 1 , max_length = 2 ) # (1, < 128) - may terminate early if it detects [eos] ¿Porque todas las clases de entrenador utilizan? Acelerador, puedes realizar fácilmente un entrenamiento de múltiples gpu usando el comando accelerate como tal.
En la raíz del proyecto
$ accelerate configLuego, en el mismo directorio
$ accelerate launch train . py transformador grueso completo
use fairseq vq-wav2vec para incrustaciones
agregar acondicionamiento
agregar guía gratuita del clasificador
agregar unico consecutivo para
incorporar la capacidad de utilizar características intermedias de Hubert como tokens semánticos, recomendado por eonglints
acomodar audio de duración variable, incorporar token eos
Asegúrese de que trabajos consecutivos únicos con transformador grueso
bastante imprimiendo todas las pérdidas del discriminador para registrar
manejar al generar tokens semánticos, que los últimos logits pueden no ser necesariamente los últimos en la secuencia dado un procesamiento consecutivo único
código de muestreo completo para transformadores gruesos y finos, lo cual será complicado
asegúrese de que la inferencia completa con o sin indicaciones funcione en la clase AudioLM
completar el código de entrenamiento completo para soundstream, ocupándose del entrenamiento del discriminador
agregue una penalización de gradiente eficiente para los discriminadores de flujo de sonido
conecte los hz de muestra desde el conjunto de datos de sonido -> transformadores y realice un remuestreo adecuado durante el entrenamiento; piense si permitir que el conjunto de datos tenga archivos de sonido de diferentes hz o aplicar el mismo hz de muestra
código completo de entrenamiento de transformadores para los tres transformadores
refactorizar para que el transformador semántico tenga un contenedor que maneje consecutivos únicos, así como wav a hubert o vq-wav2vec
simplemente no atender automáticamente el token eos en el lado de las indicaciones (semántica para transformador grueso, grueso para transformador fino)
agregar abandono estructurado a partir de un enmascaramiento causal olvidadizo, mucho mejor que los abandonos tradicionales
descubrir cómo suprimir el inicio de sesión en fairseq
afirmar que los tres transformadores pasados a audiolm son compatibles
permitir incrustaciones posicionales relativas especializadas en transformadores finos basadas en posiciones de coincidencia absoluta de cuantificadores entre grueso y fino
permitir vq residual agrupado en el flujo de sonido (use GroupedResidualVQ de vector-quantize-pytorch lib), desde hifi-codec
agregue atención flash con NoPE
acepte la onda principal en AudioLM como ruta a un archivo de audio y remuestreo automático para semántico versus acústico
agregue almacenamiento en caché de clave/valor a todos los transformadores, acelerando la inferencia
diseñar un transformador jerárquico grueso y fino
investigar la decodificación de especificaciones, primero probar en transformadores x, luego transferir si corresponde
rehacer las incrustaciones posicionales en presencia de grupos en vq residual
prueba con síntesis de voz para empezar
herramienta cli, algo así como audiolm generate <wav.file | text> y guarde el archivo wav generado en el directorio local
devolver una lista de ondas en el caso de audio de longitud variable
solo ocúpese del caso límite en el entrenamiento condicionado por texto de transformador aproximado, donde la onda sin procesar se vuelve a muestrear en diferentes frecuencias. determinar automáticamente cómo enrutar según la longitud
@inproceedings { Borsos2022AudioLMAL ,
title = { AudioLM: a Language Modeling Approach to Audio Generation } ,
author = { Zal{'a}n Borsos and Rapha{"e}l Marinier and Damien Vincent and Eugene Kharitonov and Olivier Pietquin and Matthew Sharifi and Olivier Teboul and David Grangier and Marco Tagliasacchi and Neil Zeghidour } ,
year = { 2022 }
} @misc { https://doi.org/10.48550/arxiv.2107.03312 ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco } ,
publisher = { arXiv } ,
url = { https://arxiv.org/abs/2107.03312 } ,
year = { 2021 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @article { Ho2022ClassifierFreeDG ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.12598 }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/rivershavewings }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Liu2022FCMFC ,
title = { FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners } ,
author = { Hao Liu and Xinyang Geng and Lisa Lee and Igor Mordatch and Sergey Levine and Sharan Narang and P. Abbeel } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13432 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Li2021LocalViTBL ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and K. Zhang and Jie Cao and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2104.05707 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @article { Hu2017SqueezeandExcitationN ,
title = { Squeeze-and-Excitation Networks } ,
author = { Jie Hu and Li Shen and Gang Sun } ,
journal = { 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
year = { 2017 } ,
pages = { 7132-7141 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @article { Kazemnejad2023TheIO ,
title = { The Impact of Positional Encoding on Length Generalization in Transformers } ,
author = { Amirhossein Kazemnejad and Inkit Padhi and Karthikeyan Natesan Ramamurthy and Payel Das and Siva Reddy } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.19466 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

