yoloface
1.0.0
YOLOv3 (Solo miras una vez) es un algoritmo de detección de objetos en tiempo real de última generación. El modelo publicado reconoce 80 objetos diferentes en imágenes y vídeos. Para obtener más detalles, puede consultar este documento.
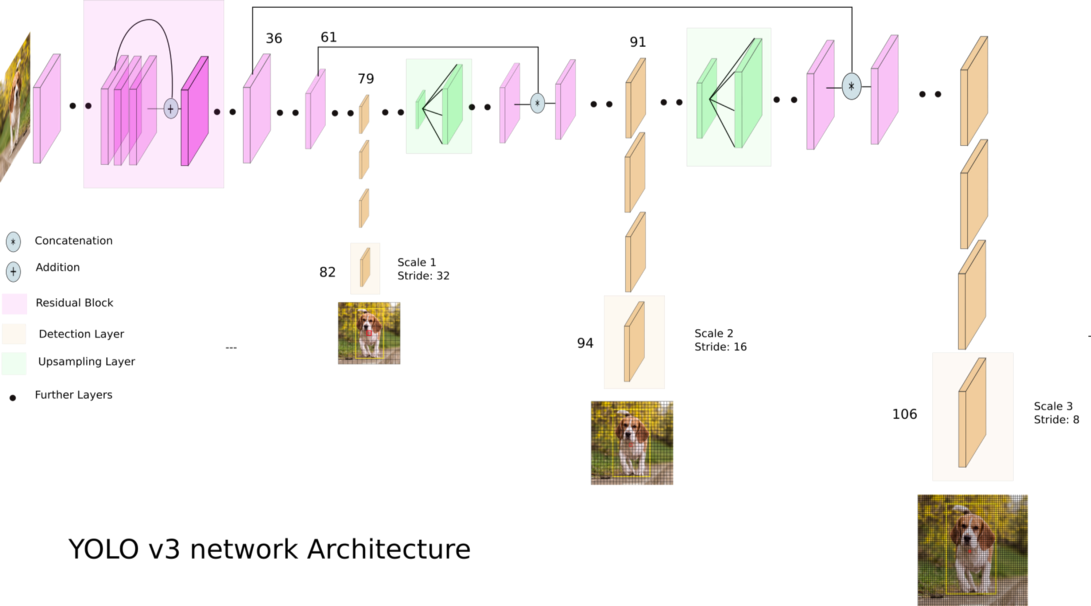
Crédito: Ayoosh Kathuria
El módulo OpenCV dnn admite la ejecución de inferencia en modelos de aprendizaje profundo previamente entrenados de marcos populares como TensorFlow, Torch, Darknet y Caffe.
El desarrollo de este proyecto se realizará aislado en el entorno virtual Python. Esto nos permite experimentar con diferentes versiones de dependencias.
Hay muchas formas de instalar virtual environment (virtualenv) . Consulte la guía Python Virtual Environments: A Primer para diferentes plataformas, pero aquí hay algunas:
$ pip install virtualenv$ pip install --upgrade virtualenvCree un entorno virtual Python 3.6 para este proyecto y active virtualenv:
$ virtualenv -p python3.6 yoloface
$ source ./yoloface/bin/activateA continuación, instale las dependencias para este proyecto:
$ pip install -r requirements.txt$ git clone https://github.com/sthanhng/yoloface Para la detección de rostros, debe descargar el archivo de pesos YOLOv3 previamente entrenado que se entrenó en WIDER FACE: un conjunto de datos de referencia de detección de rostros desde este enlace y colocarlo en el directorio model-weights/ .
Ejecute el siguiente comando:
entrada de imagen
$ python yoloface.py --image samples/outside_000001.jpg --output-dir outputs/entrada de vídeo
$ python yoloface.py --video samples/subway.mp4 --output-dir outputs/cámara web
$ python yoloface.py --src 1 --output-dir outputs/
Este proyecto tiene la licencia MIT; consulte el archivo LICENSE.md para obtener más detalles.


